
데이터 정제
데이터셋은 완벽하지 않다. 어떤 값이 비어있을 수도 있고, 빈 값이 너무 많은 특성이 있을 수도 있다. 이러한 경우에 사용할 수 있는 방법은 크게 세 가지가 있다.
- 해당 데이터 제거
- 전체 특성 삭제
- 누락된 값을 어떤 값(평균, 중간 값, 0 등)으로 대체
코드는 다음과 같다.
housing.dropna(subset=['total_bedrooms'], inplace=True) # 값이 없는 데이터 제거
housing.drop("total_bedrooms", axis=1, inplace=True) # 특성 삭제
median = housing['total_bedrooms'].median()
housing['total_bedrooms'].fillna(median, inplace=True) # 중간값으로 채우기
사이킷런의 설계 철학
사이킷런 API의 대표적인 설계 철학은 다음과 같다.
- 추정기(Estimator): 데이터셋을 기반으로 일련의 모델 파라미터를 예측하는 객체. 추정 자체는
fit()에 의해 수행된다. - 변환기(Transformer): 데이터셋을 변환하는 추정기.
transform()이 수행한다.fit()과transform()을 연달아 수행하는fit_transform()도 있다. - 예측기(Predictor): 일부 추정기는 주어진 데이터셋에 대해 예측을 만들 수 있다.
predict()매서드는 새로운 데이터셋을 받아 이에 상응하는 예측값을 반환한다. - 조합성: 기존의 구성 요소를 최대한 활용한다. 여러 변환기를 연결하고 마지막에 추정기를 배치한
Pineline추정기를 만들 수 있다.
범주형 특성 다루기
원-핫 인코딩을 사용하면 범주형 특성을 다룰 수 있다.
특성 스케일링
특성마다 스케일이 다르므로 스케일링을 통해 특성들의 범위를 맞추어 주어야 한다.
- Min-max 스케일링
from sklearn.preprocessing import MinMaxScaler
min_max_scaler = MinMaxScaler(feature_range=(-1, 1))
housing_num_min_max_scaled = min_max_scaler.fit_transform(housing_num)
- 표준화(Standardization)
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
housing_num_std_scaled = std_scaler.fit_transform(housing_num)
데이터 분포 변환하기
특성 분포의 꼬리가 두꺼울 때(eg. 멱법칙 분포), 분포가 대칭적으로 되도록 변환해주어야 한다.
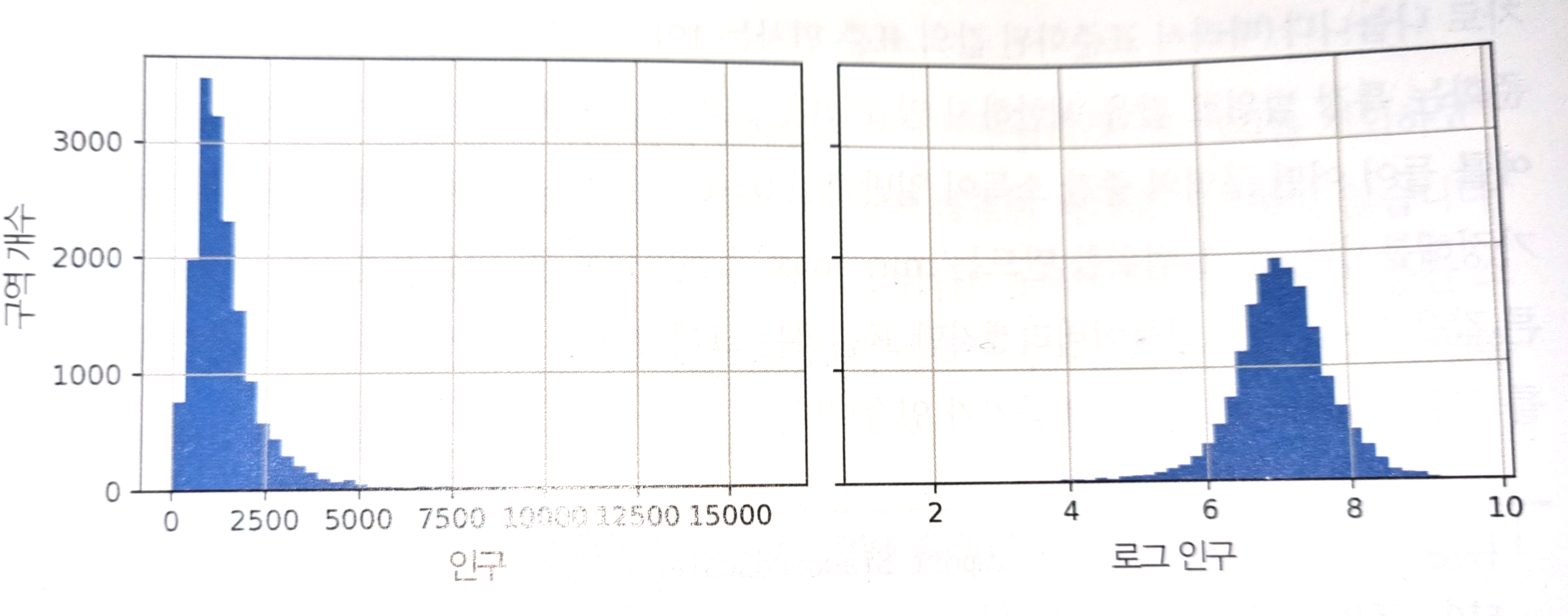
- 제곱근 사용
- 로그 사용
- 버킷다이징(bucketizing): 분포를 동일한 크기의 버킷으로 자르고 특성 값을 해당하는 버킷의 값으로 바꾼다.
- 방사 기저 함수(Radial Basis Function, RBF): 정점(모드)이 두 개 이상 나타나는 멀티모달 분포에서 사용하는 방식. 데이터와 모드 사이의 유사도를 표현한다.
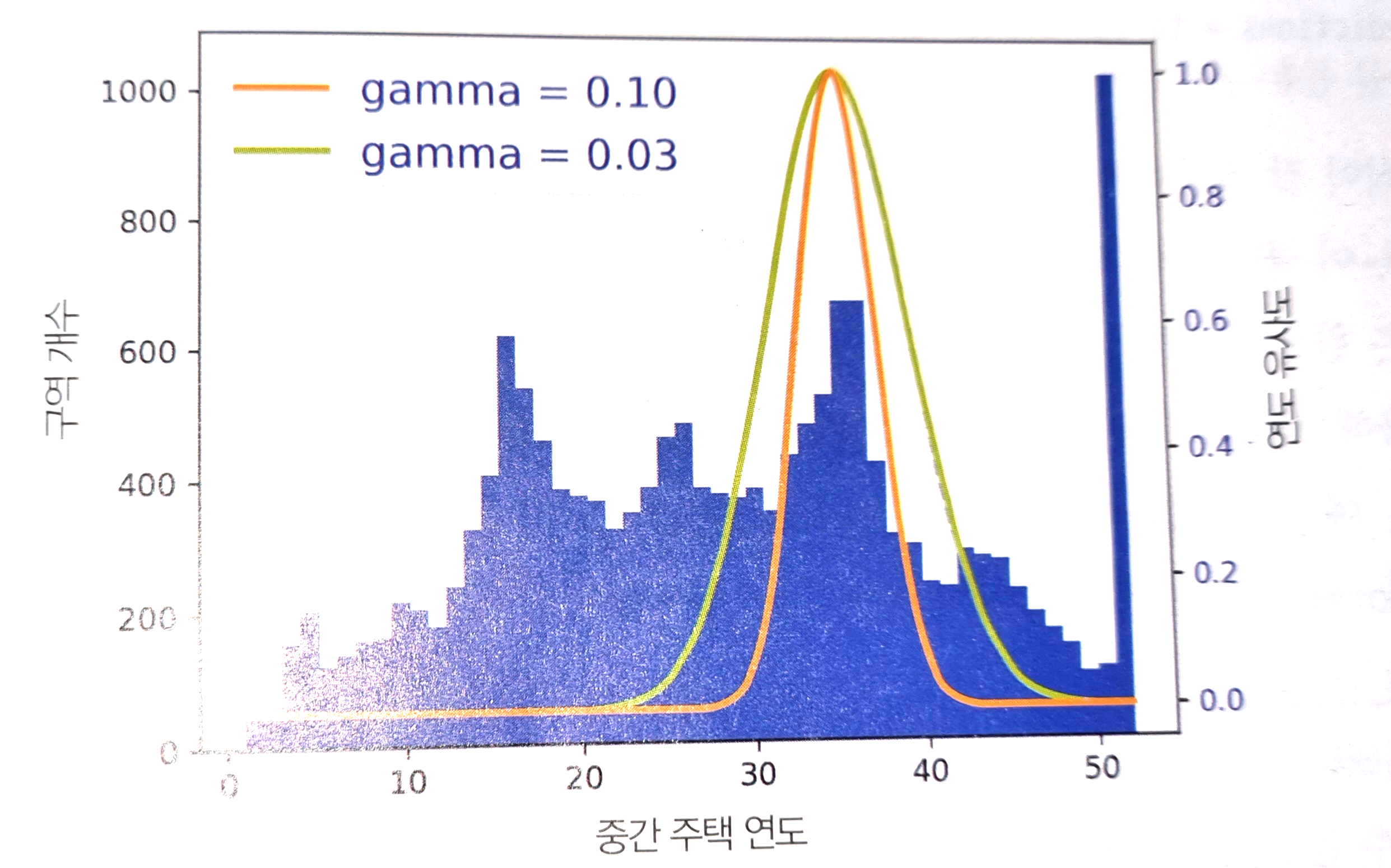
사용자 정의 변환기
사이킷런에서 유용한 변환기를 많이 제공하지만 자신만의 변환기를 만들 수도 있다.
변환 파이프라인
파이프라인을 구현하는 데 사용하는 함수들은 다음과 같다.
| 함수 | 설명 |
|---|---|
Pipeline() |
기본적인 파이프라인 제작. |
make_pipeline() |
변환기의 이름을 짓는 것이 귀찮을 때 사용. |
ColumnTransformer() |
하나의 변환기로 모든 열을 처리할 때 사용. |
자세한 사용 방법과 예시는 코드를 참고하도록 하자.
본 예시에서의 파이프라인
본 예시에서의 파이프라인은 다음과 같은 작업을 수행한다.
- 누락된 값을 대체한다. 숫자형은 중간값, 범주형은 가장 많이 등장하는 값으로 대체한다.
- 범주형 특성을 원-핫 인코딩한다.
- 비율 특성인 ‘bedrooms_ratio’, ‘rooms_per_house’, ‘people_per_house’를 계산해서 추가한다.
- 클러스터 유사도 특성을 추가한다.
- 꼬리가 두꺼운 분포를 띠는 특성을 로그값으로 바꾼다.
- 모든 수치 특성을 표준화한다.
완성된 코드는 다음과 같다.
def column_ratio(X):
return X[:, [0]] / X[:, [1]]
def ratio_name(function_transformer, feature_names_in):
return ['ratio']
def ratio_pipeline():
return make_pipeline(
SimpleImputer(strategy='median'),
FunctionTransformer(column_ratio, feature_names_out=ratio_name),
StandardScaler()
)
log_pipeline = make_pipeline(
SimpleImputer(strategy='median'),
FunctionTransformer(np.log, feature_names_out='one-to-one'),
StandardScaler()
)
cluster_simil = ClusterSimilarity(n_clusters=10, gamma=1, random_state=42)
default_num_pipeline = make_pipeline(SimpleImputer(strategy='median'),
StandardScaler())
preprocessing = ColumnTransformer([
('bedrooms', ratio_pipeline(), ['total_bedrooms', 'total_rooms']),
('room_per_house', ratio_pipeline(), ['total_rooms', 'households']),
('people_per_house', ratio_pipeline(), ['population', 'households']),
('log', log_pipeline, ['total_bedrooms', 'total_rooms', 'population', 'households', 'median_income']),
('geo', cluster_simil, ['latitude', 'longitude']),
('cat', cat_pipeline, make_column_selector(dtype_include=object))
],
remainder=default_num_pipeline)
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기