
Generative Model
A generative model generates data which is very similar to the train dataset.
There are three representative types of generative model.
- Autoencoder: Learn to copy input to output. Many limitations will make the process difficult.
- GAN: Consists of two NN. Generator generates data similar to train data. Discriminator distinguishs fake data and real data. It is adversarial training, which generator and discriminator compete.
- DDPM(Denoising Diffusion Probabilistifc Model): Trained to remove small noise in the image.
Autoencoder
Autoencoder works as follows.
- Gets inputs.
- Encoder: Change inputs to efficient latent representation.
- Decoder: Change latent representation to output, which is similar to input.
Output is called reconstruction, and cost function imposes penalty to the output which is not similar to its input (reconstruction loss).
The following is a structure of autoencoder.
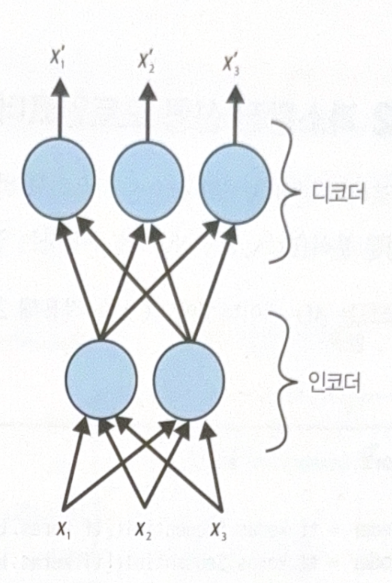
As the latent representation has lower dimension than input, it is called undercomplete. It makes decoder impossible to simply copy the input, and train the important pattern of input.
The following codes is an implementation of undercomplete linear autoencoder with PCA.
encoder = tf.keras.Sequential([tf.keras.layers.Dense(2, input_shape=(3,))]) # No activation function (PCA)
decoder = tf.keras.Sequential([tf.keras.layers.Dense(3)])
autoencoder = tf.keras.Sequential([encoder, decoder])
optimizer = tf.keras.optimizers.SGD(learning_rate=0.5)
autoencoder.compile(optimizer=optimizer, loss='mse')
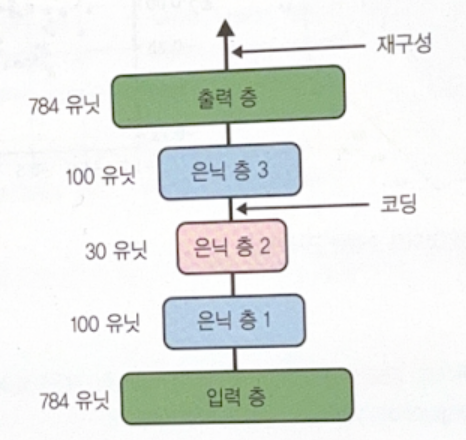
Stacked Autoencoder
Autoencoder with multiple hidden layers is called stacked(deep) autoencoder. In most of case, the structure is symmetric.
# encoder
stacked_encoder = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(30, activation='relu'),
])
# decoder
stacked_decoder = tf.keras.Sequential([
tf.keras.layers.Dense(100, activation='relu'),
tf.keras.layers.Dense(28 * 28),
tf.keras.layers.Reshape([28, 28])
])
# final model
stacked_ae = tf.keras.Sequential([stacked_encoder, stacked_decoder])
# train model
stacked_ae.compile(loss='mse', optimizer='nadam')
history = stacked_ae.fit(X_train, X_train, epochs=20, validation_data=(X_valid, X_valid))
After training, you can use t-SNE to check whether the classification conducted in a right way.
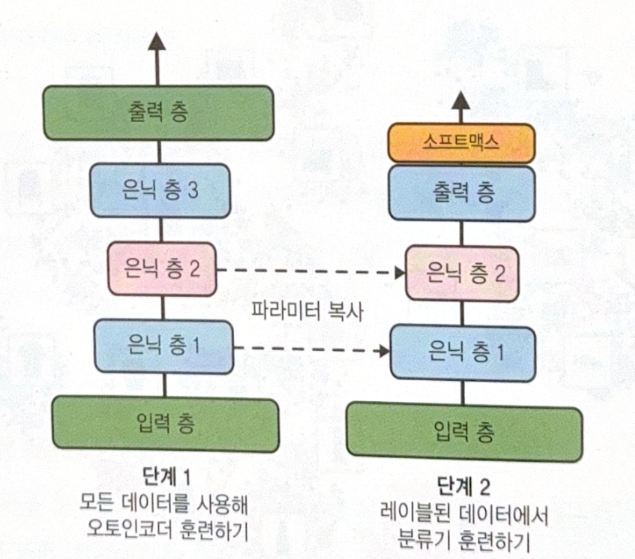
Using pre-trained autoencoder is also possible. First, use all data to train autoencoder, and then train classifier(lower layer are reused) with labeled data.
Tying weights
When the structure of autoencoder is symmetric, tying weights of encoder and decoder is general. This makes the number of trainable parameters in half, which can make training faster. If $W_L$ represents the weight of layer L, decoder weights are defined as $W_L = W_{N-L+1}^T$
To implement this, customized layer is needed.
# customized class
class DenseTranspose(tf.keras.layers.Layer):
def __init__(self, dense, activation=None, **kwargs):
super().__init__(**kwargs)
self.dense = dense
self.activation = tf.keras.activations.get(activation)
def build(self, batch_input_shape):
input_dim = self.dense.kernel.shape[0]
self.biases = self.add_weight(name="bias",
shape=(input_dim,),
initializer="zeros")
super().build(batch_input_shape)
def call(self, inputs):
Z = tf.matmul(inputs, self.dense.kernel, transpose_b=True)
return self.activation(Z + self.biases)
# default dense layer
dense_1 = tf.keras.layers.Dense(100, activation="relu")
dense_2 = tf.keras.layers.Dense(30, activation="relu")
# encoder
tied_encoder = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]),
dense_1,
dense_2
])
# decoder
tied_decoder = tf.keras.Sequential([
DenseTranspose(dense_2, activation="relu"),
DenseTranspose(dense_1),
tf.keras.layers.Reshape([28, 28])
])
# final model
tied_ae = tf.keras.Sequential([tied_encoder, tied_decoder])
Train One Autoencoder At A Time
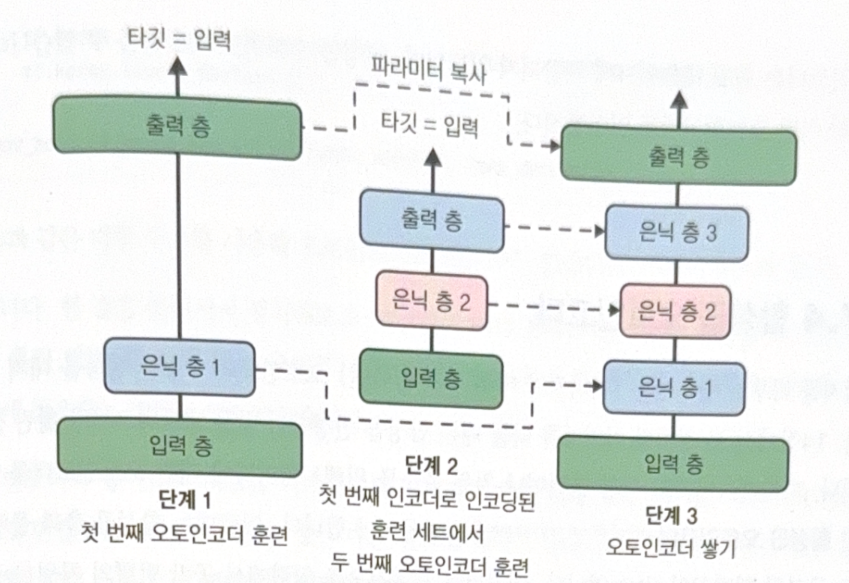
It is also possible to train one autoencoder at a time and stack them to make one stacked autoencoder.
- Train first autoencoder to reconstruct input.
- Make new (conpressed) train set by using autoencoder of step 1.
- Train the second autoencoder with train set of step 2.
- Stack all autoencoders to make entire NN.
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기