
지난 강의에서 16차 피팅이 매우 좋은 모습을 보였다. 그러나 해당 피팅으로 만들어진 모델을 실제로 사용하기에는 무리가 있다. 왜 그럴까?
모델을 만드는 목적
모든 일을 목적을 가지고 진행되어야 한다. 우리가 모델을 만드는 이유는 두 가지가 있다.
- 데이터가 생성된 과정을 이해하기 위해 (ex. 훅의 법칙 구하기)
- 예측하기 위해 (ex. 날씨 예측, 선거 결과 예측)
위 목적을 만족시키지 못하면 좋지 못한 모델인 것이다.
학습 오차
앞서 살펴본, 16차가 최적이었던 데이터는 사실 2차식으로 생성된 데이터에 적당한 노이즈를 추가한 것이었다. 16차 모델이 2차로 생성된 데이터를 가장 잘 피팅한다고 하더라도 그 제작 과정을 알기에 우리는 16차 대신 2차를 모델로 선택해야 하는 것이다.
위와 같이 다른 차수의 모델이 더 잘 적용되는 상황은 ‘학습 오차’로 인해 발생한 것이다. 학습 오차는 모델이 학습한 데이터에 대한 성능을 의미한다.
좋은 모델들은 학습 오차가 작지만, 학습 오차가 작다고 해서 항상 좋은 모델은 아니다. 우리는 같은 과정을 거쳐 생성된 다른 데이터들에도 잘 작동하는 ‘국제용’ 모델을 원하지, 모델을 생성하기 위해 사용된 데이터에만 잘 적용되는 ‘국내용’모델을 원하지 않는다.
즉, 모델은 일반화되어야 한다.
교차 검증으로 가장 적합한 모델 찾기
모델을 일반화하기 위해서는 ‘교차 검증’ 과정을 거쳐야 한다. 말 그대로 만든 모델을 여러 데이터들에 교차하여 적용해본다는 의미이다.
방법은 매우 간단하다. 만든 모델에 다른 데이터를 적용하고 지난 강의에서 했던 것처럼 결정계수를 계산해보면 된다.
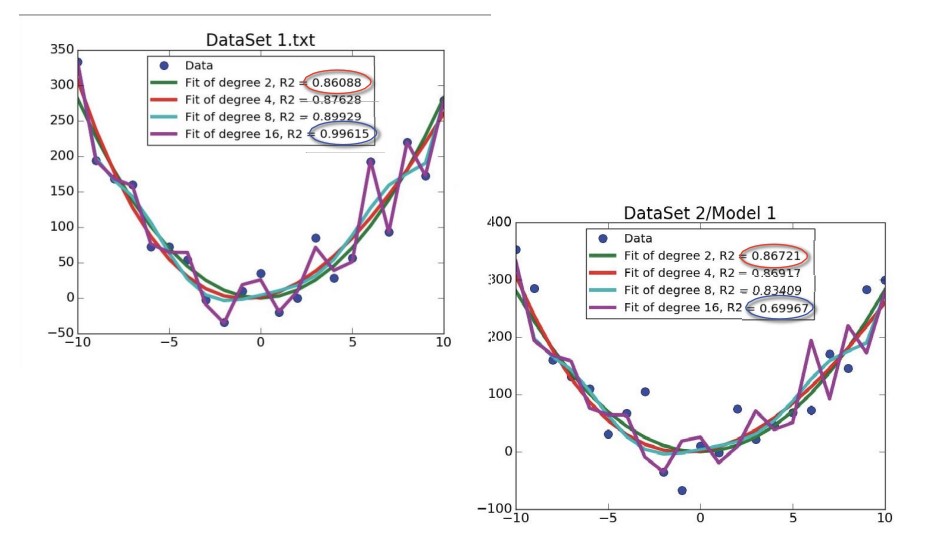
앞서 만든 모델을 다른 데이터에 적용한 결과이다. 2차 모델을 비슷한 결정계수를 가졌지만, 16차의 경우 결정계수의 값이 매우 떨어졌다.
학습 중간에 차수를 증가시켜 피팅하면 어떻게 될까? 추가된 항이 쓸모가 없다면 계수가 0으로 나올 것이다.
실제로 결과를 보면, 완벽한 데이터를 적용한 경우, 피팅된 모델의 차수에는 변화가 없었다. 그러나 노이즈를 추가하면 점점 모델의 결정계수가 감소하는 것을 확인할 수 있었다.
모든 것은 균형을 이루어야 한다. 지나치게 복잡한 모델은 ‘과도하게 적합한(과대 적합)’ 경우가 많고, 지나치게 단순한 모델은 중요한 것은 놓칠 수 있다.
그럼 어떻게 가장 적합한 모델을 선정해야할까? 방법은 다음과 같다.
- 낮은 차수로 피팅하기 시작
- 새로운 데이터로 검증하고 결정계수 기록
- 모델의 차수를 증가시키고 위 과정 반복
- 모델의 적합도가 감소할 떄까지 반복
교차 검증의 방법
교차 검증에는 크게 세 가지 방법이 있다.
- leave-one-out
- k-fold
- 반복 무작위 추출
데이터셋이 작으면 leave-one-out을, 데이터셋이 충분히 크면 k-fold나 반복 무작위 추출을 사용한다.
leave-one-out을 간단하게 설명하면 다음과 같다. 데이터셋에서 데이터(점)를 하나씩 제거하면서 나머지 데이터로 모델을 생성한다. 그리고 그 모델이 버린 점을 얼마나 잘 예측하는지를 검증하는 것이다.
k-fold는 하나의 데이터(점) 대신 하나의 데이터셋을 버리고 나머지 데이터셋으로 검증을 실행한다는 점에서 leave-one-out과 유사하다.
반복 무작위 추출은 데이터셋에서 데이터를 무작위롤 추출하여 모델을 만들고 나머지롤 테스트를 진행하는 것이다. 이 과정을 반복적으로 진행한다.
피팅은 여러 번 반복해서 진행해야 한다. 한 번의 피팅으로 나온 모델이 최적일지 아닐지 알 수 없다. 따라서 많은(최소 10번) 피팅을 통해 모델을 다양하게 만들고, 결정계수를 검토하여 가장 최적의 모델을 만들어야 한다.
포스트에 사용된 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기