
이번 시간에는 Pandas의 다양한 기능에 대해 공부한다.
Pandas
Pandas(판다스)는 구조화된 데이터를 처리하는 파이썬 라이브러리이다. 쉽게 생각해서 파이선계의 엑셀이라고 보면 된다. 넘파이의 다양한 기능도 포함하고 있다.
데이터 불러오기
판다스로 데이터를 불러오는 과정은 다음과 같다.
>>> import pandas as pd
>>> data_url = "https://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data"
>>> df_data = pd.read_csv(data_url, sep = "\s+", header = None)
>>> df_data.head()
0 1 2 3 4 5 6 7 8 9 10 11 12 13
0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222.0 18.7 396.90 5.33 36.2
판다스의 구성
판다스의 구성은 다음과 같다.
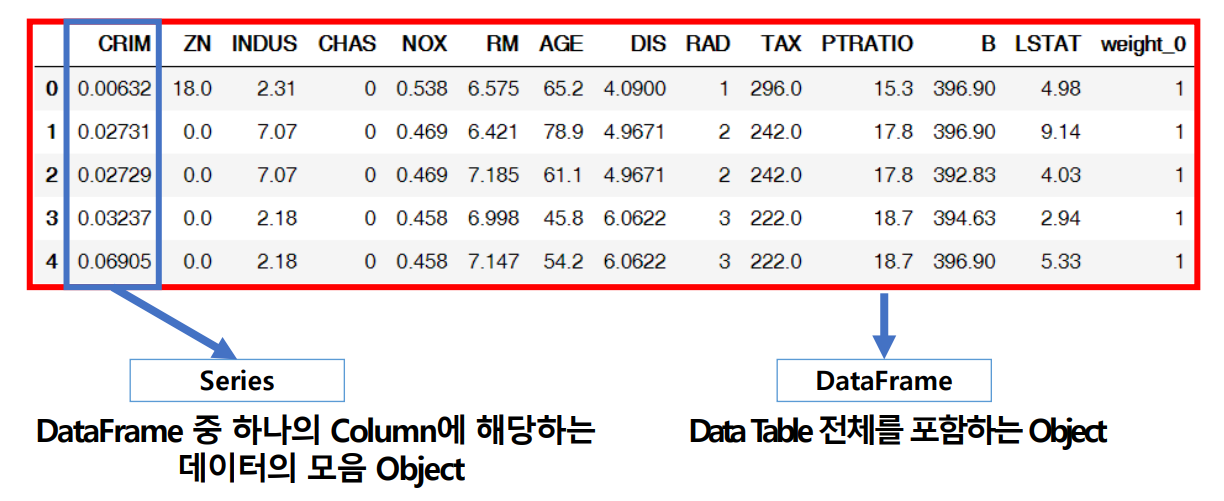
Dataframe은 전체 데이터를 의미한다. Series는 Dataframe 중 하나의 열에 해당하는 데이터의 모음이다.
Series 다루기
Series를 만드는 방법을 알아보자.
>>> from pandas import Series, DataFrame
>>> import pandas as pd
>>> list_data = [1, 2, 3, 4, 5]
>>> example_Obj = Series(data = list_data)
>>> example_Obj
0 1
1 2
2 3
3 4
4 5
dtype: int64
Series는 위에서 보이는 것처럼 인덱스(index)와 값(value)으로 나누어져 있다. 인덱스의 이름을 지정하는 것도 가능하다.
>>> list_data = [1, 2, 3, 4, 5]
>>> list_name = ['a', 'b', 'c', 'd', 'e']
>>> example_obj = Series(data = list_data, index = list_name)
>>> example_obj
a 1
b 2
c 3
d 4
e 5
데이터에 접근하는 방법과 데이터 인덱스에 값을 할당하는 방법은 다음과 같다.
>>> example_obj['a'] # 데이터에 접근
1
>>> example_obj['a'] = 32 # 데이터 값 할당
>>> example_obj
a 32
b 2
c 3
d 4
e 5
dtype: int64
다음과 같이 딕셔너리를 이용해 Series를 만드는 것도 가능하다.
>>> dict_data_1 = {'a': 1, 'b': 2, 'c': 3, 'd':4, 'e':5}
>>> series_obj = Series(dict_data_1)
>>> series_obj
a 1
b 2
c 3
d 4
e 5
dtype: int64
Dataframe 다루기 (기본)
Dataframe은 그냥 행렬이라고 생각하면 된다. Dataframe을 아예 바닥부터 만드는 방법은 다음과 같다.
>>> raw_data = {'first_name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
... 'last_name': ['Miller', 'Jacobson', 'Ali', 'Milner', 'Cooze'],
... 'age': [42, 52, 36, 24, 73],
... 'city': ['San Francisco', 'Baltimore', 'Miami', 'Douglas', 'Boston']}
>>> df = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city'])
>>> df
first_name last_name age city
0 Jason Miller 42 San Francisco
1 Molly Jacobson 52 Baltimore
2 Tina Ali 36 Miami
3 Jake Milner 24 Douglas
4 Amy Cooze 73 Boston
열을 선택하거나 추가할 수도 있다.
>>> DataFrame(raw_data, columns = ['age', 'city'])
age city
0 42 San Francisco
1 52 Baltimore
2 36 Miami
3 24 Douglas
4 73 Boston
>>> DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city', 'debt'])
first_name last_name age city debt
0 Jason Miller 42 San Francisco NaN
1 Molly Jacobson 52 Baltimore NaN
2 Tina Ali 36 Miami NaN
3 Jake Milner 24 Douglas NaN
4 Amy Cooze 73 Boston NaN
새로 생긴 열은 NaN으로 지정되는 것을 확인할 수 있다.
열을 지정해서 Series로 추출해보자. 두 가지 방법이 있다.
>>> df = DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'city', 'debt'])
>>> df.first_name
0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
>>> df['first_name']
0 Jason
1 Molly
2 Tina
3 Jake
4 Amy
Name: first_name, dtype: object
이제 좀 헷갈리는 부분이다. loc과 iloc의 작동 방식을 보자.
>>> df.loc[1]
first_name Molly
last_name Jacobson
age 52
city Baltimore
debt NaN
Name: 1, dtype: object
>>> df['age'].iloc[1:]
1 52
2 36
3 24
4 73
Name: age, dtype: int64
loc은 인덱스의 이름을 받아서 반환한다. 반면, iloc은 인덱스의 위치를 받아서 반환한다. 다음 예시를 보면 차이가 좀 더 잘 보일 것이다.
>>> import numpy as np
>>> s = pd.Series(np.nan, index=[49,48,47,46,45, 1, 2, 3, 4, 5])
>>> s
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
dtype: float64
>>> s.loc[:3]
49 NaN
48 NaN
47 NaN
46 NaN
45 NaN
1 NaN
2 NaN
3 NaN
dtype: float64
>>> s.iloc[:3]
49 NaN
48 NaN
47 NaN
dtype: float64
loc을 호출하면 인덱스의 이름을 기준으로, iloc은 인덱스의 위치를 기준으로 반환하는 것을 확인할 수 있다.
Boolean으로 열에 새로운 데이터를 할당하는 방법을 알아보자. 다음과 같은 방법은 아주 많이 사용한다.
>>> df.debt = df.age > 40
>>> df
first_name last_name age city debt
0 Jason Miller 42 San Francisco True
1 Molly Jacobson 52 Baltimore True
2 Tina Ali 36 Miami False
3 Jake Milner 24 Douglas False
4 Amy Cooze 73 Boston True
나이 열을 기준으로 해서 debt 행에 새로운 값을 부여했다.
행을 삭제할 때는 del을 사용한다.
>>> del df['debt']
>>> df
first_name last_name age city
0 Jason Miller 42 San Francisco
1 Molly Jacobson 52 Baltimore
2 Tina Ali 36 Miami
3 Jake Milner 24 Douglas
4 Amy Cooze 73 Boston
딕셔너리를 이용해 Dataframe을 만들 수도 있다.
>>> pop = {'Nevada': {2001: 2.4, 2002: 2.9}, 'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
>>> DataFrame(pop)
Nevada Ohio
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.5
Dataframe 다루기 (심화)
다양한 열을 선택하는 방법은 다음과 같다.
>>> df.head()
account name street city state postal-code Jan Feb Mar
0 211829 Kerluke, Koepp and Hilpert 34456 Sean Highway New Jaycob Texas 28752 10000 62000 35000
1 320563 Walter-Trantow 1311 Alvis Tunnel Port Khadijah NorthCarolina 38365 95000 45000 35000
2 648336 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231 New Lilianland Iowa 76517 91000 120000 35000
3 109996 DAmore, Gleichner and Bode 155 Fadel Crescent Apt. 144 Hyattburgh Maine 46021 45000 120000 10000
4 121213 Bauch-Goldner 7274 Marissa Common Shanahanchester California 49681 162000 120000 35000
>>> df[["account", "street", "state"]].head(3)
account street state
0 211829 34456 Sean Highway Texas
1 320563 1311 Alvis Tunnel NorthCarolina
2 648336 62184 Schamberger Underpass Apt. 231 Iowa
열의 이름 없이 사용하는 인덱스 숫자는 행을 기준으로 표시한다.
>>> df[:10]
account name street city state postal-code Jan Feb Mar
0 211829 Kerluke, Koepp and Hilpert 34456 Sean Highway New Jaycob Texas 28752 10000 62000 35000
1 320563 Walter-Trantow 1311 Alvis Tunnel Port Khadijah NorthCarolina 38365 95000 45000 35000
2 648336 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231 New Lilianland Iowa 76517 91000 120000 35000
3 109996 DAmore, Gleichner and Bode 155 Fadel Crescent Apt. 144 Hyattburgh Maine 46021 45000 120000 10000
4 121213 Bauch-Goldner 7274 Marissa Common Shanahanchester California 49681 162000 120000 35000
5 132971 Williamson, Schumm and Hettinger 89403 Casimer Spring Jeremieburgh Arkansas 62785 150000 120000 35000
6 145068 Casper LLC 340 Consuela Bridge Apt. 400 Lake Gabriellaton Mississipi 18008 62000 120000 70000
7 205217 Kovacek-Johnston 91971 Cronin Vista Suite 601 Deronville RhodeIsland 53461 145000 95000 35000
8 209744 Champlin-Morar 26739 Grant Lock Lake Juliannton Pennsylvania 64415 70000 95000 35000
9 212303 Gerhold-Maggio 366 Maggio Grove Apt. 998 North Ras Idaho 46308 70000 120000 35000
반면 열의 이름을 지정해주면 해당 열에 대해서만 추출한다.
>>> df["name"][:3]
0 Kerluke, Koepp and Hilpert
1 Walter-Trantow
2 Bashirian, Kunde and Price
Name: name, dtype: object
Series로 선택할 수도 있다. 또, 이를 이용해 Boolean으로 추출할 수도 있다.
>>> account_serires = df["account"]
>>> account_serires[:3]
0 211829
1 320563
2 648336
Name: account, dtype: int64
>>> account_serires[account_serires<250000]
0 211829
3 109996
4 121213
5 132971
6 145068
7 205217
8 209744
9 212303
10 214098
11 231907
12 242368
Name: account, dtype: int64
기본적으로 숫자로 지정된 인덱스를 변경해줄 수도 있다.
>>> df.index = df["account"]
>>> df.head()
account name street city state postal-code Jan Feb Mar
account
211829 211829 Kerluke, Koepp and Hilpert 34456 Sean Highway New Jaycob Texas 28752 10000 62000 35000
320563 320563 Walter-Trantow 1311 Alvis Tunnel Port Khadijah NorthCarolina 38365 95000 45000 35000
648336 648336 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231 New Lilianland Iowa 76517 91000 120000 35000
109996 109996 D'Amore, Gleichner and Bode 155 Fadel Crescent Apt. 144 Hyattburgh Maine 46021 45000 120000 10000
121213 121213 Bauch-Goldner 7274 Marissa Common Shanahanchester California 49681 162000 120000 35000
기존의 열을 제거하고 생기는 것이 아니기 때문에 del로 제거해주면 깔끔하다.
행과 열을 이용해 데이터를 추출하는 방법은 다음과 같이 다양하다.
>>> df[["name","street"]][:2] # 열과 인덱스 숫자 이용
name street
account
211829 Kerluke, Koepp and Hilpert 34456 Sean Highway
320563 Walter-Trantow 1311 Alvis Tunnel
>>> df.loc[[211829,320563],["name","street"]] # 열의 숫자와 인덱스 숫자 이용
name street
account
211829 Kerluke, Koepp and Hilpert 34456 Sean Highway
320563 Walter-Trantow 1311 Alvis Tunnel
>>> df[["name", "street"]].iloc[:10] # 열과 인덱스 이름 이용
name street
account
211829 Kerluke, Koepp and Hilpert 34456 Sean Highway
320563 Walter-Trantow 1311 Alvis Tunnel
648336 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231
109996 DAmore, Gleichner and Bode 155 Fadel Crescent Apt. 144
121213 Bauch-Goldner 7274 Marissa Common
132971 Williamson, Schumm and Hettinger 89403 Casimer Spring
145068 Casper LLC 340 Consuela Bridge Apt. 400
205217 Kovacek-Johnston 91971 Cronin Vista Suite 601
209744 Champlin-Morar 26739 Grant Lock
212303 Gerhold-Maggio 366 Maggio Grove Apt. 998
인덱스를 재설정할 수도 있다.
>>> df.index = list(range(0,15))
>>> df.head()
name street city state postal-code Jan Feb Mar
0 Kerluke, Koepp and Hilpert 34456 Sean Highway New Jaycob Texas 28752 10000 62000 35000
1 Walter-Trantow 1311 Alvis Tunnel Port Khadijah NorthCarolina 38365 95000 45000 35000
2 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231 New Lilianland Iowa 76517 91000 120000 35000
3 D'Amore, Gleichner and Bode 155 Fadel Crescent Apt. 144 Hyattburgh Maine 46021 45000 120000 10000
4 Bauch-Goldner 7274 Marissa Common Shanahanchester California 49681 162000 120000 35000
drop을 이용하면 행을 제거할 수 있다.
>>> df.drop(1)
name street city state postal-code Jan Feb Mar
0 Kerluke, Koepp and Hilpert 34456 Sean Highway New Jaycob Texas 28752 10000 62000 35000
2 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231 New Lilianland Iowa 76517 91000 120000 35000
3 DAmore, Gleichner and Bode 155 Fadel Crescent Apt. 144 Hyattburgh Maine 46021 45000 120000 10000
4 Bauch-Goldner 7274 Marissa Common Shanahanchester California 49681 162000 120000 35000
5 Williamson, Schumm and Hettinger 89403 Casimer Spring Jeremieburgh Arkansas 62785 150000 120000 35000
6 Casper LLC 340 Consuela Bridge Apt. 400 Lake Gabriellaton Mississipi 18008 62000 120000 70000
7 Kovacek-Johnston 91971 Cronin Vista Suite 601 Deronville RhodeIsland 53461 145000 95000 35000
8 Champlin-Morar 26739 Grant Lock Lake Juliannton Pennsylvania 64415 70000 95000 35000
9 Gerhold-Maggio 366 Maggio Grove Apt. 998 North Ras Idaho 46308 70000 120000 35000
10 Goodwin, Homenick and Jerde 649 Cierra Forks Apt. 078 Rosaberg Tenessee 47743 45000 120000 55000
11 Hahn-Moore 18115 Olivine Throughway Norbertomouth NorthDakota 31415 150000 10000 162000
12 Frami, Anderson and Donnelly 182 Bertie Road East Davian Iowa 72686 162000 120000 35000
13 Walsh-Haley 2624 Beatty Parkways Goodwinmouth RhodeIsland 31919 55000 120000 35000
14 McDermott PLC 8917 Bergstrom Meadow Kathryneborough Delaware 27933 150000 120000 70000
행은 물론이고 축을 지정해서 열을 제거할 수도 있다.
>>> df.drop("city",axis=1).head()
name street state postal-code Jan Feb Mar
0 Kerluke, Koepp and Hilpert 34456 Sean Highway Texas 28752 10000 62000 35000
1 Walter-Trantow 1311 Alvis Tunnel NorthCarolina 38365 95000 45000 35000
2 Bashirian, Kunde and Price 62184 Schamberger Underpass Apt. 231 Iowa 76517 91000 120000 35000
3 DAmore, Gleichner and Bode 155 Fadel Crescent Apt. 144 Maine 46021 45000 120000 10000
4 Bauch-Goldner 7274 Marissa Common California 49681 162000 120000 35000
삭제를 하더라도 기존 데이터는 변하지 않는다. 기존 데이터도 바뀌기를 원하면 inplace=True로 설정해야 한다.
Dataframe 연산
Dataframe을 합하면 인덱스를 기준으로 연산을 하고, 겹치는 인덱스가 없으면 NaN을 반환한다.
>>> s1 = Series(range(1,6), index=list("abced"))
>>> s1
a 1
b 2
c 3
e 4
d 5
dtype: int64
>>> s2 = Series(range(5,11), index=list("bcedef"))
>>> s2
b 5
c 6
e 7
d 8
e 9
f 10
dtype: int64
>>> s1 + s2
a NaN
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f NaN
dtype: float64
다만 다음처럼 NaN 값을 없앨 수도 있다.
>>> s1.add(s2, fill_value = 0)
a 1.0
b 7.0
c 9.0
d 13.0
e 11.0
e 13.0
f 10.0
dtype: float64
Series와 Dataframe을 합하면 broadcasting이 일어난다.
람다 함수, map, apply
판다스에서도 람다 함수, map을 사용할 수 있다. 간단한 활용 예시를 보자.
>>> s1 = Series(np.arange(10))
>>> s1.head(5)
0 0
1 1
2 2
3 3
4 4
dtype: int64
>>> s1.map(lambda x: x**2).head(5)
0 0
1 1
2 4
3 9
4 16
dtype: int64
데이터를 우리가 원하는 형식으로 변환할 때 유용하게 사용할 수 있다.
>>> z = {1: 'A', 2: 'B', 3: 'C'}
>>> s1.map(z).head(5)
0 NaN
1 A
2 B
3 C
4 NaN
dtype: object
>>> s2 = Series(np.arange(10, 20))
>>> s1.map(s2).head(5)
0 10
1 11
2 12
3 13
4 14
dtype: int64
replace는 map함수의 기능 중에 데이터 변환의 기능만 담당한다. 데이터 변환 시에 많이 사용한다.
apply는 map과 달리 series 전체에 함수를 적용한다.
applymap은 series 단위가 아닌 요소 단위로 함수를 적용한다.
판다스 built-in 함수
대표적인 판다스 built-in 함수는 descibe가 있다. 데이터의 요약 정보를 보여준다.
>>> df.descibe()
unique는 series에서 유일한 값의 리스트를 반환한다.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기