
군집을 사용한 이미지 분할
이미지 분할에는 여러 가지 변형이 있다.
- 색상 분할: 동일한 색상을 가진 픽셀을 같은 세그먼트에 할당. (e.g. 인공위성 사진에서 한 지역을 산림 면적을 측정.)
- 시맨틱 분할: 동일한 종류의 물체에 속한 모든 픽셀을 같은 세그먼트에 할당. (e.g. 보행자 식별 프로그램)
- 인스턴스 분할: 개별 객체에 속한 모든 픽셀을 같은 세그먼트에 할당. (e.g. 보행자 ID 인식 프로그램)
위 3가지 중 색상 분할이 k-평균을 사용한다.
다음 코드는 아래 작업을 수행한다.
- 사진 배열의 크기를 바꾸어 긴 RGB 색상 리스트로 만든다.
- k-평균을 이용해 8개의 클러스터로 모은다.
- 각 픽셀에 대해 가장 가까운 클러스터 중심으로 포함한
segmented_img배열을 생성한다. 여기에는 고급 numpy 인덱싱이 사용된다. - 이 배열을 원래 이미지 크기로 복원한다.
X = image.reshape(-1, 3)
kmeans = KMeans(n_clusters=8, random_state=42).fit(X)
segmented_img = kmeans.cluster_centers_[kmeans.labels_]
segmented_img = segmented_img.reshape(image.shape)
k에 따른 변환의 결과는 다음과 같다. 색상의 개수에 따라 그림의 디테일이 달라진다.

준지도 학습
준지도 학습에서 군집을 사용하면 레이블을 같은 군집 내로 전파할 수 있다고 했다.
다음 코드는 train set을 50개의 cluster로 모으고, 각 cluster에서 centroid에 가장 가까운 이미지를 찾는다. 이를 대표 이미지라고 한다.
k = 50
kmeans = KMeans(n_clusters=k, random_state=42)
X_digits_dist = kmeans.fit_transform(X_train)
representative_digit_idx = np.argmin(X_digits_dist, axis=0)
X_representative_digits = X_train[representative_digit_idx]
그런 다음 대표 이미지에 수동으로 레이블을 할당하고, 이 레이블을 같은 cluster내로 전파하면 된다.
y_train_propagated = np.empty(len(X_train), dtype=np.int64)
for i in range(k):
y_train_propagated[kmeans.labels_ == i] = y_representative_digits[i]
여기서 그치지 않고, cluster 중심에서 거리가 너무 먼 샘플을 무시하여(이상치로 고려하여) 훈련하면 더 높은 정확도를 얻을 수 있다. 코드에서는 거리가 먼 1%의 샘플을 거리 -1로 설정한 다음 무시하였다. 자세한 방법은 코드를 참조하자.
cf. 능동 학습(Active Learning)
전문가와 학습 알고리즘이 상호 작용하여, 알고리즘이 요청할 때 전문가가 레이블을 제공하는 학습이다. 일단 모델이 훈련한 다음, 불확실한 샘플에 대해 전문가가 레이블을 직접 부여한다.
DBSCAN
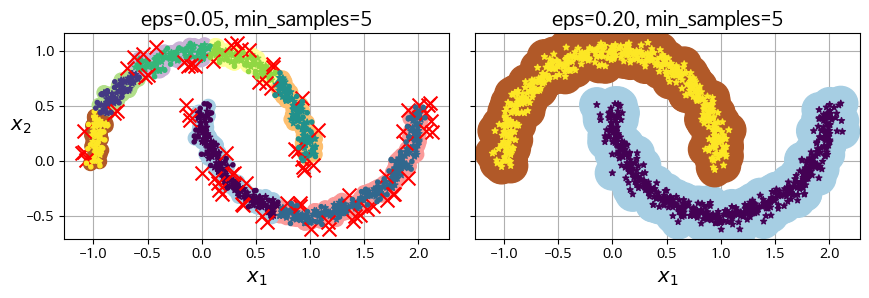
DBSCAN(Density-Based Spatial Clustering of Applications with Noise) 알고리즘은 밀집된 연속적 지역을 클러스터로 지정한다. 구제적인 방법은 다음과 같다.
- 각 샘플에서 작은 거리인 $\epsilon$ 안에 샘플이 몇 개 놓여 있는지 센다. 이 지역을 샘플의 $\epsilon$-이웃 이라고 한다.
- 자기 자신을 포함해 $\epsilon$-이웃 내에 적어도
min_samples개의 샘플이 있다면, 이를 핵심 샘플로 간주한다. 즉, 핵심 샘플은 밀집된 지역에 있는 샘플이다. - 핵심 샘플의 이웃에 있는 모든 샘플은 동일한 cluster에 속한다. 물론, 이웃에는 다른 핵심 샘플이 포함될 수도 있다. 이웃에 이웃이 꼬리를 물고 점점 클러스터가 넓어진다.
- 핵심 샘플도 아니고, 이웃도 아니면 이상치이다.
코드로 구현하면 다음과 같다.
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05, random_state=42)
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)
# print labels of all samples
dbscan.labels_ # -1 means outlier
# index of core samples
dbscan.core_sample_indices_
# core samples
dbscan.components_
DBSCAN 클래스는 predict() 매서드를 제공하지 않는다. 따라서 새로운 샘플에 대해 예측하려면 사용자가 직접 필요한 예측기를 선택해야 한다. 다음은 KNeighborsClassifier를 사용한 예시이다.
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])
X_new = np.array([[-0.5, 0], [0, 0.5], [1, -0.1], [2, 1]]) # new samples
knn.predict(X_new)
knn.predict_proba(X_new)
DBSCAN은 매우 간단하고 강력하지만, cluster 간 밀집도가 크게 다르거나 cluster 주변에 충분한 저밀도 구역이 없는 경우, 대규모 dataset이라면 잘 작동하지 않는다(계산 복잡도가 $O(m^2n)$ 이다).
다른 군집 알고리즘
- 병합 군집
- BIRCH
- 평균-이동
- 유사도 전파
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기