
Object Detection
The most widely used object detection method until a few years ago was as follows.
- Train a CNN that recoginzes an object in the center of the image.
- Scan over the image with the CNN. The CNN will return objectness score, a probability whether there are an image in the center or not.
- Each CNN will be a bounding box.

However, same object could be detected multiple times. Therefore, NMS(Non-Max suppression) is used to remove unneccessary bounding boxes.
- Remove all bounding boxes which has lower probability than a threshold.
- Find a bounding box with the highest score. Remove the other overlapped(IoU $\geq$ 60%) boxes to the box.
- Repeat step 2 until there are no more box to remove.
This simple method works fine, but slow. We can slides CNN to image faster by using Fully Convolutional Network(FCN).
Fully Convolutional Network
FCN changes the highest dense layer of CNN to convolutional layer. By using a convolutional layer which has the same size with feature maps, the return would be 1 by 1 layers in the number of feature maps(‘valid’ padding was used).
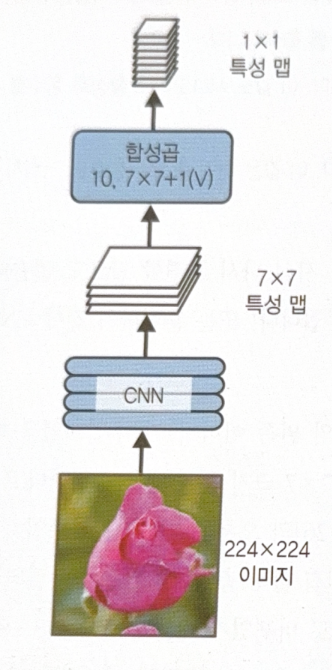
FCN could handle any size of images because there are no dense layers.
There would be 10 output numbers if 10 filters are used. The numbers mean 5 class probabilities, 1 objective score, 4 bounding box info.

When larger image is injected to the same NN which handled the small size, the output feature maps would be larger than the former(small size image) result. Each cell(same position across feature maps) has 10 numbers(5 class probabilities, 1 objective score, 4 bounding box info). FCN scans the image only once, faster than the original CNN. As it looks at the image once, it is called YOLO(You Only Look Once).
YOLO
YOLO is so fast that it could be applied to live video. YOLOv3 has a few important difference to the former structure.
- YOLO only considers objects that the center of bounding box is in the grid cell.
- Print two(not one) bounding boxes for each grid cell. This can handle closely adjacent objects, whose centers are in one grid cell.
- YOLO prints the distribution of class probability for each grid cell(not a bounding box). This makes rough class probability map. When post-processing to estimate How well each bounding box fits a class in the class probability map, we can estimate the probability of each bounding box.
mAP(mean Average Precision)
mAP is widely used metircs for object detection. In precision/recall curve, there is a part where precision and recall increase in the same time, especially when the recall is low. The better way to measure the performance of model is to calculate the max precision at 0%, 10%, 20%… to 100% recall and average them. This is Average Precision(AP). When there are more than two classes, mean their AP, this is mAP.
In object detection, we have to also consider IoU. ‘mAP@0.5’ means ‘IoU $\geq$ 50 and right class’.
Object Tracking
Object tracking is tricky. An object could move, get bigger or smaller according to the position, change according to the light or background.
The most widely used system is DeepSORT. It works as follows.
- Assume that an object moves in constant speed. Use Kalman filter to assume the most likely current position of the previous detected object.
- Use deep learning to measure the similarity between the new result and the existing tracking object.
- Use Hungarian algorithm to map the new object to the existing one. The algorithms considers distance and appearance at the same time.
Thanks to Hungarian algorithm, we can consider distance and appearance at the same time, better than just considering distance.
Semantic Segmentation
Semantic segmentation is to classify pixels to each object. However semantic segmentation is difficult because we gradually lose position info, when we use CNN. Therefore in most cases, we could roughly know the position of an object but that is the limitation.
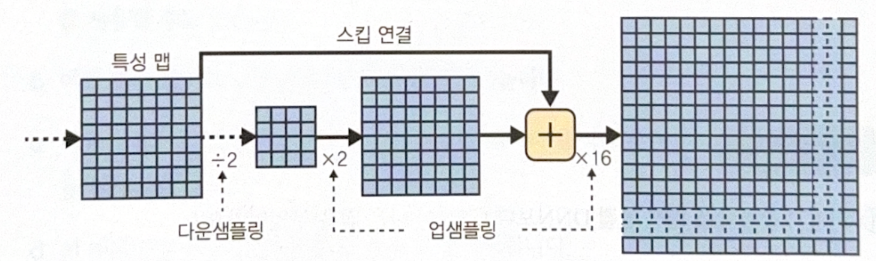
Simply upscaling images by adding an upscaling layer could solve this. There are many upscaling methods.
- bilinear interpolation: Appropirate to upscale by 4 or 8 times.
- transposed convolutional layer: Add empty rows and columns(filled with 0) to the image. Perform typical convolution. In keras, use
Conv2DTranspose.
Using transposed convolutional layer is a good solution but precision is still not satisfactory. By adding skip connection in the lower part of the structure, lost info could be recovered partially. Upscaling larger than the original image is also possible(super-resolution).
Computer vision is advancing rapidly. Almost all structures are based on CNN, except ‘transformer’.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기