
Multi-Head Attention
The basic layer of multi-head attention layer is a scaled dot-product attention layer. It is same as Luong Attention, excluding a scaling parameter.
\[\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_{keys}}})V\]- Q: A matrix including a query for a row. Shape is [$n_{queries}$, $d_{keys}$].
- K: A matrix including a key for a row. Shape is [$n_{keys}$, $d_{keys}$].
- V: A matrix including a value for a row. Shape is [$n_{keys}$, $d_{values}$].
- $QK^T$: One similarity score for each query/key pair.
- $\frac{1}{\sqrt{d_{keys}}}$: A scaling parameter, lowers similarity score to prevent too low gradient.
The following is a structure of a multi-head attention.
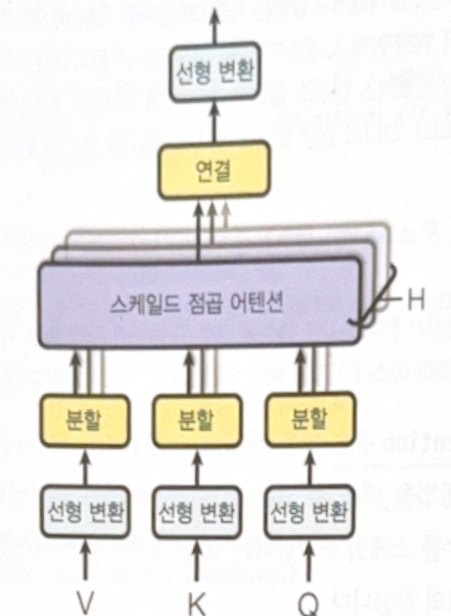
The purpose of the multiple linear transformation is to project the expression of words into the variety of subspaces. If there is only one linear transformation, it could not reflect various informations(e.g. sentence elements, tense, positions). Muiltiples linear transformation will project a word into various subspaces, and the scaled dot-product attention layer will ‘look up’ them.
The following is a code implemetation of a transformer.
# encoder
N = 2
num_heads = 8
dropout_rate = 0.1
n_units = 128
Z = encoder_in
for _ in range(N):
skip = Z
attn_layer = tf.keras.layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate)
Z = attn_layer(Z, value=Z)
Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
skip = Z
Z = tf.keras.layers.Dense(n_units, activation='relu')(Z)
Z = tf.keras.layers.Dense(embed_size)(Z)
Z = tf.keras.layers.Dropout(dropout_rate)(Z)
Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
# decoder
encoder_outputs = Z
Z = decoder_in
for _ in range(N):
skip = Z
attn_layer = tf.keras.layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate
)
Z = attn_layer(Z, value=Z)
Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
skip = Z
attn_layer = tf.keras.layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_size, dropout=dropout_rate
)
Z = attn_layer(Z, value=encoder_outputs)
Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
skip = Z
Z = tf.keras.layers.Dense(n_units, activation='relu')(Z)
Z = tf.keras.layers.Dense(embed_size)(Z)
Z = tf.keras.layers.LayerNormalization()(tf.keras.layers.Add()([Z, skip]))
# output layer
Y_proba = tf.keras.layers.Dense(vocab_size, activation='softmax')(Z)
model = tf.keras.Model(inputs=[encoder_inputs, decoder_inputs], outputs=[Y_proba])
Thanks to the auto-masking of tensorflow, you don’t have to manually make a masking.
GPT
GPT(Generative Pre-Training) model(2018) show the power of pre-training such as ELMo, and ULMFiT. However, the structure is similar to that of transformer. GPT only uses 12 transformer modules with masked multi-head attention layers. And uses self regression of Char-RNN. Then, fine-tuned to the various works(e.g. text classification, entailment, similarity, etc.)
BERT
BERT(Bidirectional Encoder Representations from Transformers, 2019) of Google also shows the effect of pre-training. The structure is similar to GPT, but it uses multi-head attention layers without masking. In other words, the model has bidirectionalily. There are two pre-training that shows the strength of the model.
- Masked Language Model (MLM): Mask a work for 15% probability. Train the model to predict the masked word.
- Next Sentence Prediction (NSP): Train the model to predict whether two sentences are consecutive or not.
Additional tokens(<SEP>) are needed between two sentences to train NSP. Segment embedding are also needed for each token to represent from which sentence the word came.
Loss is only calculated with respect to the NSP and masked tokens, not for unmasked tokens.
The model is first pre-trained in large corpus and fine-tuned in various works.
GPT-2
GPT-2 is similar to GPT, but it uses much bigger model(much larger number of parameters). It reached great performance in many works without fine-tuning (zero-shot learning, ZSL).
It was a starting point of giant model.
DistilBERT
DistilBERT is a small and fast transformer model based on BERT. It uses distillation method, transferring knowledge from teacher model to student model. It usually uses the predict probability of teacher model as a target of a student model.
PaLM
PaLM(Pathways Language Model) was trained in Pathways, a new giant training platform of Google. It is a standard transformer model with a few modifications in decoder.
The great performance of the model is partially the results of its size, it is also the result of chain of thought prompting technology. Chain of thought prompting shows the process of the result derivation, such as calculation formulas.
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기