
분포의 차이에서 오는 딜레마 상황 해결하기
만약 고양이 인식 프로그램을 일반인에게 서비스하면 저화질의 사진들을 많이 판단하게 될 것이다. 따라서 우리가 모델을 개발하며 사용 해야하면 좋은 예시들은 최상 품질의 인터넷 사진들이 아니고 실제 사용자들이 업로드할 품질의 사진들일 것이다. 그러나 인터넷에서 좋은 사진들을 얻기는 쉬운 반면, 실제 사용자들이 업로드할 사진들은 구하기가 어렵다. 이와 같은 딜레마 상황에서는 어떻게 할까?
인터넷에서 얻은 사진이 200,000개, 사용자들이 업로드한 사진이 10,000개라고 해보자.
한 가지 방법은 두 가지 사진들을 모두 적절히 섞어 training set, dev set, test set으로 나누는 것이다. 이 경우 210,000개의 사진 중에 이상적인 사진은 10,000개가 포함되어 있다. Dev set과 test set의 크기를 각각 2,500이라고 했을 때, 같은 기댓값으로 섞여 들어갈테니 사용자가 업로드한 사진들은 각각 119개쯤 있겠다. 모든 사진을 섞어서 재분배하는 것은 가장 손쉬운 방법이지만 dev set과 test set이 우리가 기대하는 것과는 전혀 다른 분포를 가진다는 치명적인 단점이 있다.
다른 방법은 두 종류의 사진을 모두 사용하되, 의도적인 분배를 하는 것이다. Dev set, test set에는 모두 업로드한 사진을 배치하고, 나머지 사진들은 모두 training set으로 넣는다. 이렇게 하면 training set과 dev/test set의 분포는 좀 달라지겠지만, 우리가 원하는 결과에 조금 더 가까운 모델이 된다. 장기적으로는 이 방법이 훨씬 낫다.
데이터 불일치 문제 판별하기
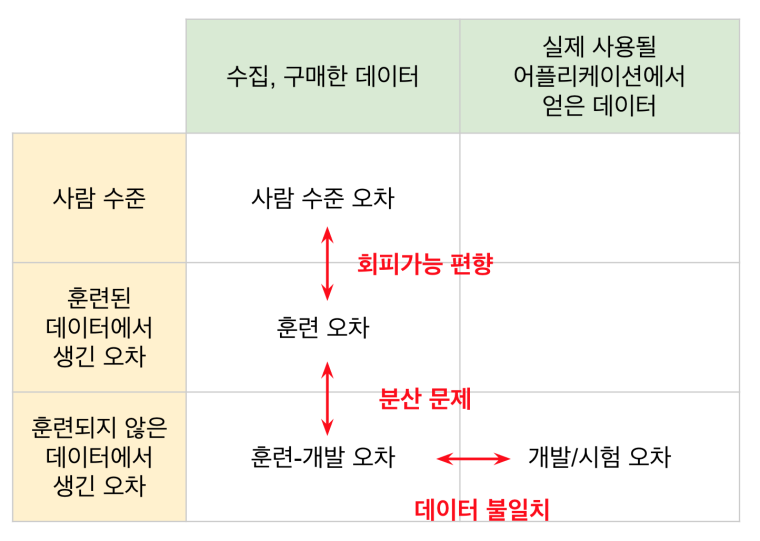
앞서 training set과 dev set의 분포가 다른 상황(a.k.a. 데이터 불일치 문제)에서, 오차의 원인을 분석하기 위해 training 오차와 dev 오차를 파악해보았다고 해보자. Training 오차는 1%, dev 오차는 10%가 도출되었다. 회피 가능 편향보다 분산이 크니, 이 모델은 분산을 줄이는 방향으로 개선하면 될까? Training set과 dev set의 분포 차이에서 오는 문제는 진정 없는 것일까?
Training set과 dev set의 분포 차이에서 오는 문제를 파악하기 위해서는 'Training-Dev set'이라는 개념을 도입해야 한다. 이 집합은 training set과는 동일한 분포를 가지되, 훈련에는 사용되지 않은 집합이다. Training-Dev set과 Dev set의 오차 차이는 집합 분포 차이에서 비롯되는 것이므로, Training-Dev set 오차를 살펴보면 어디서 문제가 생긴 것인지 파악할 수 있다.
| 오차 종류 | Case 1 | Case 2 | Case 3 | Case 4 |
|---|---|---|---|---|
| 인간 수준 오차 | 0% | 0% | 0% | 0% |
| Training 오차 | 1% | 1% | 10% | 10% |
| Training-Dev 오차 | 9% | 1.5% | 11% | 11% |
| Dev 오차 | 10% | 10% | 12% | 20% |
Case 1에서는 분포 차이에 의한 오차보다 분산이 더 크다. 반면 Case 2에서는 training set과 dev set의 분포 차이가 성능에 큰 영향을 미치고 있음을 알 수 있다. Case 3에서는 회피 가능 편향이 영향을 미치고, Case 4에서는 회피 가능 편향, 분포 차이가 종합적으로 영향을 미치고 있다.
이처럼 Training-Dev set을 도입하면 모델의 성능 저하가 training set과 dev set의 분포 차이에서 오는 것인지 판단할 수 있다. 아래 그림으로 정리하자.
데이터 불일치 문제 해결하기
앞선 단락에서 제시되었던 데이터 불일치 문제를 해결하기 위해서는 먼저 오차 분석을 해야한다. 오차 분석으로 training set과 dev/test set의 분포가 다른 이유를 이해해야 한다.
다음으로는 training set의 데이터를 dev/test set의 것과 비슷하도록 만들어야 한다. 데이터를 더 수집하는 방법도 물론 좋겠지만, 여의치 않을 경우 데이터를 인공적으로 생성할 수도 있다!
자동차 네비게이션의 음성인식 프로그램을 만든다고 해보자. 우리가 원하는 것은 자동차 안에서 이루어진 대화의 녹음 파일이지만, 그 데이터가 너무 적은 상황이다. 이 경우 일상생활에서 이루어진 대화의 녹음 파일에 자동차 소음을 입히는 방식으로 데이터를 생성할 수 있다.
평범한 대화 + 자동차 소음 = 자동차 안에서의 대화
이러한 방법을 이용하면 우리가 원하는 것과 비슷한 데이터를 매우 많이(거의 무한으로) 얻을 수 있을 것이다. 실제로 모델을 만들 때도 많이 사용하는 방법이다.
그러나 주의해야할 점이 있다. 위의 합성 과정에서 동일한 자동차 소음 소리만을 반복적으로 이용하게 되면 전체 데이터(자동차 안에서의 대화)에 비해 매우 일부의 데이터(특정 자동차 소음에서 이루어진 대화)만을 얻게 될 것이다. 데이터가 많아진다고 마냥 좋아할 것이 아니라 이러한 단점도 있다는 사실을 인지해야 한다.
모든 이미지는 네이버 부스트코스에서 발췌하였음을 밝힙니다.
댓글남기기