제곱을 하는 이유는 여러 가지가 있다. 부호를 제거할 수도 있고, 위 공식을 최솟값을 가지는 함수로 기능하게 할 수도 있다 (이차함수를 떠올리면 쉽다).
위 식을 사용하기 위해서는 일단 곡선을 찾아야 한다. 예측 모델의 다항식 표현을 찾기 위해 ‘선형회귀’를 사용한다.
선형회귀를 설명하기 위해 일차 다항식 $y=ax+b$를 예를 들어 보자. 이 다항식을 사용해 모든 x값에 대해 y값을 계산하고 최소제곱 목적 함수에 대입한다. a와 b의 값을 바꾸어가면서 목적 함수의 값이 가장 최소가 되는 a, b를 찾으면 그 것이 바로 가장 잘 들어맞는 직선인 것이다.
cf. 왜 ‘선형’회귀일까?
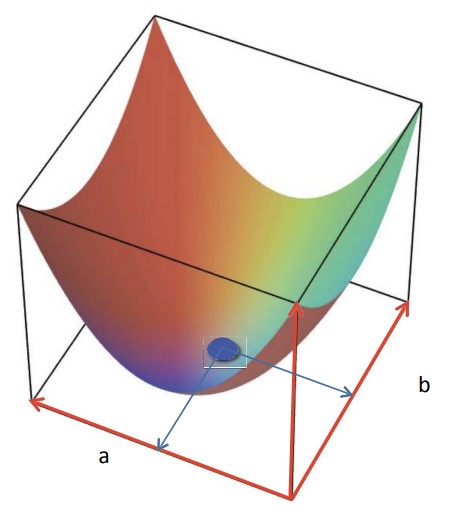
일차식 $y=ax+b$가 있을 때, a와 b를 축으로 하는 평면을 생각할 수 있다. 이 평면은 모든 직선을 포함한다.
목적함수의 값이 높이라고 할 때, 우리는 최적의 피팅 곡선을 찾기 위해 곡면 위 임의의 점에서 시작하여 곡면의 가장 밑까지 ‘선형’으로 이동하게 된다. 곡면의 가장 밑에 해당하는 a, b가 최적의 곡선(직선)인 것이다.
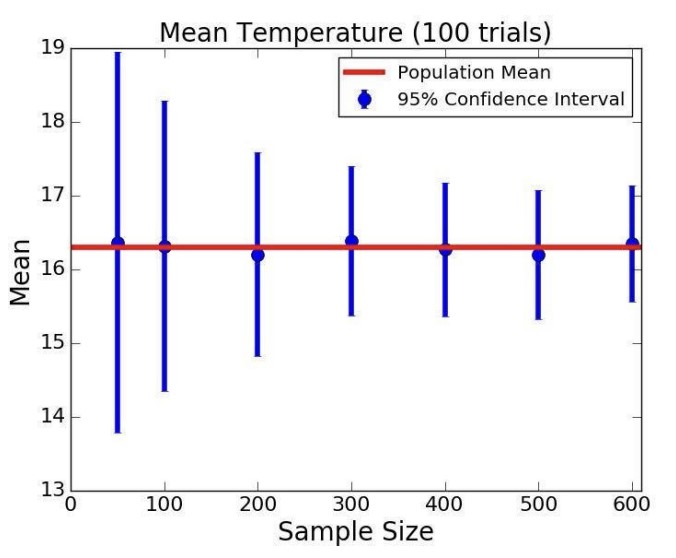
위 그림에서 선의 범위가 곧 신뢰구간을 나타낸다고 보면 된다. 각각의 선의 범위가 겹친다면 통계적으로 큰 의미가 없다고 판단한다. 범위가 겹치지 않는 선 만이 통계적으로 매우 다르다고 할 수 있다.
기온 데이터의 에러바를 살펴보자.
운이 좋게도, 파이썬에서는 일일이 이를 계산할 필요가 없다. pylab의 polyfit을 사용하면 원하는 차수에 대해 가장 잘 들어맞는 다항식을 찾아준다.
적합한 회귀 찾기
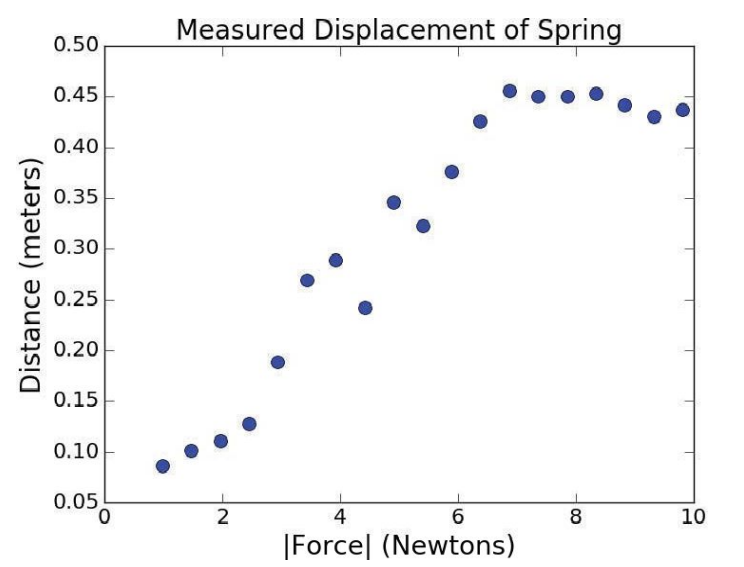
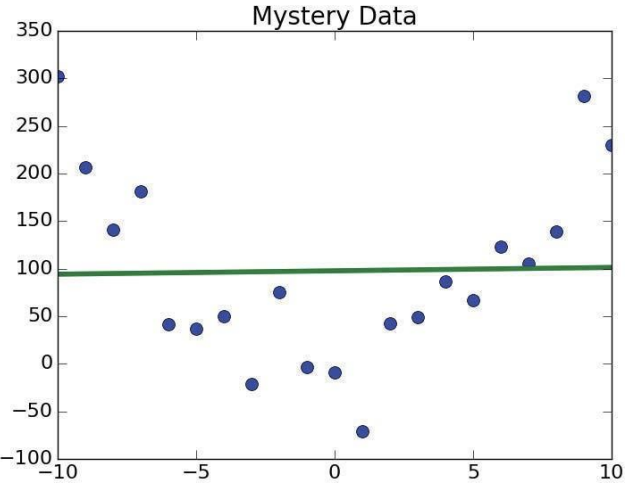
아래와 같은 데이터를 1차 다항식으로 피팅한다고 하자.
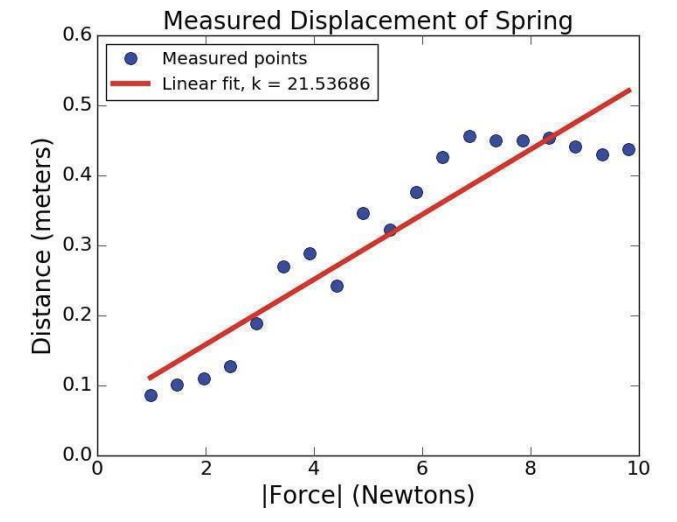
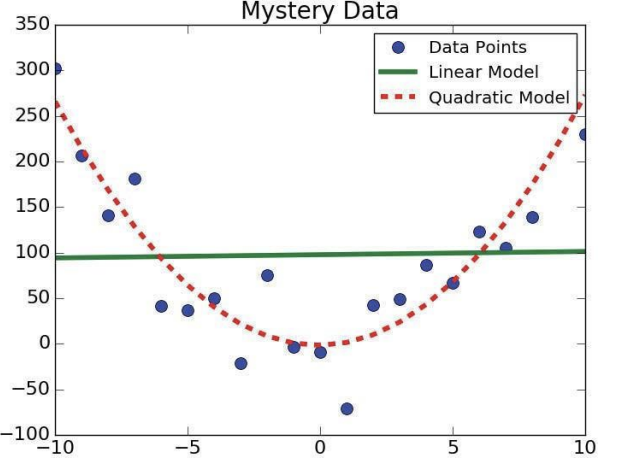
매우 부적절한 직선이 생성되었다. 전혀 쓸모가 없는 피팅이다. 2차원 피팅은 어떨까?
그나마 1차보다는 나아보인다. 그러나 눈대중으로 보는 것 말고, 진짜 더 나은 피팅인지 테스트할 방법은 없을까?
먼저 상대적인 관점에서 분석해보자. 2차가 1차보다 더 나은지를 살펴보는 것이다. 이미 살펴본 공식으로 충분하다. 제곱 오차의 값을 비교하면 되는 것이다.
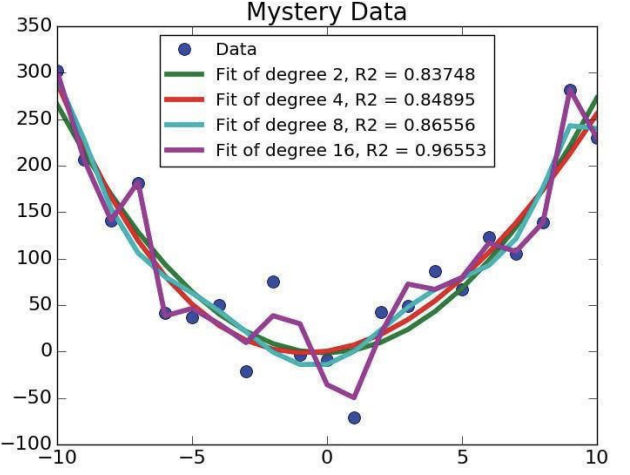
그러나 우리는 절대적인 적합도를 판단하고 싶다. 두 개 중에 더 나은지가 아니라, 전체적인 회귀 곡선 중에서 얼마나 정확한지를 말이다. 절대적인 적합도를 판단할 때는 결정계수($R^2$)를 사용한다.

댓글남기기