
물체 한정
물체 한정(Object localization)은 물체를 인식하는 수준을 넘어 물체의 위치를 정확하게 파악하는 것을 의미한다. CCTV 화면에서 자동차, 사람의 테두리에 사각형을 그리는 과정을 생각하면 된다.

물체 한정에서는 물체 주변에 그리는 사각형에 대한 정보들이 필요하다. 다음과 같은 경우를 살펴보자.
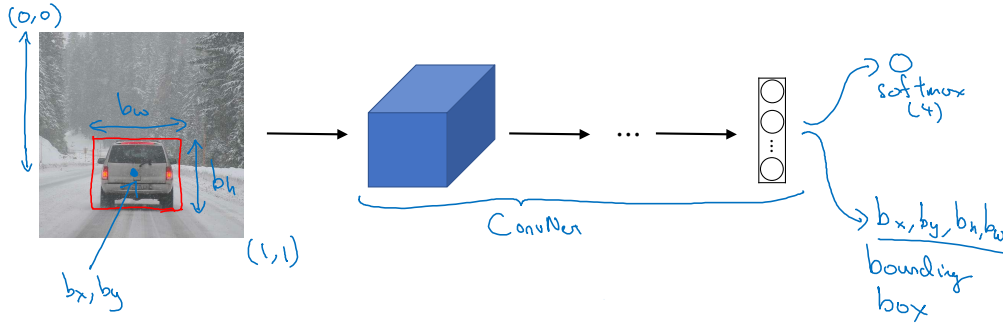
일단 사진에서 왼쪽 가장 위를 $(0, 0)$, 오른쪽 가장 아래를 $(1, 1)$ 이라고 둔다. $b_w, b_h$는 각각 사각형의 너비와 높이, $b_x, b_y$ 는 물체 정중앙의 좌표이다.
사진에 어떤 물체가 등장하는지에 대한 정보도 필요할 것이다. Case 1은 보행자, case 2는 자동차, case 3는 오토바이라고 하고, 앞선 세 가지가 모두 등장하지 않으면 ‘배경화면’이라고 하자.
그럼 위 사진은 아래와 같은 벡터로 나타낼 수 있다.
\[y = \begin{bmatrix} p_c\\ b_x \\ b_y \\ b_h \\ b_w \\ c_1 \\ c_2 \\ c_3 \end{bmatrix} = \begin{bmatrix} 1\\ b_x \\ b_y \\ b_h \\ b_w \\ 0 \\ 1 \\ 0 \end{bmatrix}\]첫 번째 요소인 $p_c$ 는 물체의 등장 여부를 가리킨다. 여기서는 물체가 등장했으므로 1이 된다. 마지막 $c_1, c_2, c_3$ 는 우리 나눈 세 가지 경우 중 어느 것인지를 나타낸다. 자동차가 등장했으므로 c_2가 1이 된 것이다.
다음과 같은 사진이면 어떨까?

물체가 하나도 없는 ‘배경화면’이므로 $p_c$ 는 0이다. 이 경우 나머지 요소들은 상관 없는 값들이 된다.
특징점 탐지
사람의 눈모양이나 역동적인 움직임을 보이는 축구 선수 같은 경우 하나의 지점만으로는 그 전체의 모습을 담아내기 어렵다. 이 경우 여러 개의 특징점(landmark)을 지정해서 모델을 학습시키는 것도 가능하다. 여러 개 특징점 각각의 좌표를 순서대로 구하면 된다.
주의할 것은 지정하는 순서(레이블 순서)는 모든 이미지에서 일정하게 유지해야한다는 점이다. 어떤 사진에서는 팔부터 지정하고, 어떤 사진에서는 다리부터 지정하면 모델이 학습하지 못하는 것은 당연하다.
슬라이딩 윈도우 기법
이제 본격적으로 물체를 인식해보자. 슬라이딩 윈도우(Sliding windows) 기법을 가장 기본적으로 사용한다. 용어 그대로 일정한 크기의 사각형을 이미지 위에 놓고, 이를 옆으로 밀면서 물체가 있는지 없는지를 판별한다. 한 번 사각형을 옮길 때마다 물체의 존재 여부를 신경망 모델을 통해 판단한다.

한 크기의 사각형이 끝나면 사각형의 크기를 좀 더 키워 같은 과정을 반복한다.
사각형을 한 번 옮길 때마다 이를 입력값으로 하여 모델을 사용한다는 지점에서 단점을 발견했어야 한다! 슬라이딩 윈도우는 엄청난 계산을 필요로 하는 기법이다. 이를 해소할 수 있는 방법을 곧 소개한다.
합성곱으로 슬라이딩 윈도우 구현하기
합성곱을 이용하면 앞서 살펴본 슬라이딩 윈도우의 단점을 조금 해결할 수 있다.
핵심은 합성곱 신경망에 등장하는 완전 연결층을 합성곱 층으로 바꾸는 것이다.
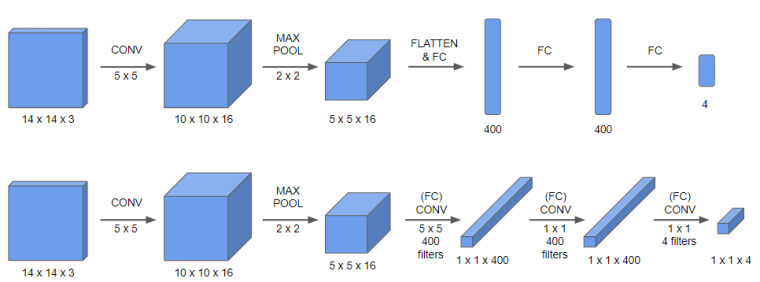
아래 과정에 주목하자. 계산 결과를 벡터로 풀어서 완전 연결층에 넣는 대신 (5 x 5)의 필터를 이용해 합성곱을 진행한다. 이 결과 (1 x 1 x 400)의 결과가 도출된다. 분명 합성곱 층을 통과했는데, 결과는 벡터의 형태와 큰 차이가 없는 것을 알아챌 수 있다. 모양만 그런 것이 아니라, 결과값으로 도출된 400개의 각 값이 (5 x 5 x 16) 크기의 필터에 대한 임의의 선형함수를 구성하고 활성화함수를 통과하기 때문에 수학적으로도 문제가 없다.
슬라이딩 윈도우에서는 다음과 같이 적용한다.
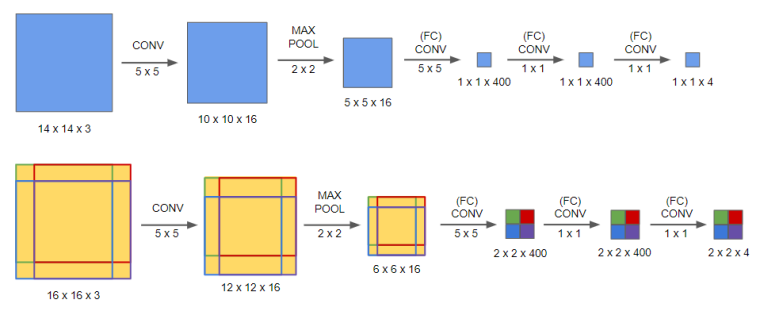
아래 과정을 살펴보자. 윈도우를 슬라이딩해서 4개의 구역이 생긴 상황이다. 마지막을 완전 연결층이 아닌 합성곱 층을 사용하면 4개의 윈도우에 해당하는 구역이 생긴다. 이는 합성곱 층을 4번 통과하지 않고 한 번에 4개의 윈도우에 대한 분류를 할 수 있어 계산 비용이 많이 줄어든다.(각각의 이미지를 신경망에 넣는 대신 계산을 통합해서 한 번에 처리하는 셈이다.)
경계 상자 예측하기
물체의 주변에 경계 상자를 좀 더 잘 그릴 수 있는 방법은 없을까? YOLO(You Only Look Once) 알고리즘을 사용하면 좋다.
먼저 그림을 아래와 같이 9개의 구역으로 나눈다.

그리고 각각의 구역에 대해 ‘물체 한정’에서 배웠던 $y = \begin{bmatrix} p_c\ b_x \ b_y \ b_h \ b_w \ c_1 \ c_2 \ c_3 \end{bmatrix}$ 벡터를 구한다. 이때 물체의 중심 지점이 해당 구역에 들어있는지 여부로 물체의 유무를 판단한다. 예를 들어 가장 왼쪽 가운데 구역은 자동차의 중심점이 있어 $y = \begin{bmatrix} 1\ b_x \ b_y \ b_h \ b_w \ 0 \ 1 \ 0 \end{bmatrix}$ 의 벡터를 가지지만, 정가운데 구역은 자동차의 일부가 있음에도 중심점이 없기 때문에 ‘배경화면’이 된다.
이렇게 구한 9개의 벡터는 (3 x 3 x 8) 의 형태로 놓을 수 있을 것이다(벡터 하나당 요소가 8개이니까). 이를 사전에 레이블 된 정답과 비교하여 신경망을 학습시킬 수 있다.
테스트를 할 때는 이미지를 넣으면 (3 x 3 x 8) 형태의 출력을 얻고, 물체 존재 여부가 1인 벡터의 경계상자 값만 불러와서 경계상자를 그리게 된다.
참고로, $b_x, b_y$는 좌표이므로 0과 1사이의 값을 가진다. 반면, $b_h, b_w$는 해당 구역에서의 비율을 나타내기에, 1보다 클 수도 있다.
실제 YOLO 알고리즘에서는 9개보다 더 많은 구역을 사용한다.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기