
Allocating Computations and Variables to Device
There are several points to check before allocating computations and variables.
- Generally, allocate preprocessing to CPU and NN computations to GPU.
- GPU has communication bandwidth. Therefore, avoid unnecessary data transfer using GPU.
- Adding RAM to CPU is easy, but to GPU is hard. Therefore, if a certain variable is unnecessary for the next few steps, allocate to CPU.
Basically, except in case that there is no GPU kernel, all variables and computations are allocated to GPU. Variables and computations without GPU kernel(e.g. integer variable or integer tensor) are allocated to CPU.
Parallel Execution on Multiple Devices
One of the strengths using TF function is parallelization. See the following example.
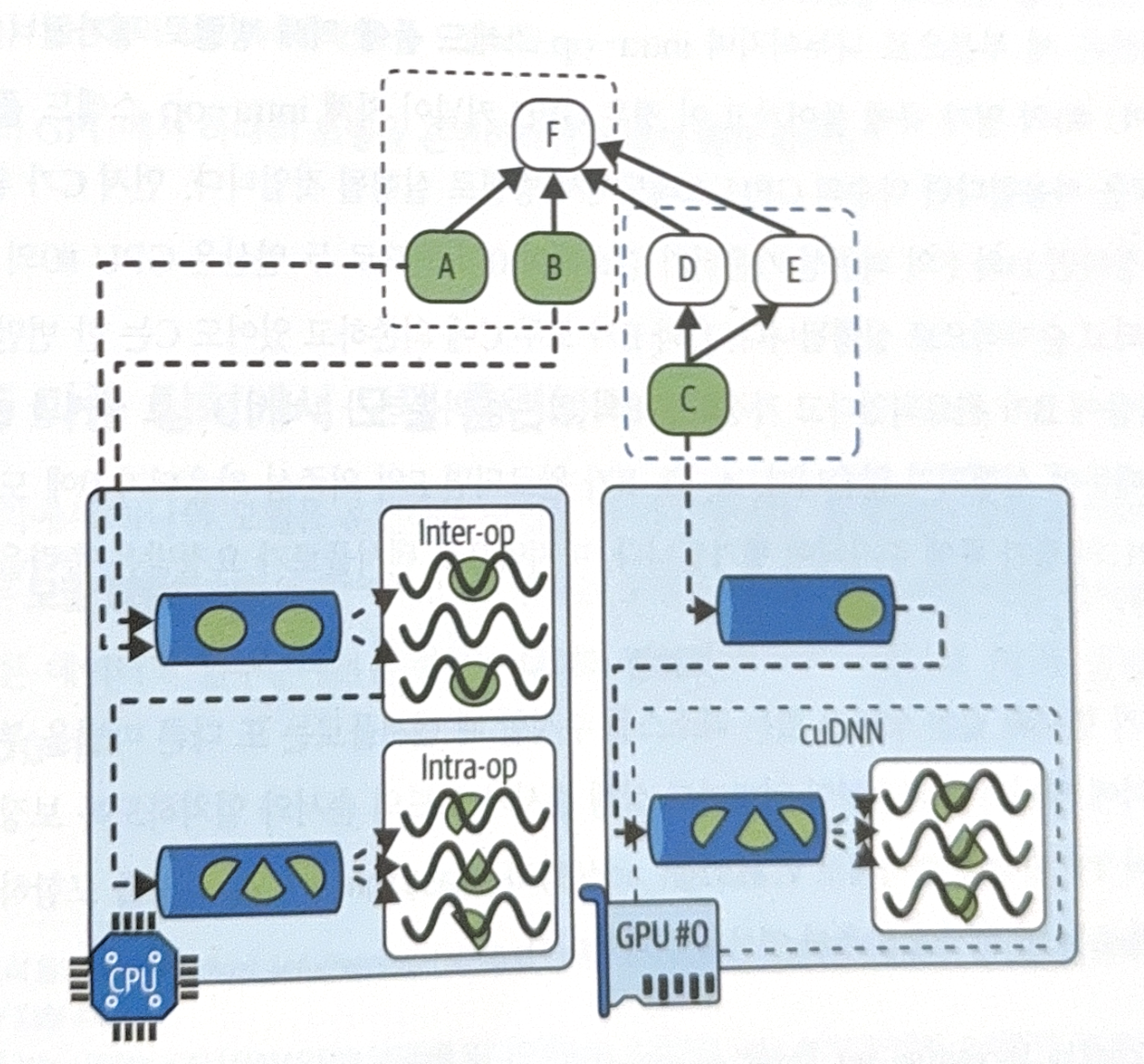
Basic steps are as follows.
- Analyze graph and find the list of operations to evaluate.
- Count how dependent each operation is on the other operations. (e.g. Dependency counter of F is 4.)
- TF sends source operation with 0 dependence to evaluation queue of allocated device. (e.g. A is sent to CPU.)
- If one operation is evaluated, dependency counter of all the other operations that depend on the operation decrease. (e.g. If A evaluated, dependency counter of F decreases from 4 to 3.)
- Repeat step 3 and 4 until all operations are calculated.
Under the basic scenarios above, operations sent to CPU and GPU handled slightly different.
- CPU
- Sent to inter-op thread pool.
- If operation has multi-thread CPU kernel, the operations is divided into multiple parts and allocated to different evaluation queue.
- GPU
- Operations in GPU are evaluated in order.
- Operations with multi-thread kernel(e.g. implemented with CUDA and cuDNN) use as many GPU threads as possible.
Training Model on Multiple Devices: Model Parallelism
First method to train model on multiple devices is to divide model into multiple devices. It is called model parallelism.
Model parallelism is not always good.
- Fully connected NN
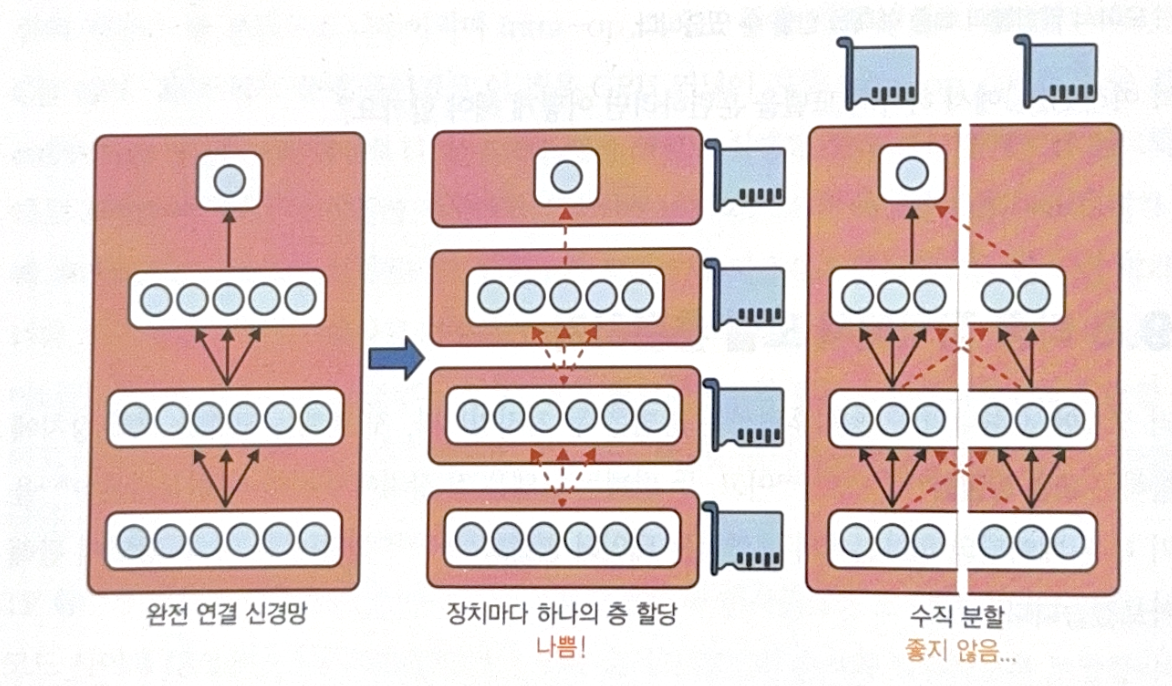
There is no advantage of dividing model on fully connectd NN. When each layer is allocated to one device, one layer should wait for the prior layer. If you vertically divide the model, communications between two devices are needed, which can slow down the process.
- Conv NN
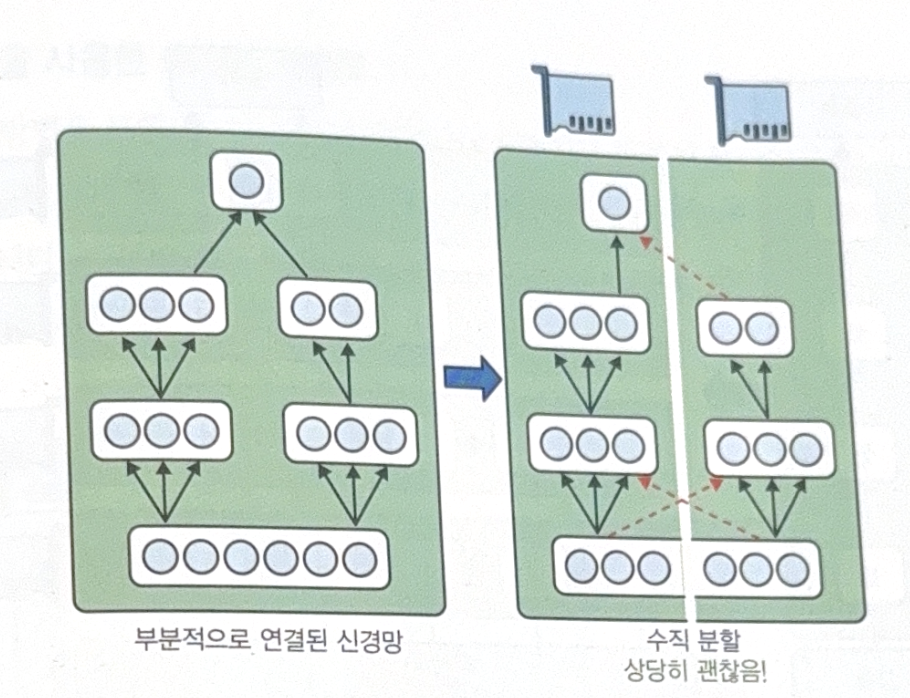
Partially connected NN such as Conv NN has advantage of vertical division. - RNN
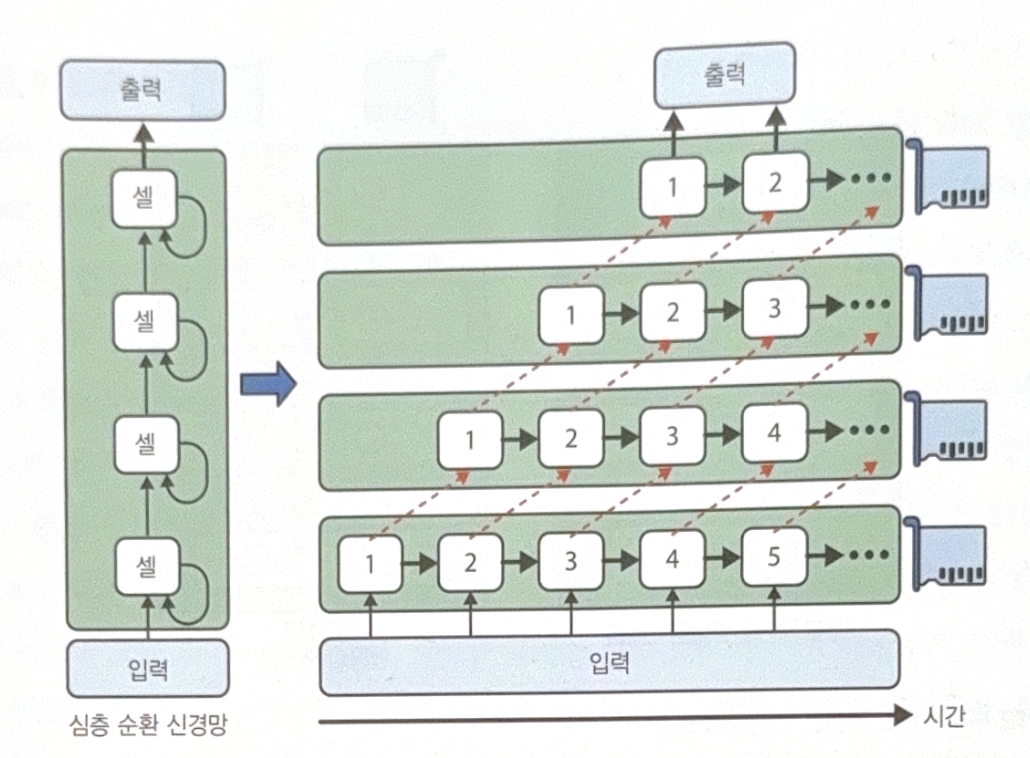
RNN is efficiently divided into multiple devices. See the image above in time scale. At first step, only one device is used. At the second step, two devices are used, and so on. Communications are still needed, but the flaw is smaller than the advantage of parallel computations. (Actually, stacking LSTM on one GPU is faster.)
Training Model on Multiple Devices: Data Parallelism
Seperating data to multiple devices are more general and efficient. First, copy model to multiple devices. After then, divide data into multiple mini batch and perform training step in the the same time. This is called data parallelism or SPMD(Single Program, Multiple Data).
There are many variations, and one of the most important ones is mirrored strategy.
In mirrored strategy, copy model parameters exactly equal to all GPUs and always apply same parameter update to all GPUs. Copied models are preserved in exactly same state.
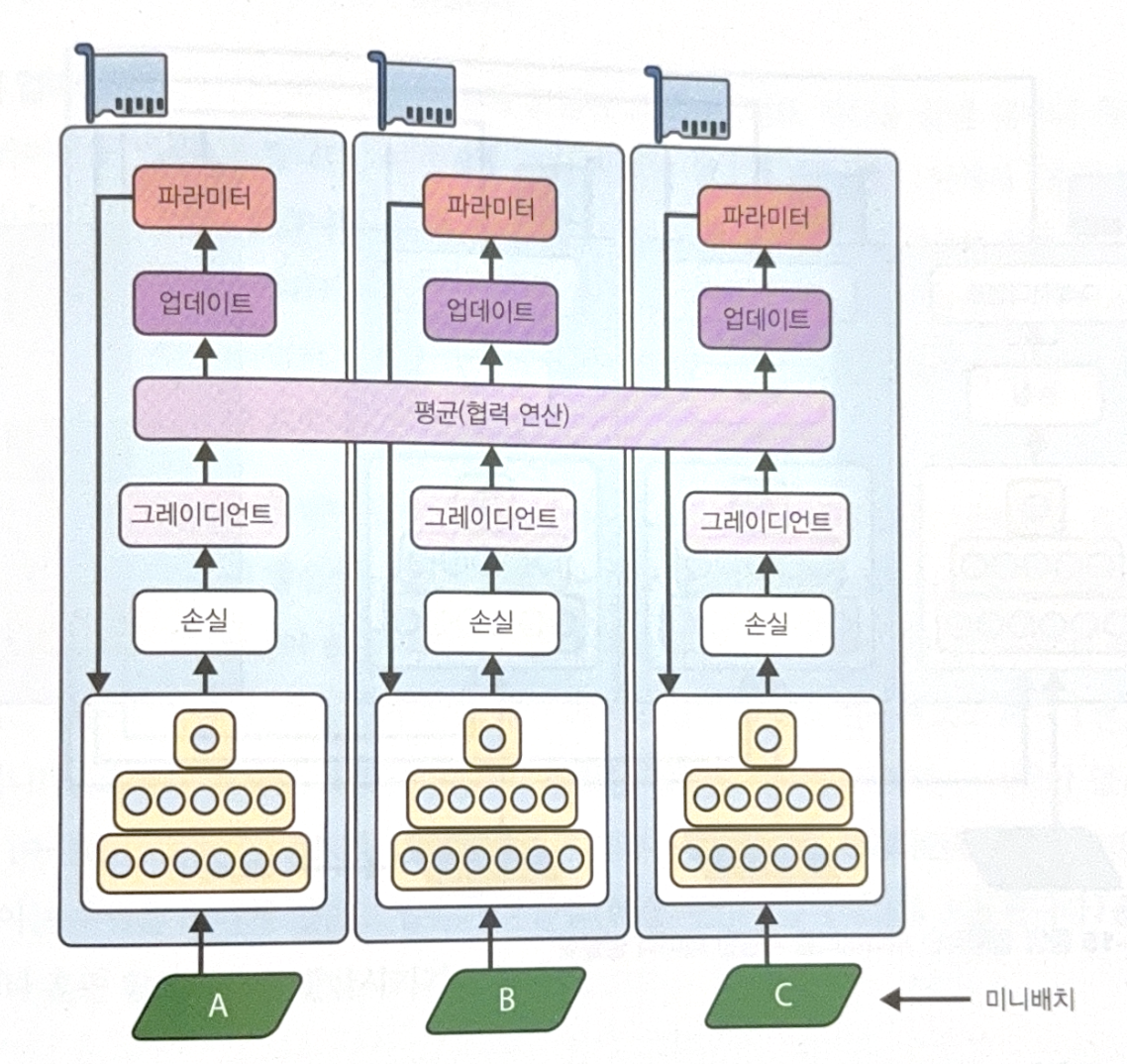
The most tricky part is to efficiently calculate gradient average from all GPUs and distribute the result to all of them. AllReduce algorithms can handle this. The algorithm is that multiple nodes corporates to perform reduce operation(same operation of python reduce, which is useful to calculate average).
Another method is to save model parameter outside of GPU(worker). The parameters are stored in parameter server and updated and distributed only through the server.
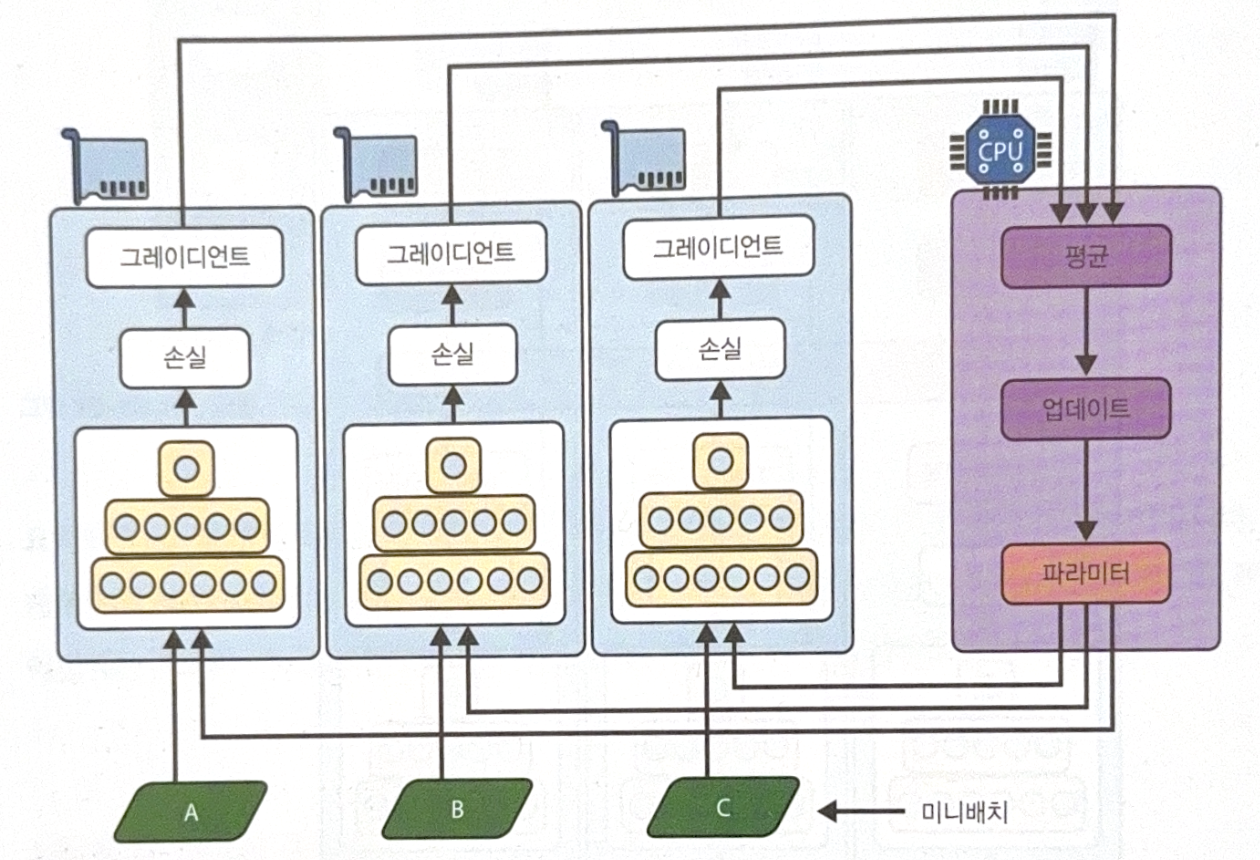
To update the parameters in parameter server, there are two ways, synchronous update and asynchronous update.
Synchronous update
- Waits for all calculations and update parameters at once
- Pros
- Free from stale gradient(see asynchronous update for meaning).
- Cons
- Must wait for slow device for each step.
- As parameters are distributed at the same time, bandwidth may become saturated.
Just looking at the above, asynchronous update seems better. However, there is a critical problem in asynchornous update.
Asynchronous update
- Frequently updates parameters when each model’s calculation ends.
- Pros
- Free from waiting other devices.
- Free from bandwidth saturation.
- Cons
- Stale(old) gradient. If one model already updates the parameters, gradients of the other ones could direct wrong direction in the new point. This could make the training unstable.
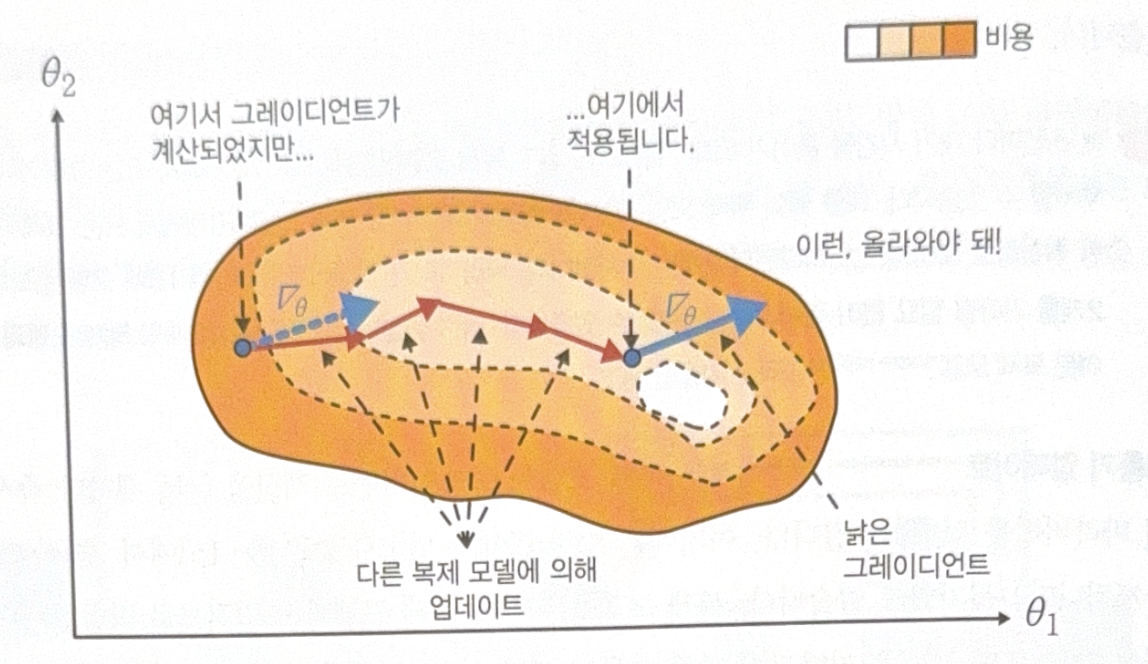
- Stale(old) gradient. If one model already updates the parameters, gradients of the other ones could direct wrong direction in the new point. This could make the training unstable.
There are a few ways to lessen stale gradient(e.g. low learning rate, use one device only for first several epochs), but synchronous update is more efficient than asynchronous one.
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기