
Distributing Model on Mobile or Embedded Devices
Model or embedded devices are usually smaller than powerful GPU servers. Therefore, despite of the strengths of edge computing(computing far from the central server) such as security and unnecessary internet connection, lighter and more efficient model is needed.
TFLite provides multiple tools to achieve following goals.
- Diminish the size of model to decrease downloading time and RAM usage.
- Decrease the computation amount to lessen loading time, battery usage, and heat.
- Fit the model to specific condition of device.
Model transformer of TFLite receives SavedModel and compresses to lightweight format of FlatBuffers. FlatBuffers can be loaded to RAM without any preprocessing. Therefore, it decreases the loading time and memory usage.
Transformer also performs model optimization. For example, batch normalization could be merged to sum and multiplication of the prior layer.
Instead of using smaller(optimized) NN, another way to decreased the size of model is to using smaller bit length. For example, use half-float integer(16bit) instead of single precision(32bit). Accuracy of model will go down, but the size will decrease into half.
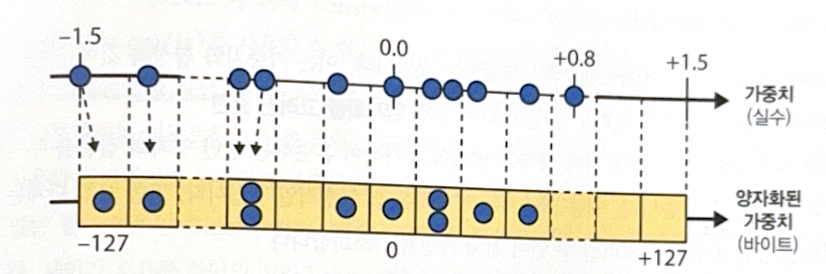
TFLite also compresses the weights of the model into 8-bit integer. The simplest way is post-training quantization. After training, finds the maximum absoulute value m of the weights and maps -m ~ m to -127 ~ 127. 0.0 always maps to 0. The following image is an example of -1.5 to 0.8 mapping.
Activation output can also be quantized. Whereas weight quantization only decrease the size of application, quantizing output of activation decreases response delay and power consumption.
As mentioned, the problem of quantization is sacrificing accuracy. This is similar to adding noise to weights and activation value. If the loss of accuracy is too big, we can do quantization-aware training. By adding fake quantization calculation to the model, we can train the model to ignore quantization noise.
Running Model on Webpage
We can use TFJS library to run model on webpage. We can also convert the website to progressive web app(PWA). TFJS also supports directly training model on web browser!
Using GPU to Speed Up
GPU can speed up calculation. TensorFlow controls GPU as follows.

Managing GPU RAM
Basically, tensorflow secures almost all RAM of GPUs to prevent RAM fragmentation. However, this could cause RAM shortage. There are a several ways to solve the problem.
- Assigning each GPU to one process.
- Making tensorflow occupy only certain size of RAM of GPU. (e.g. 2GiB per GPU)
- Making tensorflow occupy GPU only if necessary.
- Dividing GPU into 2+ logical devices. (e.g. Divide one GPU into 2 to test multi-GPU algorithm.)
For specific codes, see ‘Go for Codes’.
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기