
Sentiment Analysis
Sentiment analysis is to decide the sentence is possitive or negative.
In sentimant analysis, split sentences by a word, not a character. However, astf.keras.layers.TextVectorization uses spaces to split words, it would not work well on some languages such as Chinese.
There are two solutions.
- Byte Pair Encoding (BPE): Split whoel train set into individual characters (including spaces) and repeatedly merge the most frequent adjacent pairs.
- Subword Regularization
In IMDb dataset, it is enough to use spaces to split words. The following an example model, which limits the vocabulary size.
vocab_size = 1000
text_vec_layer = tf.keras.layers.TextVectorization(max_tokens=vocab_size)
text_vec_layer.adapt(train_set.map(lambda review, label: review))
embed_size = 128
tf.random.set_seed(42)
model = tf.keras.Sequential([
text_vec_layer,
tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embed_size),
tf.keras.layers.GRU(128),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="nadam", metrics=["accuracy"])
history = model.fit(train_set, validation_data=valid_set, epochs=2)
However, the model does not work well. The accuracy is close to 50%! The major cause is padding tokens. As the short sentences are lengthened by multiples of padding tokens to make the length same as the longest one, GRU will forget the long-term memory after many paddings.
A solution is to make RNN ignore padding tokens. ‘Masking’ will help.
Masking
To make a model ignore padding tokens, set mask_zero=True when making an Embedding layer.
The following is the process of masking.
- Make a boolen tensor, which is called mask tensor, with a same size as inputs. The position where ID is 0 will be False, the others are True.
- Deliver the mask tensor to the next layer.
- Receive the mask if there is a
maskparameter incall()method. - Ignore specific time step. For example, simply copy the output of the prior time step when meet masked time step.
- If
supports_masking=Trueat the layer, the mask will be delivered to the next layer automatically. To do this,return_sequencesshould also be True.
To implement customized layer with masking, add mask parameter to call() method and use mask at the method.
If a model doesn’t start with an embedding layer, you can use tf.keras.layers.Masking instead.
In a complex model, which has Conv1D layer also, it is difficult to use automatilcally delivered masking. You should use functinal API or subclassing API to calculate a mask and deliver to the appropirate layer.
class MaskingLayer(tf.keras.layers.Layer):
def call(self, token_ids):
return tf.math.not_equal(token_ids, 0)
# manually masking
tf.random.set_seed(42)
inputs = tf.keras.layers.Input(shape=[], dtype=tf.string)
token_ids = text_vec_layer(inputs)
mask = MaskingLayer()(token_ids)
Z = tf.keras.layers.Embedding(vocab_size, embed_size)(token_ids)
Z = tf.keras.layers.GRU(128, dropout=0.2)(Z, mask=mask)
outputs = tf.keras.layers.Dense(1, activation="sigmoid")(Z)
model = tf.keras.Model(inputs=[inputs], outputs=[outputs])
The last processing method to masking is to inject a ragged tensor to a model. Set ragged=True in TextVectorization layer to represent input sequence as a ragged tensor.
>>> text_vec_layer_ragged = tf.keras.layers.TextVectorization(max_tokens=vocab_size, ragged=True)
>>> text_vec_layer_ragged.adapt(train_set.map(lambda review, label: review))
>>> text_vec_layer_ragged(['Great movie!', "This is DiCaprio's best role."]) # ragged tensor
<tf.RaggedTensor [[86, 18], [11, 7, 1, 116, 217]]>
>>> text_vec_layer(['Great movie!', "This is DiCaprio's best role."]) # normal tensor
<tf.Tensor: shape=(2, 5), dtype=int64, numpy=
array([[ 86, 18, 0, 0, 0],
[ 11, 7, 1, 116, 217]])>
Use Pre-trained Embedding and Reuse Language Model
You can use pre-trained embeddings such as Word2Vec, GloVe, FastText. As the most of words have similar meaning in differnet sentences, other embeddings which are trained for another problems could be used for sentimental analysis.
However, there is also limitations. It is difficult to distinguish homonyms (e.g. ‘left and right’, ‘right and wrong’). To solve this ELMo(Embeddings from Language Models) was invented. It also considers context. There is another method called ULMFiT(Universal Language Model Fine-Tuning) which uses unsuperviesed pre-training in large corpus with LSTM.
The following is a code to use Universal Sentence Encoder as a pre-trained model.
import os
import tensorflow_hub as hub
os.environ['TFHUB_CACHE_DIR'] = 'my_tfhub_cache'
model = tf.keras.Sequential([
hub.KerasLayer("https://tfhub.dev/google/universal-sentence-encoder/4",
trainable=False, dtype=tf.string, input_shape=[]),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
model.compile(loss="binary_crossentropy", optimizer="nadam", metrics=["accuracy"])
history = model.fit(train_set, validation_data=valid_set, epochs=10)
Neural Machine Translation (NMT)
Simpel NMT which translates english to spanish has a following structure.
- Inject an english sentence to encoder.
- Return a spanish sentence.
- Use the returned spanish sentence as an input to a decoder ‘one step behind’. In other words, decoder doesn’t care about what really returned, and use ‘what should be returned in the previous step’ as an input. (teacher forcing)
- For each step, decoder prints the score of words in a spanish corpus.
- Softmax will change the score into the probability.
Decoder gets SOS(start-of-sequence) token as the first word, and expect EOS(end-of-sequence) token at the last of the sentence.
During prediction, there is no sentence to inject to decoder(because there is no target sentence). Instead, inject the prior output of decoder.
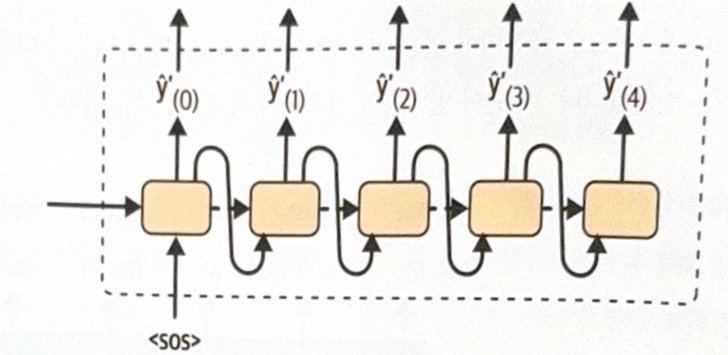
Let’s build a model. After parsing and shuffling, two TextVectorization model are needed for each language.
vocab_size = 1000
max_length = 50 # max length of sentence in a dataset
text_vec_layer_en = tf.keras.layers.TextVectorization(vocab_size, output_sequence_length=max_length)
text_vec_layer_es = tf.keras.layers.TextVectorization(vocab_size, output_sequence_length=max_length)
text_vec_layer_en.adapt(sentences_en)
text_vec_layer_es.adapt([f"startofseq {s} endofseq" for s in sentences_es]) # for spanish, add SOS and EOS
As the model is not sequential, we use functional API.
We need two text inputs, one for encoder and the other for decoder. And encode the sentences use TextVectorization layer.
# prepare inputs
encoder_inputs = tf.keras.layers.Input(shape=[], dtype=tf.string)
decoder_inputs = tf.keras.layers.Input(shape=[], dtype=tf.string)
# encoding
embed_size=128
encoder_inputs_ids = text_vec_layer_en(encoder_inputs)
decoder_inputs_ids = text_vec_layer_es(decoder_inputs)
encoder_embeddings_layer = tf.keras.layers.Embedding(vocab_size, embed_size, mask_zero=True)
decoder_embeddings_layer = tf.keras.layers.Embedding(vocab_size, embed_size, mask_zero=True)
encoder_embeddings = encoder_embeddings_layer(encoder_inputs_ids)
decoder_embeddings = decoder_embeddings_layer(decoder_inputs_ids)
Then, deliver embedded inputs to encoder.
# encoder
encoder = tf.keras.layers.LSTM(512, return_state=True)
encoder_outputs, *encoder_state = encoder(encoder_embeddings)
# decoder
decoder = tf.keras.layers.LSTM(512, return_sequences=True)
decoder_outputs = decoder(decoder_embeddings, initial_state=encoder_state)
# get probability
output_layer = tf.keras.layers.Dense(vocab_size, activation="softmax")
Y_proba = output_layer(decoder_outputs)
After compiling and training, the model will work.
However, making a prediciton is not simple. It would not work by calling model.predict(). As decoder expects the predicted word of the prior step as an input, we can build a customized memory cell that records the previous outputs, or call model multiple times and predict one word more for each step.
The following function repeatedly predicts one word at a time and stop when meet EOS.
def translate(sentence_en):
translation = ''
for word_idx in range(max_length):
X = np.array([sentence_en])
X_dec = np.array(['startofseq ' + translation])
y_proba = model.predict((X, X_dec))[0, word_idx]
predicted_word_id = np.argmax(y_proba)
predicted_word = text_vec_layer_es.get_vocabulary()[predicted_word_id]
if predicted_word == 'endofseq':
break
translation += ' ' + predicted_word
return translation.strip()
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기