
Boosting
부스팅(boosting)은 약한 학습기를 여러 개 연결해서 강한 학습기를 만드는 것을 의미한다.
AdaBoost
이전 예측기가 과소적합했던 훈련 샘플의 가중치를 더 높이면 개선된 예측기를 만들 수 있을 것이다. 이를 AdaBoost라고 한다. AdaBoost는 다음과 같이 작동한다.
- 첫 번째 분류기 훈련하고 에측 생성.
- 잘못 분류된 샘플의 가중치 높임.
- 두 번째 분류기는 업데이트 된 가중치를 이용해 훈련하고 예측 생성.
- 2~3 과정 반복.
Adaboost에서 사용되는 수식을 자세히 들여다보자. 각 샘플의 가중치($w^{(i)}$)는 초기에 $\frac{1}{m}$ 로 초기화 된다.
먼저 j번째 예측기의 가중치가 적용된 오류율은 다음과 같다.
\[r_j = \frac{\displaystyle \underset{\hat{y}^{(i)}_j \neq y^{(i)}} {\sum_{i=1}^{m}{w^{(i)}}}}{\displaystyle \sum_{i=1}^{m}{w^{(i)}}}\]($\hat{y}^{(i)}_j$ 는 i번째 샘플에 대한 j번째 예측기의 예측)
위 오류율을 가지고 예측기 가중치를 구할 수 있다. 예측기가 정확할수록 가중치는 높아진다. $\eta$ 는 학습률 파라미터이다(기본값 1).
\[\alpha_j = \eta \log{\frac{1 - r_j}{r_j}}\]예측기 가중치는 샘플 가중치를 업데이트하는 것에 사용된다. 샘플 가중치를 업데이트하는 규칙은 다음과 같다.
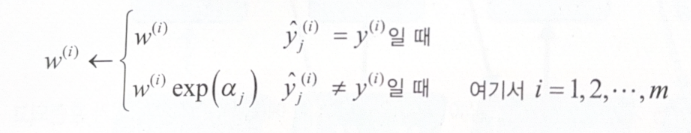
잘못 분류된 샘플의 가중치가 높아지는 것을 확인할 수 있다. 위 과정 이후 모든 샘플의 가중치를 정규화($\displaystyle \sum_{i=1}^{m}{w^{(i)}}$ 로 나누기)한다.
Adaboost에서 예측을 할 때는 단순히 모든 예측기의 예측을 계산하고, 예측기 가중치 $\alpha_j$ 를 더해 예측 결과를 만든다. 가중치 합이 가장 큰 클래스가 예측 결과가 된다.
\[\hat{y}(\mathbf{x}) = \underset{k}{argmax} \underset{\hat{y}(\mathbf{x}) = k}{\sum_{j=1}^{N}{\alpha_j}}\]코드는 다음과 같다.
from sklearn.ensemble import AdaBoostClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=1), n_estimators=30,
learning_rate=0.5, random_state=42
)
ada_clf.fit(X_train, y_train)
Gradient Boosting
Gradient Boosting은 다음 예측기가 이전 예측기의 결과를 활용한다는 점에서 Adaboost와 비슷하지만, 샘플 가중치를 업데이트 하는 것이 아닌 잔여 오차를 이용한다. 결정 트리를 기반 예측기로 활용하는 gradient boosting 회귀를 Gradient Boosted Regression Tree(GBRT)라고 한다.
- 첫 번째 예측기 훈련하고 에측 생성.
- 첫 번째 예측기의 잔여 오차 계산
- 두 번째 예측기는 첫 번째 예측기의 잔여 오차만을 이용해서 훈련.
- 2~3 과정 반복.
새로운 샘플에 대한 예측을 만드려면 모든 트리의 예측을 더하면 된다.
코드는 다음과 같다.
import numpy as np
from sklearn.tree import DecisionTreeRegressor
np.random.seed(42)
X = np.random.rand(100, 1) - 0.5
y = 3*X[:, 0]**2 + 0.05 * np.random.randn(100)
# first predictor
tree_reg1 = DecisionTreeRegressor(max_depth=2, random_state=42)
tree_reg1.fit(X, y)
# second predictor
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2, random_state=43)
tree_reg2.fit(X, y2)
# third predictor
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2, random_state=44)
tree_reg3.fit(X, y3)
# make prediction
X_new = np.array([[-0.4], [0.], [0.5]])
sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
GradientBoostingRegressor를 훈련하면 GBRT 앙상블을 간단하게 훈련시킬 수 있다.
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0, random_state=42)
gbrt.fit(X, y)
learning_rate를 낮게 하면 많은 트리를 사용하는 대신 예측의 성능이 좋아진다(shrinkage라고 부르는 규제 방법이다). 당연히 너무 많은 트리를 사용하면 과대 적합이 될 수 있다.
n_iter_no_change=n은 마지막 n개의 트리가 도움이 되지 않으면 훈련을 종료한다는 의미이다. 마치 early stopping과 같이 사용할 수 있다.
gbrt_best = GradientBoostingRegressor(
max_depth=2, learning_rate=0.05,
n_estimators=500, n_iter_no_change=10, random_state=42)
gbrt_best.fit(X, y)
Stochastic Gradient Boosting이라는 방법도 사용할 수 있다. subsample=0.25로 설정하면 각 트리는 랜덤으로 선택된 25%의 훈련 샘플로만 학습한다. 훈련 속도가 빨라지는 대신 편향이 커진다.
Histogram-based Gradient Boosting
Histogram-based Gradiet Boosting은 입력 특성을 구간으로 나누어(히스토그램처럼) 정수로 대체한다. 이는 다양한 장점이 있다.
- 구간 분할을 사용하면 학습 알고리즘이 평가해야 하는 가능한 임곗값을 크게 줄일 수 있다.
- 정수를 사용하면서 데이터 구조가 메모리 효율적이게 된다.
- 각 트리를 학습할 때 특성 정렬을 할 필요가 없다.
- 계산 복잡도는 $O(b \times m)$ (b는 구간의 개수, m은 훈련 샘플의 개수)이다. 일반 GBRT보다 수백 배 빠른 셈이다.
물론 단점도 있다. 구간 분할이 규제처럼 작동하므로 정밀도가 떨어지고, 과소적합이 일어날 수 있다.
HGB 클래스는 범주형 특성과 누락된 값을 지원하며, 이는 데이터 전처리를 상당히 감소시키는 효과가 있다. 아래 코드는 2장에서 실습한 파이프라인 코드와 동일한 기능을 수행하지만 훨씬 간단하다.
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformer
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.preprocessing import OrdinalEncoder
hgb_clf = make_pipeline(
make_column_transformer((OrdinalEncoder(), ['ocean_proximity']),
remainder='passthrough'),
HistGradientBoostingRegressor(categorical_features=[0], random_state=42)
)
hgb_clf.fit(housing, housing_labels)
categorical_features=[0]는 범주형 열의 인덱스를 설정해준 것이다.
Stacking
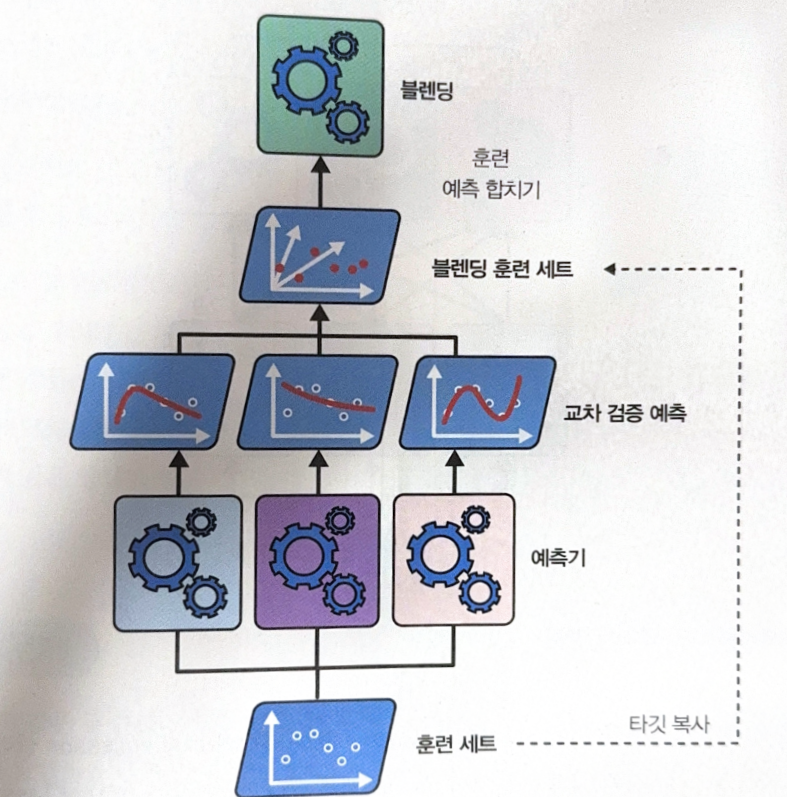
앙상블에 속한 모든 예측기의 결과를 취합하는 모델을 훈련시키는 것을 stacking이라고 한다. 취합하는 모델, 즉 마지막 예측기를 blender라고 한다.
Blender를 훈련하는 과정은 다음과 같다.
- blending train set을 만들어야 한다. 앙상블의 모든 예측기에서
cross_val_predict()를 사용해서 원본 train set에 있는 각 샘플에 대한 표본 외 예측을 얻는다. - 1의 예측 결과를 blender를 훈련하기 위한 입력 특성으로 사용한다. 원본 train set의 특성이 몇 개인지와는 상관 없이, 예측기의 개수가 곧 특성의 개수가 된다.
- blender 학습이 끝나면 기본 예측기는 전체 원본 train set으로 한 번 더 재훈련된다.
from sklearn.ensemble import StackingClassifier
stacking_clf = StackingClassifier(
estimators=[
('lr', LogisticRegression(random_state=42)),
('rf', RandomForestClassifier(random_state=42)),
('svc', SVC(probability=True, random_state=42))
],
final_estimator=RandomForestClassifier(random_state=42),
cv=5
)
stacking_clf.fit(X_train, y_train)
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기