몬테 카를로 시뮬레이션으로 매우 임의 표본을 생성하고 신뢰 구간을 계산할 수 있다. 그러나 선거 여론 조사처럼 매우 표본을 추출할 수 없는 상황이라면 어떻게 할까?
층화추출
층화추출은 모집단을 작은 집단으로 분할하고, 각 소집단으로부터 단순임의추출을 하는 것을 의미한다. 대표되어야 할 소집단들이 있을 때, 소집단들이 그 크기에 비례하여 대표되는 것이 중요할 때 필요한 표본의 크기를 줄일 수 있다.
예를 들어, 대학교에 다니는 학생 중 컴퓨터 괴짜인 학생을 조사한다고 해보자. 그냥 무작위로 학생을 붙잡고 조사를 하면 그 학생의 전공이 무엇인지에 따라 결과가 달라질 수 있기 때문에 정확한 결과를 얻기 힘들다. 조사를 할 때마다 결과가 다르게 나올 가능성이 높으며, 통계 조사의 의미가 없게 된다. 이때 학과별로 나누어서 조사를 한다면 무작위 추출의 단점을 보완할 수 있다.
신뢰구간 줄이기
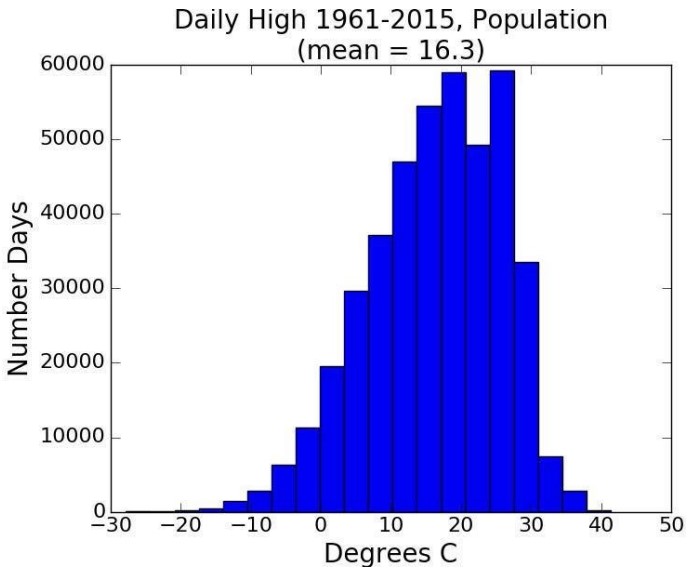
교수님은 미국 기상 데이터로 설명을 이어간다. 날마다의 최고 기온을 정리한 데이터 전체를 활용해 히스토그램을 그리면 다음과 같은 결과가 나온다.
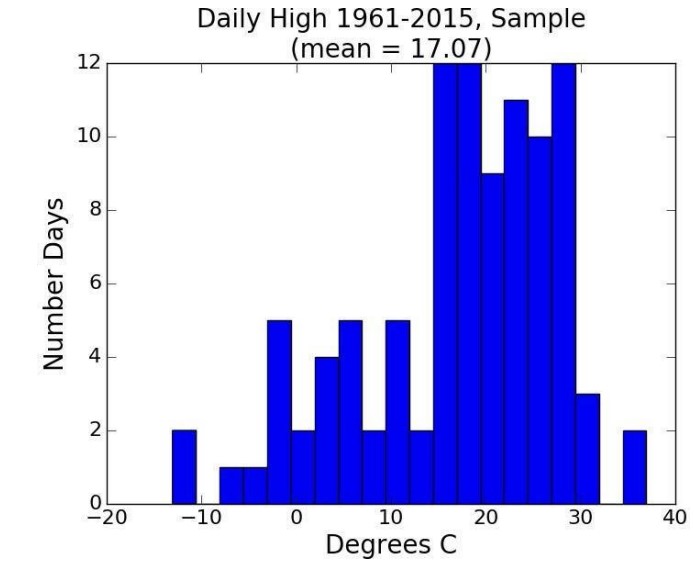
임의로 크기가 100인 히스토그램 표본을 추출하여 히스토그램을 그리면 아래와 같다.
모양은 좀 다르지만 평균과 표준편차가 유사하다. 1000번을 실행하면 어떨까?
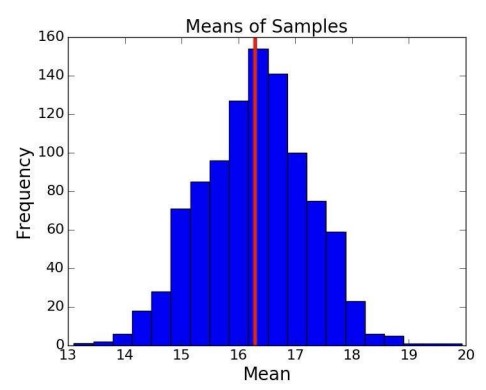
정규분포에 유사한 모양이 나왔다. 95% 신뢰구간은 14.5 ~ 18.1을 기록하였다. 모평균을 포함하기는 하지만, 너무 넓다. 범위를 좁히려면 어떻게 해야할까?
표본 추출 횟수를 늘리면 어떨까? 애석하게도 횟수를 2000으로 늘려봤자 거의 변화가 없다.
그럼 표본을 더 크게 하면 어떨까? 표본의 크기를 200으로 늘리면 표준편차가 매우 감소한다.
즉, 표본을 크게하는 것이 가장 효과적으로 신뢰구간을 좁힐 수 있는 방법이다!
cf. 에러바
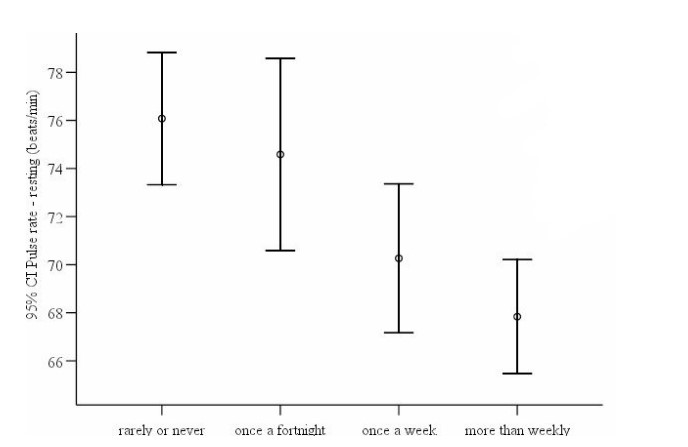
에러바는 데이터의 변이성을 나타내는 그래프로, 불확실성을 시각화하는 방법이다.
위 그림에서 선의 범위가 곧 신뢰구간을 나타낸다고 보면 된다. 각각의 선의 범위가 겹친다면 통계적으로 큰 의미가 없다고 판단한다. 범위가 겹치지 않는 선 만이 통계적으로 매우 다르다고 할 수 있다.
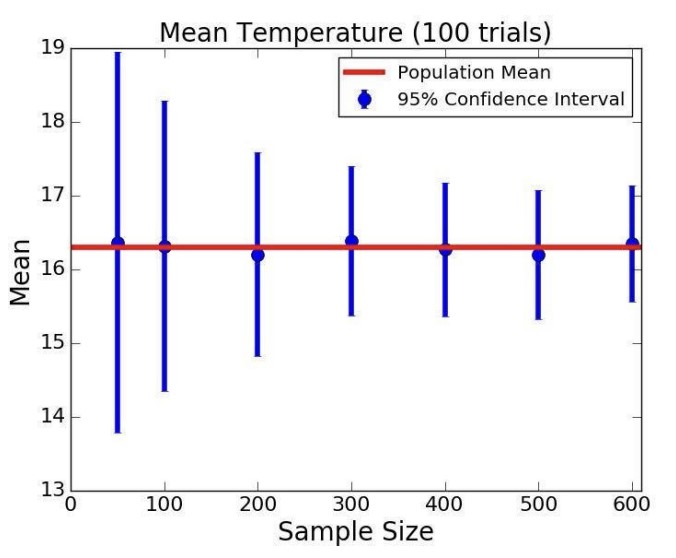
기온 데이터의 에러바를 살펴보자.
표본의 크기가 커질수록 신뢰구간이 점점 좁아지는 것을 볼 수 있다.
그러나 주의해야 한다. 표본을 신나게 키우다가 원래 모집단의 크기와 같아질 수 있다! 뭐든 적당한 것이 좋다.
표준편차와 표준오차
중심극한정리에 의해, 1개의 표본에서도 여러 표본들의 평균의 표준편차를 추정할 수 있다. 중심극한정리를 다시 보자.
표본 집합에 있는 표본들의 평균(표본평균, 표본들의 평균이지 전체의 평균이 아니다!)은 거의 정규분포를 따른다.
이 정규분포의 평균은 모집단의 평균(전체의 평균)에 가깝다.
표본평균은 분산은 모집단의 분산을 표본의 크기로 나눈 값에 가깝다.
마지막 특성을 사용하여 평균의 표준오차를 계산하고, 표준오차를 이용해 평균의 표준편차를 추정할 수 있다.
표준오차는 다음과 같이 구한다.
\[SE=\frac{\sigma}{n}\]
$\sigma$는 모집단의 표준편차를 의미하고, n은 표본의 크기를 말한다.
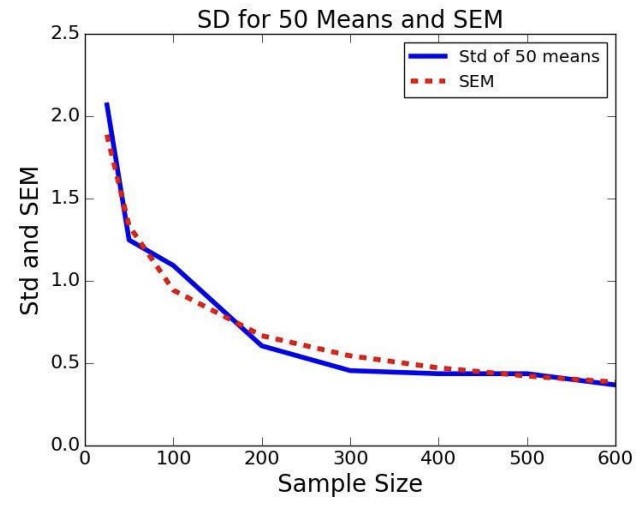
기온 데이터에서 실제로 잘 적용되는지 살펴보자.
매우 잘 적용된다! 표준오차를 이용하면 여러 표본들의 평균의 표준편차를 (실제로 샘플을 많이 만들지 않고도) 추정할 수 있는 것이다.
그런데 위에 제시된 표준오차의 공식에는 치명적인 결함이 있다. 바로 모집단의 표준편차를 알아야 한다는 것이다. 모집단을 전부 조사할 수 없어서 표본을 추출하는데 모집단의 표준편차를 알아야 한다니…
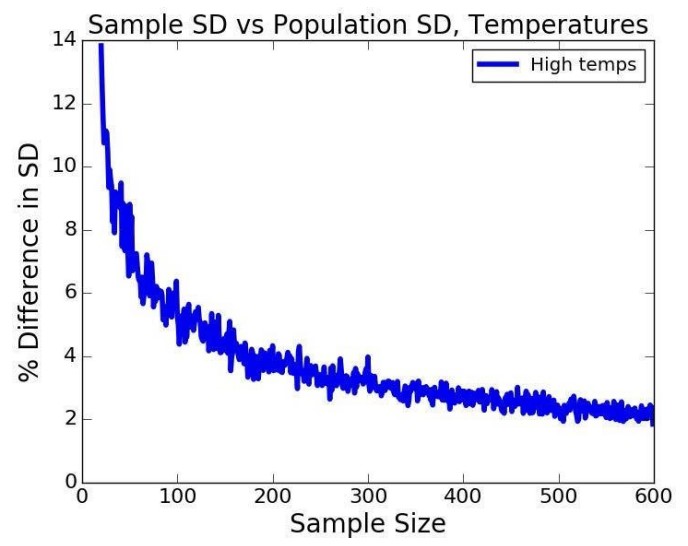
그럼 모집단의 표준편차 대신 무엇을 사용할 수 있을까? 표본의 표준편차를 사용하는 것을 하나의 대안으로 생각할 수 있다. 그런데 실제로 사용해도 좋을까?
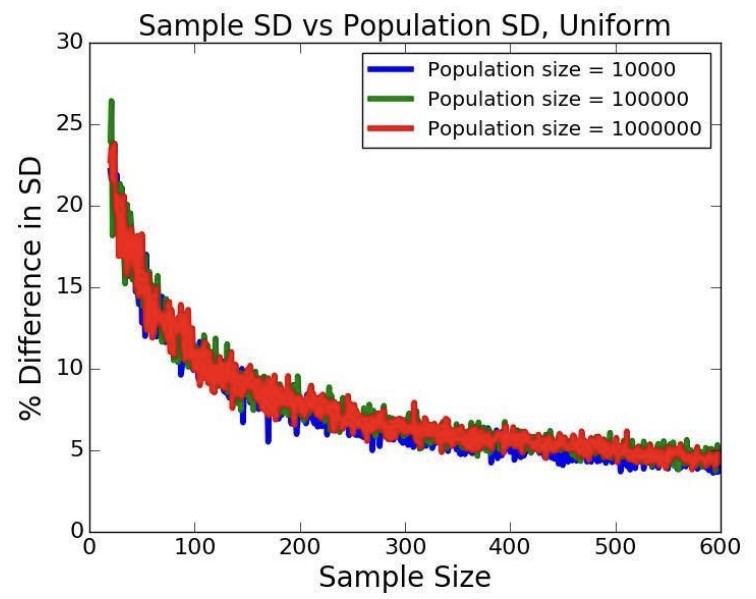
표본의 크기가 커질수록 표본표준편차와 모표준편차의 차이가 더 줄어든다.
모집단의 분포와 크기에 따른 변동
그런데 여기서 사용한 기온 데이터에만 이 이론이 적용되는 것이 아닐까 의문이 든다. 모집단의 분포가 다르면? 모집단의 크기가 다르면?
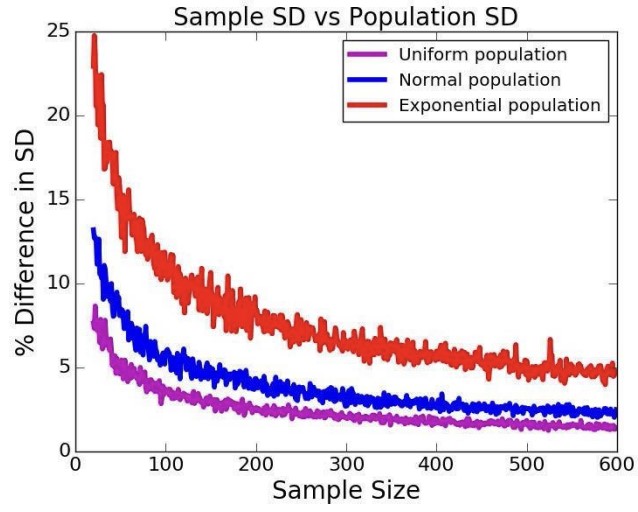
먼저 여러 분포에 대해 살펴보았다. 연속균등분포, 정규분포, 지수분포에 대해 표본과 모집단의 표준편차 차이는 아래와 같다.
전체적으로 표본의 크기가 커지면 모표준편차와 표본표준편차의 차이가 줄어들기는 하나, 분포에 따라 다르다는 것을 알 수 있다. 좀 더 다듬어서 설명하자면, 확률 분포의 비대칭성을 나타내는 지표인 ‘왜도’가 영향을 미친다. 왜도가 클수록 많은 샘플을 사용해야 차이가 줄어든다.

댓글남기기