
Distributing Model
After making a machine learning model, we need to distribute it. As there could be complicating tasks (such as real-time data updating), making the model to web service could work better.
The followings are required functions when making a model to a web service.
- Receive query
- Retrain the model regularly and update it.
- Rollback to the prior model if there is an error.
- A/B test
- Upscale the web service to load balance if the model is successful.
To implement the functions above, using TF serving through cloud service is a good way.
Tensorflow Model Serving
The following image is a basic workflow of TF serving.
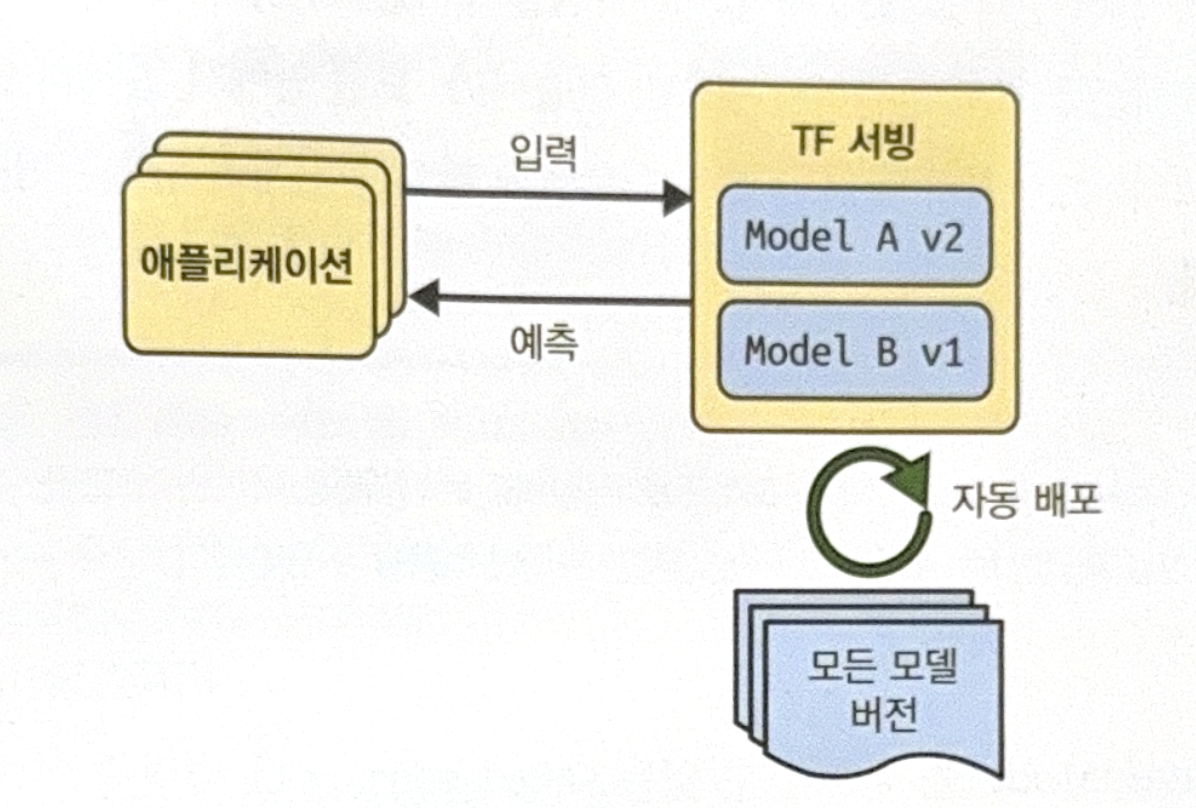
Use TF Serving as following steps.
- Save a model. It is recommended to save preprocessing layers also.
- Install TF serving.
- Query to TF serving using REST API or gRPC API. REST API is simple but not efficient. For big numpy array, use gRPC API.
- If there is a new version of model, save model. TF serving will automatically update regularly.
For specific codes, see ‘Go for Codes’
After the model updated, new request will be processed in a new model. If there is a waiting requests, the old version will process. This will make model switching smoothly, but takes too much RAM. To prevent this problem, you can choose to remove the previous model after processing waiting requests, and then load new model
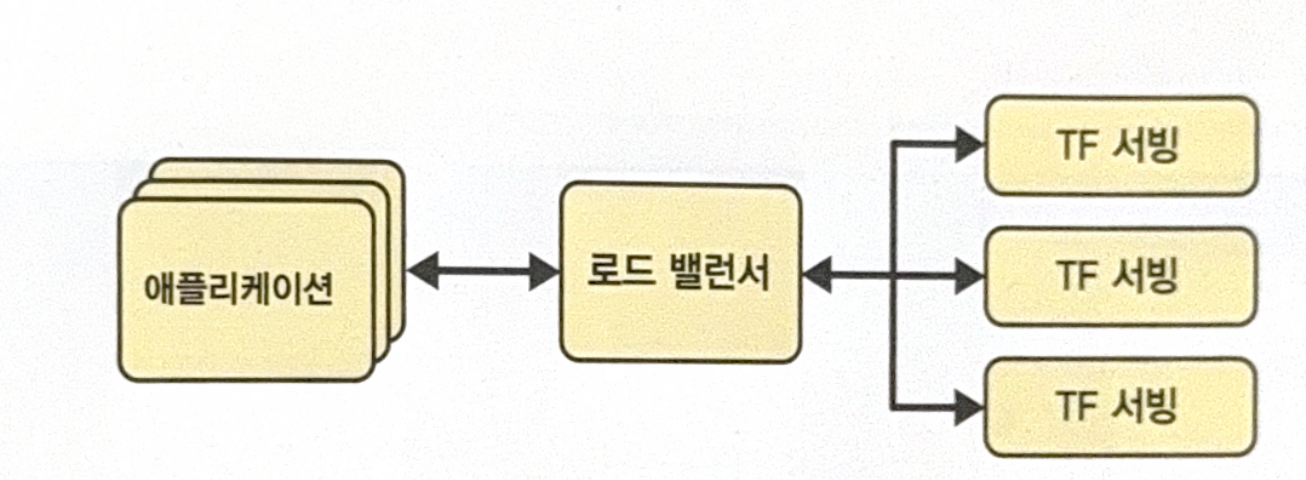
If you predict there would be many queries per second, you can install TF serving in many servers to load balance. To do this use ‘kubernetes’ system or virtual server of cloud services (e.g. AWS, Azure, Google Cloud Platform)
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기