
지난 강의에서 비지도학습을 공부했다면 이번 강의에서는 레이블이 있는 지도 학습을 공부한다.
최근접 분류와 k-최근접 분류
거리 행렬은 각 요소 간 거리 정보를 가지고 있는 행렬을 말한다.
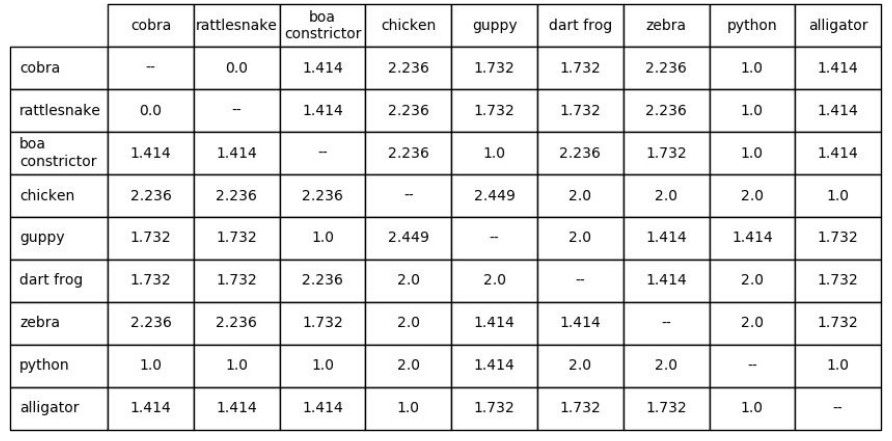
거리 행렬을 이용해 분류하는 가장 간단한 방법은 ‘최근접 분류’이다. 새로운 데이터의 레이블을 예측해야 할 때 거리 행렬을 사용해 가장 가까운 데이터를 찾는다. 그리고 그 데이터의 레이블을 새로운 데이터에 할당하면 되는 것이다.
그러나 이 방법은 치명적인 문제점이 있다. 가장 유사한(거리가 가까운) 1개의 데이터만을 사용하다보니 오류가 생겨도 정정을 할 여지가 없다. 예를 들어, 손글씨 식별 프로그램에서 9와 0은 혼동하기가 매우 쉽다.
이를 보완하는 방법으로는 ‘k-최근접 이웃 분류(KNN)’이 있다. 쉽게 설명하면 일종의 ‘투표’를 하는 방식이다. 새로운 데이터와 가까운 k개(보통 홀수)의 데이터를 선정하고, 더 많은 레이블로 결정하는 것이다.
KNN의 장점으로는 빠르게 학습하며 별도의 훈련이 필요가 없다는 것이다. 또한, 방법과 결과를 설명하기 좋다. 그러나 메모리 소비가 크고 시간이 오래 걸리며(그래도 무차별 대입보다는 낫다), 데이터를 만들어낸 과정에 대해서는 알 수가 없다.
타이타닉에 탑승했던 승객의 데이터를 이용해 누가 살아남을지를 예측하는 모델을 만들 수 있다.
cf. 무작위 부차추출 반복
무작위 부차추출 반복(Repeated random subsampling)은 Leave-one-out과 유사하지만, 일정 비율의 데이터를 제외한다는 점에서 다르다. 예를 들어, 비율을 80/20으로 설정할 경우, 80%의 데이터로는 모델을 만들고 20%의 데이터로는 모델을 검증한다.
로지스틱 회귀
로지스틱 회귀는 사건의 확률을 예측하기 위해 설계되었다. 종속 변수는 지정된 값만을 가질 수 있으며, 이로 인해 분류의 문제(주로 0과 1)로 해석되기도 한다.
선형회귀를 확률 예측에 사용하면 가끔 0보다 작거나 1보다 큰 확률이 도출되기도 하였다. 이럴 때는 로지스틱 회귀를 사용해야 한다.
로지스틱 회귀는 각 특성에 대한 가중치를 계산한다.
- 양의 값: 변수가 결과와 양의 상관관계를 가짐.
- 음의 값: 변수가 결과와 음의 상관관계를 가짐.
- 절대 수치의 크기: 상관관계의 강도
‘로지스틱’이라는 이름은 로그함수를 사용하기 때문에 붙은 이름이다. 최적화 문제가 복잡하기 때문에, 이 강의에서는 원리를 자세히 설명하는 대신 코딩에 초점을 두었다. 파이썬에서는 sklearn.linear_model을 import하면 LogisticRegression을 사용할 수 있다.
포스트에 사용된 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기