
Train, Dev, Test set
앞선 코스의 마지막 부분에서 좋은 Hyperparameter를 선정하기 위해서는 많은 시행착오가 필요하다고 하였다. 적절한 hyperparameter 선정 과정을 효율적으로 진행하기 위해서는 데이터를 적절히 나누는 것이 중요하다.
데이터는 보통 Train set, Dev set, Test set의 세가지로 분류한다. Train set은 말 그대로 모델을 훈련하기 위한 데이터 집합이다. Dev set은 train set으로 훈련한 모델을 발전시키기 위한 교차검증을 실시하는 집합이다. 마지막으로 Test set은 이렇게 개발한 모델을 테스트하기 위한 집합이다.
데이터의 숫자가 많지 않았던 과거에는 train set과 test set을 70%, 30%의 비율로 나누거나 train set, dev set, test set을 각각 60%, 20%, 20%의 비율로 나누곤 했다. 이는 특별한 이유가 있는 비율이라기 보다는 그저 경험에서 우러난 비율이었다.
하지만 현대 빅데이터 시대에는 더 이상 이렇게 나누지 않는다. Dev set에서는 2~10개의 알고리즘 후보 중 가장 좋은 것만을 선택하면 되고, test set에서는 모델의 성능 평가만 진행하면 된다. 따라서 전체 중 98%의 데이터를 train set으로 이용하고, 1%씩 만을 dev set, test set으로 하여도 무방하다. 심지어 1,000,000개 보다 더 많은 데이터에서는 dev set과 test set의 비율을 줄여도 된다!
그리고 train과 test set을 선택할 때는 같은 분포를 가진 집단에서 선택하는 것이 좋다. 예를 들어, 사진을 인식해 고양이인지를 판단하는 모델을 제작하기 위해 train set으로는 웹사이트에 업로드 된 사진을, dev와 test set에서는 사용자가 업로드할 사진을 이용한다고 가정해보자. 웹사이트의 사진들은 엄선된 사진이므로 좋은 품질을 가진 반면, 사용자가 업로드하는 사진들은 품질이 영 별로일 것이다. 이 경우 모델을 제대로 검증하였다고 볼 수 없다. 따라서 train set과 test set은 같은 분포를 가진 집단에서 선택해야 한다.
가끔 test set이 없는 경우도 있다. 비편향 추정이 필요하지 않는 경우인데, 이럴 때는 dev set만 있어도 무방하긴 하다.(dev test와 test set을 부르는 용어가 바뀔 수도 있다. 크게 신경쓰지는 말자.)
편향(Bias)과 분산(Variance)
만약 2가지 특성을 가진 데이터를 구분하는 학습을 진행하였다고 해보자. 아래 그림과 같은 결과들이 도출될 수 있다.
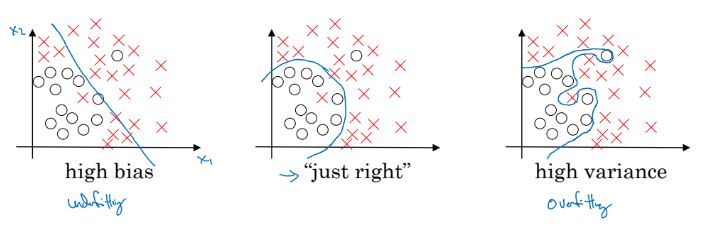
먼저, 가장 왼쪽은 높은 편향(high bias)을 가지고 있다고 말한다. 오답 데이터를 너무 많이 포함하고 있다. 학습 데이터에 적합(fit)하지 않다는 의미로 underfitting이라고 부르기도 한다.
가장 오른쪽 그림은 높은 분산(high variance)을 가지고 있다고 말한다. 과할 정도로 복잡하게 정답 데이터를 구분해내고 있다. 학습 데이터에 너무 과하게 최적되었다는 의미로 overfitting이라고 한다.
가운데 그림이 가장 적절해 보인다. 너무 과하게 최적화되지도 않았고, 정답들을 적절히 추려내고 있다.
이처럼 2차원에서는 시각화를 통해 편향과 분산을 가려낼 수 있다. 하지만 고차원에서는 시각화로 하는 것이 불가능하기에 다른 방안을 제안한다.
오차율을 통해 편향과 분산 가려내기
Train set과 Dev set의 오차율을 통해 편향과 분산을 가려낼 수 있다. 아래 예시를 보자.
| 집합 종류 | Case 1 | Case 2 | Case 3 | Case 4 |
|---|---|---|---|---|
| Train set error | 1% | 15% | 15% | 0.5% |
| Dev set error | 11% | 16% | 30% | 1% |
Case 1에서는 train set에서는 오차율이 낮은 반면, dev set에서는 오차율이 비교적 매우 커진다. 높은 분산을 가진, 과적합 상황이라는 것을 알 수 있다.
Case 2에서는 train set과 dev set의 오차율이 비슷하지만, 둘 다 만족스러울 정도로 오차율이 낮진 않다. 높은 편향을 가진 상황으로 볼 수 있다.
Case 3에서는 train set의 오차율이 높고, dev set의 오차율을 훨씬 더 높다. 높은 편향과 분산을 모두 가진 상태로, 최악의 경우이다.
Case 4는 두 집합 모두 오차율이 낮다. 낮은 편향과 분산을 가진 상태로, 최적의 상황이다.
이 모든 분석은 인간이 분류했을 때의 오차, 다른 말로 Bayes error가 0%에 가까울 때를 가정한 것이다. 최적의 오류가 달라진다면 분석 결과가 달라질 수 있다.
어쨌든 중요한 것은, train set의 오차율과 dev set의 오차율을 비교하여 편향과 분산을 파악할 수 있다는 것이다.
머신러닝에 대한 기본적인 레시피
머신러닝 모델을 평가하는 요소들을 자세히 살펴보았다. 그럼 어떤 과정을 거쳐 모델을 평가하고 수정해야할까?
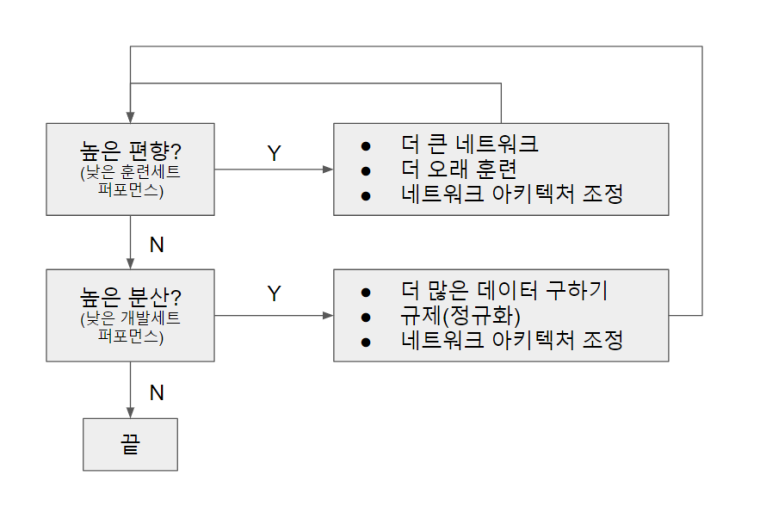
먼저, 높은 편향을 가지는지를 파악한다. 만약 그렇다면, 더 큰 신경망을 이용하거나 학습 시간을 늘려서 문제를 해결할 수도 있다. 다른 신경망 아키텍처를 탐색하는 것도 도움이 될 수 있다.
이를 만족한다면 높은 분산을 가지는지 판단한다. 높은 분산을 가진다면 더 많은 데이터를 이용하거나 정규화(Regularization)을 통해 문제를 해결할 수 있다. 높은 편향을 고칠 때와 마찬가지로 다른 신경망 아키텍처를 탐색하는 것도 도움이 될 수 있다.
어떤 요소를 수정하기 위해 어떠한 방식을 취해야 하는지를 아는 것은 매우 중요하다. 예를 들어 높은 편향을 해결하려고 하는데 더 많은 데이터를 가져오는 것은 전혀 도움이 되지 않는다.
편향-분산 거래(Bias-variance Tradeoff)
편향-분산 거래는 편향을 줄이려면 분산을 희생하고, 분산을 줄이려면 편향을 희생할 수밖에 없다는 딜레마를 지칭하는 용어이다. 과거에는 잘 적용되었지만, 현대의 딥러닝에서는 편향 혹은 분산만을 줄이는 것이 가능해지면서 잘 적용되지는 않는다.
다만, 분산을 줄이기 위한 정규화를 하면 편향을 어느 정도 희생해야 하기 때문에 정규화에서는 들어 맞기도 한다.
별도의 출처가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기