
Character(Char)-RNN: Prepare Dataset
Character(Char)-RNN predicts the next one word at a time.
To train Char-RNN, use TextVectorization layer. Set split='character' to do chacater-level encoding instead of word-level encoding.
text_vec_layer = tf.keras.layers.TextVectorization(split='character', standardize='lower')
text_vec_layer.adapt([shakespeare_text])
encoded = text_vec_layer([shakespeare_text])[0]
Also, to count the number of unique words, ignore token 0(padding), and token 1(unknown).
encoded -= 2
n_tokens = text_vec_layer.vocabulary_size() - 2 # the number of unique tokens
dataset_size = len(encoded)
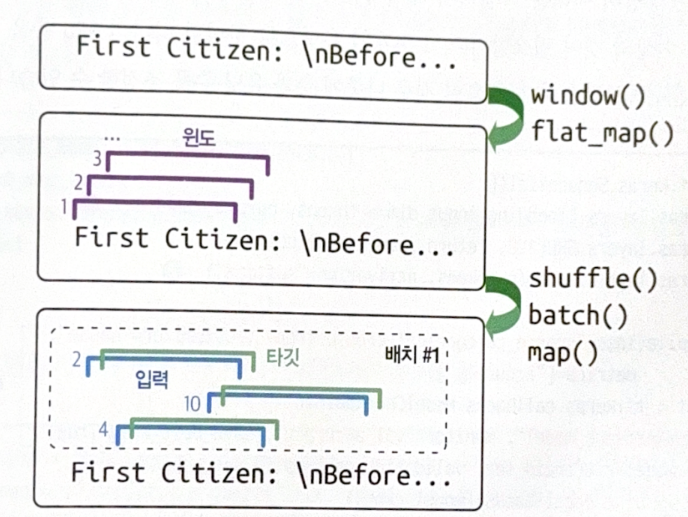
Then, change dataset to window dataset. Target is similar to input, but move one character forward (e.g. ‘to be or not to b’ -> ‘o be or not to be’).
The following codes plays the role.
- Get a sequence as an input and make a dataset that contains all windows.
- Increase length by 1 to get a next character for a target.
- Shufffle, batch, split, and activate prefetch.
def to_dataset(sequence, length, shuffle=False, seed=None, batch_size=32):
ds = tf.data.Dataset.from_tensor_slices(sequence)
ds = ds.window(length+1, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda window_ds: window_ds.batch(length + 1))
if shuffle:
ds = ds.shuffle(buffer_size=100_000, seed=seed)
ds = ds.batch(batch_size)
return ds.map(lambda window: (window[:, :-1], window[:, 1:])).prefetch(1)
Char-RNN: Model and Train
The following is a model with a GRU layer.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=n_tokens, output_dim=16),
tf.keras.layers.GRU(128, return_sequences=True),
tf.keras.layers.Dense(n_tokens, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam",
metrics=["accuracy"])
model_ckpt = tf.keras.callbacks.ModelCheckpoint(
"my_shakespeare_model.keras", monitor="val_accuracy", save_best_only=True)
history = model.fit(train_set, validation_data=valid_set, epochs=10,
callbacks=[model_ckpt])
- Embedding: Input dimension is the number of unique character. The output dimension could be regulated manually.
- Dense: As we expect probabilities for all unique tokens, set the number of units as
n_tokens.
The model does not contain preprocessing, so the following is a final model.
shakespeare_model = tf.keras.Sequential([
text_vec_layer,
model,
tf.keras.layers.Lambda(lambda X: X - 2),
model
])
Generate Fake Text
If you want to make a fake text by the model above, you can simply repeat the model (Get a text, use it as an input and so on). However, there is a high likelihood that the same character is repeating.
To solve this, we can use tf.randon.categorical() function and choose a random character from the predicted probability. categorical() will randomly sample class indexes when we deliver a logistic probability.
>>> log_probas = tf.math.log([[0.5, 0.4, 0.1]]) # probability 0.5, 0.4, 0.1
>>> tf.random.set_seed(42)
>>> tf.random.categorical(log_probas, num_samples=8) # pick 8 samples
<tf.Tensor: shape=(1, 8), dtype=int64, numpy=array([[0, 0, 1, 1, 1, 0, 0, 0]])>
To allow more variety to the text, divie a logit by a ‘temperature’ value.
def next_char(text, temperature=1):
y_proba = shakespeare_model.predict([text])[0, -1:]
rescaled_logits = tf.math.log(y_proba) / temperature
char_id = tf.random.categorical(rescaled_logits, num_samples=1)[0, 0]
return text_vec_layer.get_vocabulary()[char_id + 2]
Low temperature will pick a character with a high probability. Therefore, if you want to make a creative text, set temperature high.
To avoid weird text, you can sample from top-k text or text above specific threshold (nucleus sampling).
Stateful RNN
The model we used until now is a stateless RNN. It initializes the hidden state to 0 for each iteration. Therefore, it is not appropriate to train a long sequence.
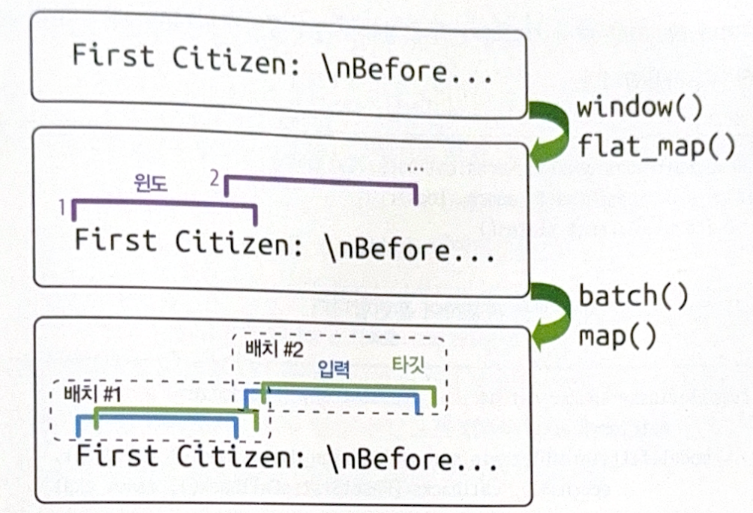
Instead, a stateful RNN use the last state after a batch processing as an initial state for the next batch. This allows to learn the long pattern.
The most important point to use a statefull RNN is to make a correct dataset. Each input sequence in a batch should start at a point right after the prior sequence. Don’t use shuffle(), and set shift=n_steps in window() method.
It is tricky to form a batch. For example, it you call batch(32), it will include 32 consecutive windows in a batch (1~32, 33~64). The first window of each batch is not consecutive. A solution is to use a batch size 1.
def to_dataset_for_stateful_rnn(sequence, length):
ds = tf.data.Dataset.from_tensor_slices(sequence)
ds = ds.window(length + 1, shift=length, drop_remainder=True)
ds = ds.flat_map(lambda window: window.batch(length + 1)).batch(1)
return ds.map(lambda window: (window[:, :-1], window[:, 1:])).prefetch(1)
The following is a stateful model. Set stateful=True.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=n_tokens, output_dim=16),
tf.keras.layers.GRU(128, return_sequences=True, stateful=True),
tf.keras.layers.Dense(n_tokens, activation="softmax")
])
It is required to reset states at the end of epoch, before the text starts again.
class ResetStatesCallback(tf.keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs):
self.model.reset_states()
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기