
Handling Long Sequence
There are two major problems when handling a long sequence.
- Unstable Gradient
- Forgetting the first part of input
Let’s look at the problem one by one.
Unstable Gradient: Layer Normalization
There are many solutions to solve unstable gradient, such as weights initialization, fast optimizers, and dropout.
However, an activation function that does not converge (e.g. ReLU) could not help. That’s why we use tanh as a default.
We can also use batch normalization, but there are constraints. You can only use the batch normalization between the two recurrent layers, and not between the time step. Training rate will slow down and the effect is not satisfactory.
Instead of batch normalization, you can use layer normalization. Layer normalization normalizes with respect to feature dimension instead of batch dimension. Unlike batch normalization, it dynamically calculates statistics for each time step independent to samples. This allows the same process in train and test.
The following code is about making a memory cell class with layer normalization.
class LNSimpleRNNCell(tf.keras.layers.Layer):
def __init__(self, units, activation="tanh", **kwargs):
super().__init__(**kwargs)
self.state_size = units
self.output_size = units
self.simple_rnn_cell = tf.keras.layers.SimpleRNNCell(units, activation=None)
self.layer_norm = tf.keras.layers.LayerNormalization()
self.activation = tf.keras.activations.get(activation)
def call(self, inputs, states):
outputs, new_states = self.simple_rnn_cell(inputs, states)
norm_outputs = self.activation(self.layer_norm(outputs))
return norm_outputs, [norm_outputs]
call() method has two outputs, one is the current output and the other is a new hidden state.
To implement dropout, use dropout(ratio for input) or recurrent_dropout(ratio for hidden state between time step) parameters in keras recurrent layer (no need to define a class).
Short Memory: LSTM, GRU
Long Short-Term Memory(LSTM) is the most popular long term memory cell. The image below shows the structure of LSTM.
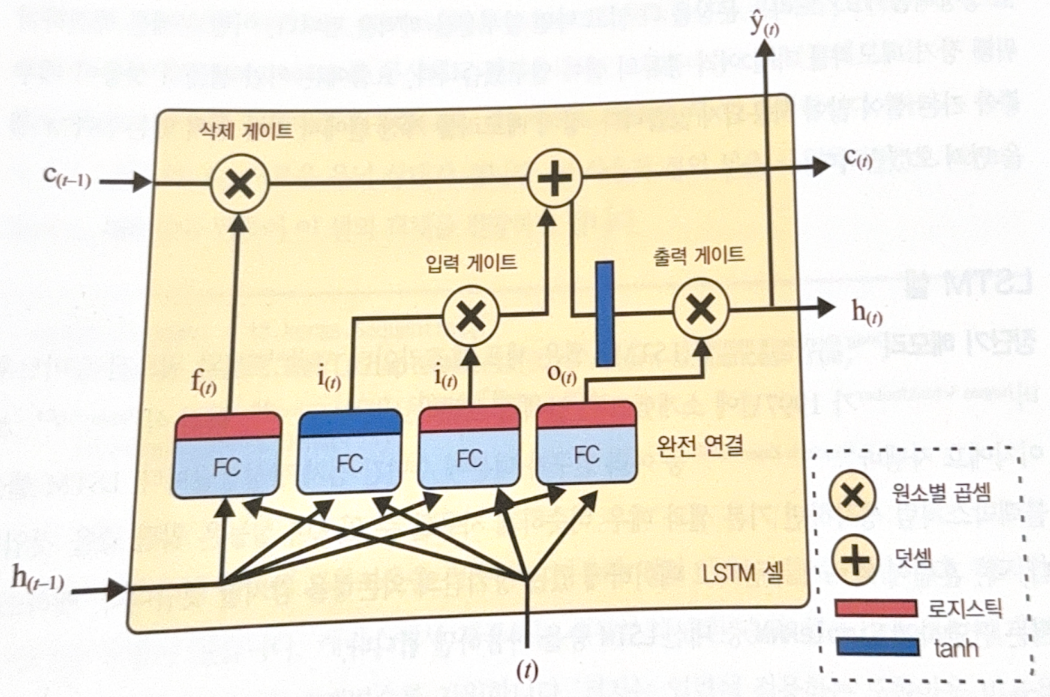
The main idea is that the network learn what to store in long-term state, what to remove, and what to read.
Let’s look at each part one by one.
-
$\mathbf{c}_{(t-1)}$ is a long-term memory.
- Passes forget gate and lose a part of memory.
- Passes sum calculation and get a newly selelcted memory.
- Generated $\mathbf{c}_{(t)}$ , which directs to the output without further transformation.
- Result of step 2 is duplicated, and tranferred to tanh. It passes output gate make short-term state $\mathbf{h}_{(t)}$
-
Current input vector $\mathbf{x_{(t)}}$, and short-term state of the previous step $\mathbf{h}_{(t-1)}$
Injected to 4 different fully connected layers.
- One main layer returns $\mathbf{g_{(t)}}$. The output will go to sum calculation of $\mathbf{c_{(t-1)}}$.
- The other 3 layers use sigmoid functions. They are called gate controller. From the left, each one is connected to a forget gate, input gate, and output gate. As they are connected to element-wise product, 0 will close the gate, and 1 will open the gate.
To be simple, LSTM cell recognizes important inputs(input gate), save at the long-term state, preserve for a period(forget gate), and extract whenever needed.
Gated Recurrent Unit(GRU) is one of the most popular variation of LSTM. It is a simplified version of LSTM.
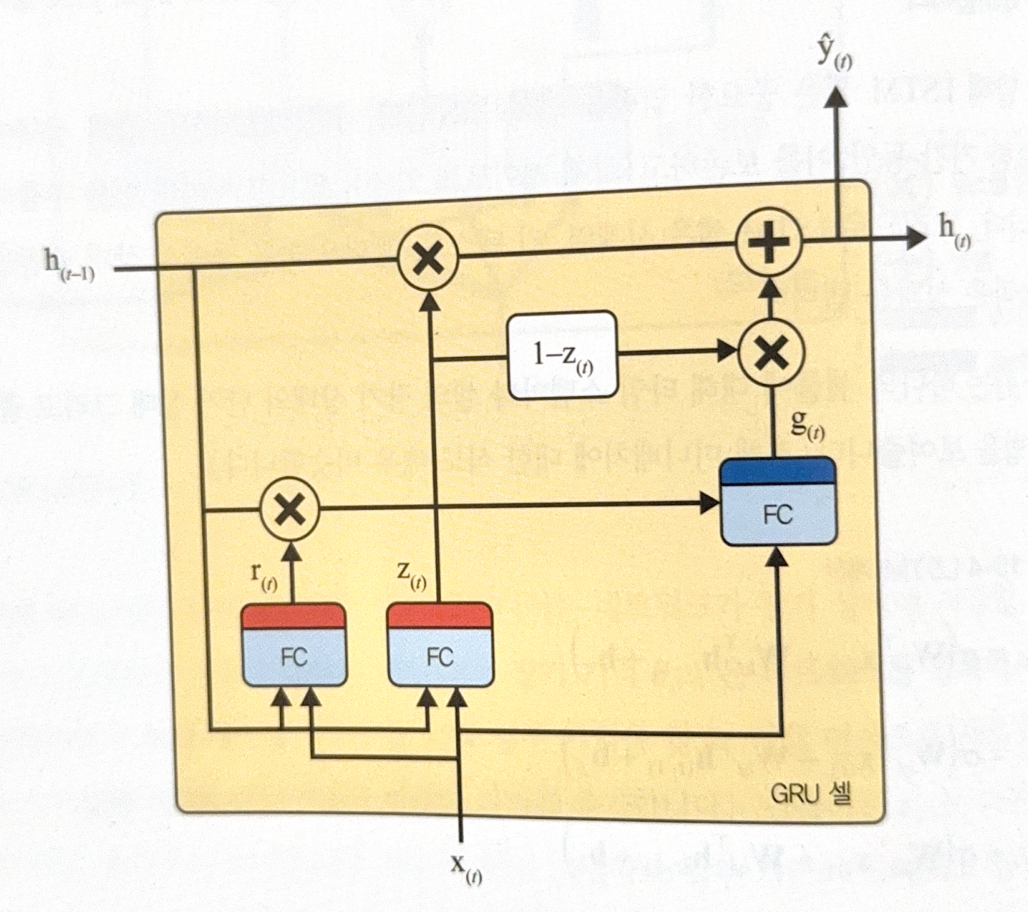
The followings are differences of GRU to LSTM.
- Two state vector is merged into one $\mathbf{h}_{(t)}$
- One gate controller $\mathbf{z}_{(t)}$ controls both forget gate and input gate. If gate controller returns 1, forget gate opens and input gate closes, and if 0, vice versa. In other words, whenever the memory is saved, the position to save is removed first.
- No output gate. Therefore, whole state vector is returned for each time step. There are a new gate controller $\mathbf{r_{(t)}}$ to regulate which part will be revealed to the main layer $\mathbf{g}_{(t)}$.
There are also another ways to deal with short memory, 1D Conv layer and WaveNet.
1D Conv Layer
Similar to image recognition, 1D convolutional layer slides a few kernels through a sequence to return 1D feature map for each kernel. If you use ‘same’ padding, length of output sequence will be same as input. However, if you use ‘valid’ padding with 2+ stride, output sequence will be shorter than input.
In the following code, the size of kernel is bigger than the stride. Therefore, the kernel will overlap. All elements will be considered.
tf.random.set_seed(42)
conv_rnn_model = tf.keras.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=4, strides=2,
activation="relu", input_shape=[None, 5]),
tf.keras.layers.GRU(32, return_sequences=True),
tf.keras.layers.Dense(14)
])
longer_train = to_seq2seq_dataset(mulvar_train, seq_length=112,
shuffle=True, seed=42)
longer_valid = to_seq2seq_dataset(mulvar_valid, seq_length=112)
downsampled_train = longer_train.map(lambda X, Y: (X, Y[:, 3::2]))
downsampled_valid = longer_valid.map(lambda X, Y: (X, Y[:, 3::2]))
The model uses stride 2 to downsample input sequence by an half. This makes GRU to recognize long pattern.
WaveNet
WaveNet stacks 1D Conv layers that doubles the dilation rate(interval of input neurons).
For example, the first Conv layer looks at only two time step. The next layer looks at 4 time step, and for the next, 8 steps.
By this structure, lower layers learn short-term pattern, and the upper layers learn long-term pattern. Long sequence will be handled efficiently.
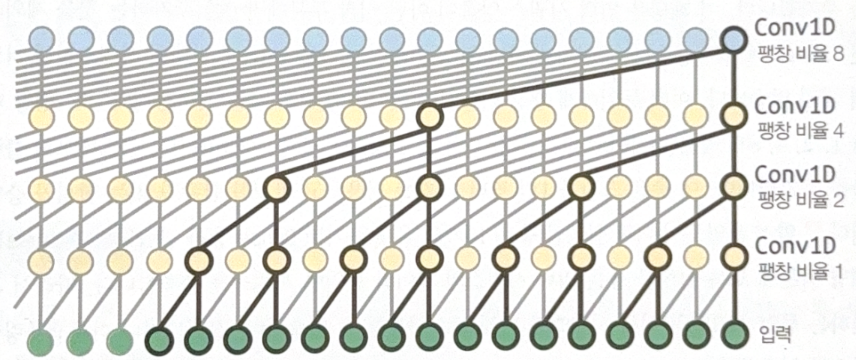
wavenet_model = tf.keras.Sequential()
wavenet_model.add(tf.keras.layers.Input(shape=[None, 5]))
for rate in (1, 2, 4, 8) * 2: # dilation rate
wavenet_model.add(tf.keras.layers.Conv1D(filters=32, kernel_size=2, padding='causal', activation='relu', dilation_rate=rate))
wavenet_model.add(tf.keras.layers.Conv1D(filters=14, kernel_size=1))
‘casual’ padding only adds 0 to the starting poing of a sequence. This will prevent Conv layer to look at future sequenve while making a prediction.
All images, except those with separate source indications, are excerpted from lecture materials.
댓글남기기