
Reinforcement Learning
In reinforcement learning, an agent does observation and does action under given environment. After then, get reward according to the result.
The reward can be classified into two types. Positive reward and negative reward. Under the environment, the agent will act to maximize the positive reward and to minimize the negative reward.
Of course, there could be no positive or negative reward. For example, escaping maze just has a negative reward for each time step. An agent should escape the maze as soon as possible to minimize the reward.
Policy
All algorithms that an agent uses to determine its action are called policy (e.g. neural network). Policy parameters are the components that can represent the policy. For example, when we control an automatic vacuum machine, progress probability p and rotating angle r can be policy parameters.
To search an appropriate combination of policy parameters, there are 3 ways.
- Randomly testing.
- Genetic algorithm: First, randomly test certain number of combinations. After then, pick the best one and add a little randomness.
- Policy gradient: Evaluate the gradient of award and modify gradient parameters to follow the direction of high reward.
OpenAI Gym: CartPole
OpenAI Gym is a kind of simulation environment. It allows us to simulate variety of environments such as Atari game, board game, and 2D or 3D simulations.
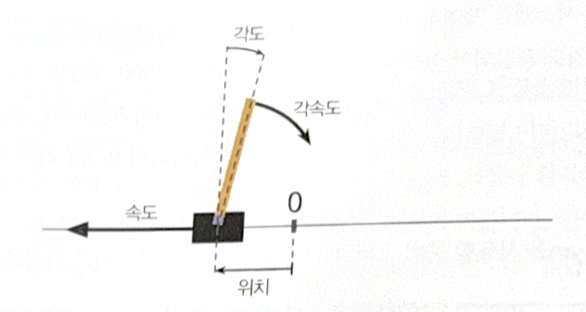
Here, CartPole environment was used. The purpose of the environemt is to control the cart in order not to fall down the stick.
After making an environment, use reset() method to initialize. The method returns an observation and an information. Observation is a 1D array, consisting of ['position of cart', 'velocity of cart', 'angle of stick', 'angular velocity of stick']. Information contains the left number of life, but it is not offered in CartPole.
>>> import gymnasium as gym
>>> env = gym.make("CartPole-v1", render_mode='rgb_array')
>>> obs, info = env.reset(seed=42)
>>> obs
array([ 0.0273956 , -0.00611216, 0.03585979, 0.0197368 ], dtype=float32)
>>> info
{}
By using render(), you can visualize the environment.
There are two possible actions. Going right and going left.
>>> env.action_space # number of possible actions
Discrete(2)
By using step() method, you can move the cart. The method returns 5 values, obs(observation), reward, done(if true, the episode ended), truncated(True if early stopping), and info.
>>> action = 1
>>> obs, reward, done, truncated, info = env.step(action)
>>> obs
array([ 0.02727336, 0.18847767, 0.03625453, -0.26141977], dtype=float32)
>>> reward
1.0
>>> done
False
>>> truncated
False
>>> info
{}
There is a hard-coded policy in ‘Go for Codes’. However the policy is terrible. Therefore, we need a NN policy.
Neural Network Policy
NN policy gets observation as an input and return action as an output. However, the output is not a action with a highest score. It is randomly chosen based on the probability. For example, if action 1 has probability of 0.7 and action 2 has 0.3, the action 1 will be chosen in the probability of 0.7, not 1.
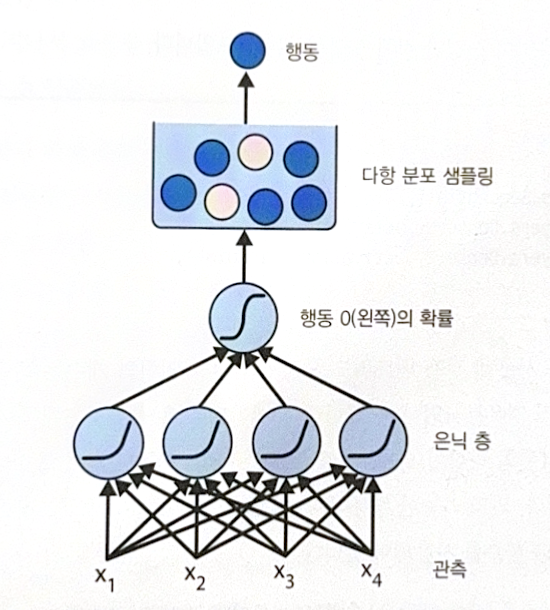
The purpose of that kind of choosing technique is to balance between exploring and exploiting. By allowing randomness, the agent can explore better choice, not relying on one policy.
The following is an example of NN policy. As there are two kinds of output, the number of output neuron is 1.
model = tf.keras.Sequential([
tf.keras.layers.Dense(5, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
In CartPole, actions and observations of the past are ignored. As complete state are included in each observation, the ignorance is fine. However, if there is a omission of a state and you need the state, the past observations could be used to calculate the current state.
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기