
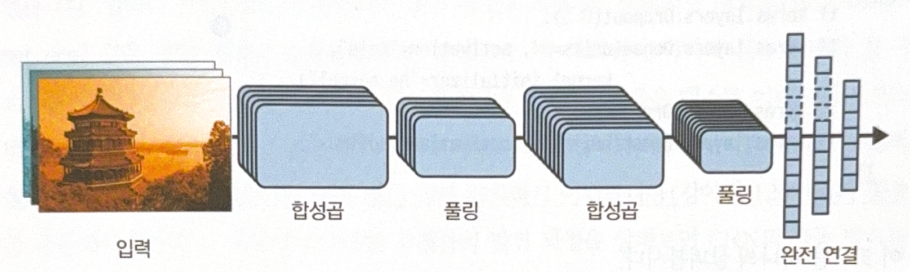
Basic CNN
Basic structure of CNN is as follows.
from functools import partial
DefaultConv2D = partial(tf.keras.layers.Conv2D, kernel_size=3, padding='same',
activation='relu', kernel_initializer='he_normal')
model = tf.keras.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
tf.keras.layers.MaxPool2D(),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
tf.keras.layers.MaxPool2D(),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
tf.keras.layers.MaxPool2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=128, activation='relu',
kernel_initializer='he_normal'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=64, activation='relu',
kernel_initializer='he_normal'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(units=10, activation='softmax'),
])
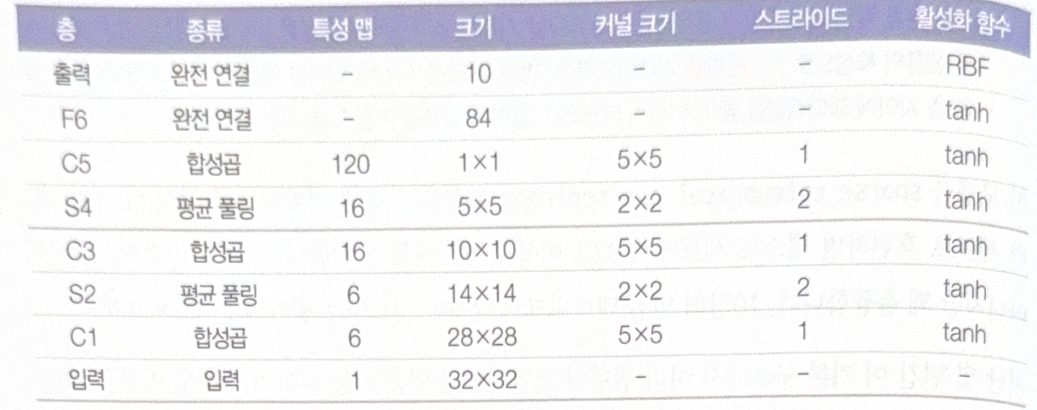
LeNet-5
LeNet-5 is the most well-known CNN structure. It has a following structure.
AlexNet
AlexNet is deeper than LeNet-5, but the basic structure is similar. The big difference is that CNN layers come right behind the other CNN layers.
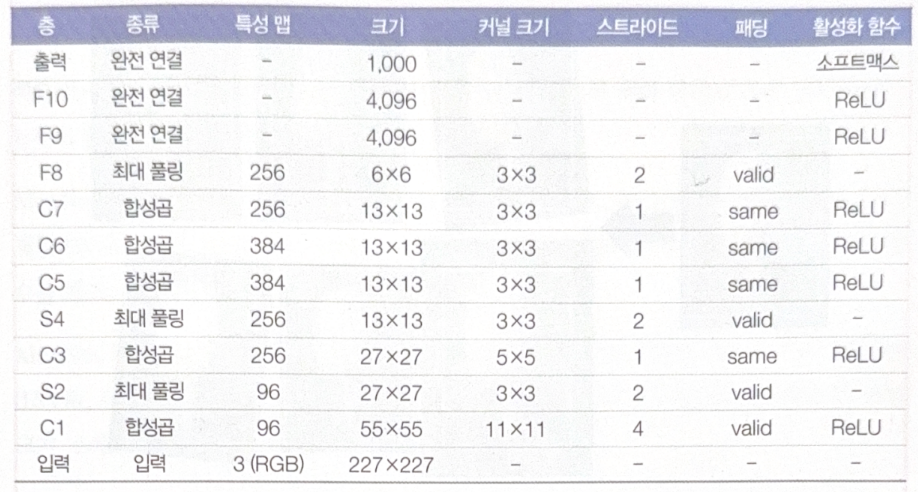
To prevent overfitting, dropout and data augmentation were used.
Data augmentation is a method to increase the size of train set, by rotating, shifting images. Just adding white noise is not a data augmentation.
AlexNet also used LRN(Local Response Normalization) step, which is a competitive normalization. The most powerfully activated neuron suppresses other neurons at the same point of different feature maps. This would make each feature map unique relative to the others.
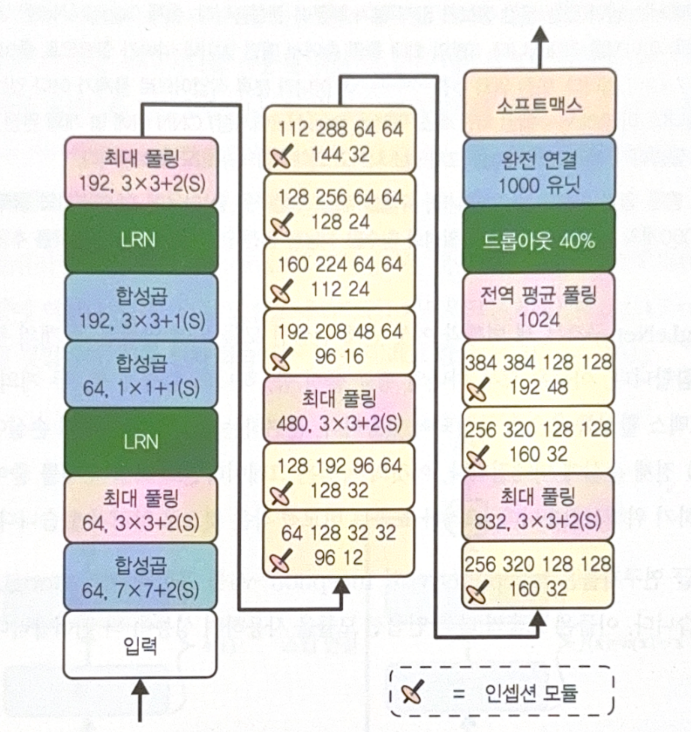
GoogLeNet
The most important characteristic of GoogLeNet is an inception module.
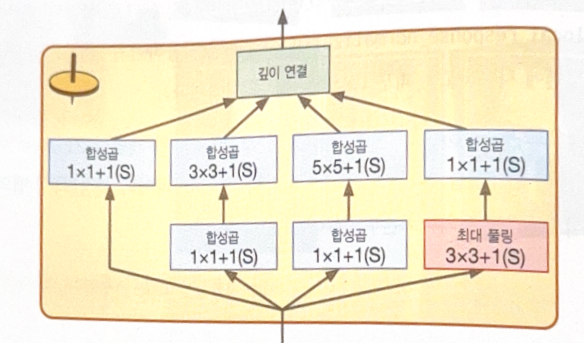
The expression ‘$3 \times 3 + 1 \text{(S)}$’ means that the layer uses 3 by 3 kernel, stride 1, and ‘same’ padding.
The 1 by 1 kernel plays several roles.
- Capture depth-wise features along channels.
- As it Outputs less feature maps than inputs, works as a bottleneck layer. This decreases cost of calculation and the number of hyperparameters to increase training speed and generalization performance.
- Consecutive CNN pairs(e.g. 1x1, 3x3) work as one powerful CNN layer being able to sense more complex patterns.
Inception module works as a CNN layer outputs various feature maps with complicated patterns.
Why ‘Inception’ module? It was named after the movie ‘Inception’. In the movie, casts go into the deep dream with multiple steps, just like an inception module.
The following is a structure of GoogLeNet, with 9 inception modules.
VGGNet
VGGNet has a very simple and conventional structure.
2 or 3 CNN layers - a Pooling layer - 2 or 3 CNN layers - a Pooling layer - … - 2 or 3 hidden layers
VGGNet only uses 3 by 3 filters.
ResNet
The main component of ResNet is skip(shortcut) connection. A signal injected to a layer is added to the upper layer’s output. When we train NN, our goal is to train objective function $h(\bf{x})$. If we add input x to the output(by using skip connection), NN will train $h(\bf{x})-x$, not $h(\bf{x})$. This is called residual learning.
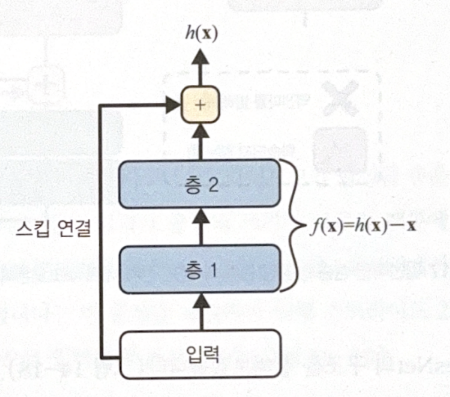
As weights are close to 0 when initialized, NN outputs value close to 0. This means that adding skip connection would output value similar to input, resulting to modeling identity function. This makes the speed of learning faster.
ResNet is similar to GoogLeNet. The major difference is using residual units(RU) very deeply.
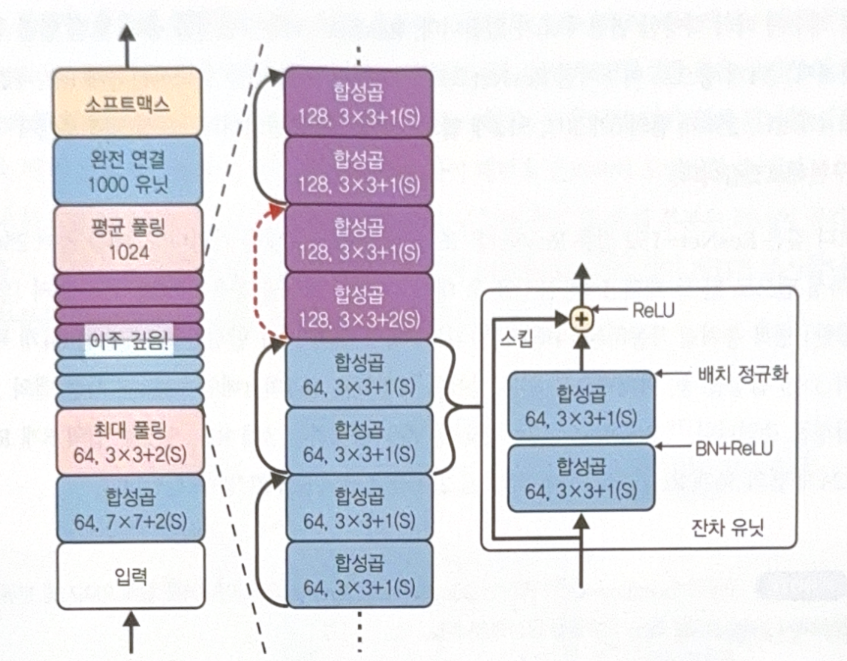
See red arrow(skip connection) on the image. As the size of stride is different, shape issue occurs. To solve this, CNN with stride 2 is used.
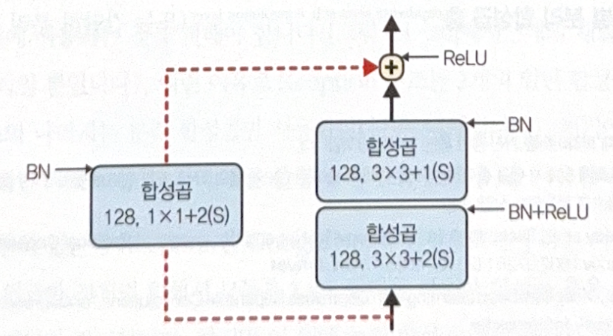
There are many variations of ResNet.
Xception
Xception means extreme inception. It mixes the idea of GoogLeNet and ResNet, but replaces inception module to depthwise separable convolution layer. It assumes that it is possible to model spatial patterns and channel-wise patterns separately.
The layer is composed of two parts. The first one applys a spatial filter to each feature map. The second part only discovers channel-wise patterns.
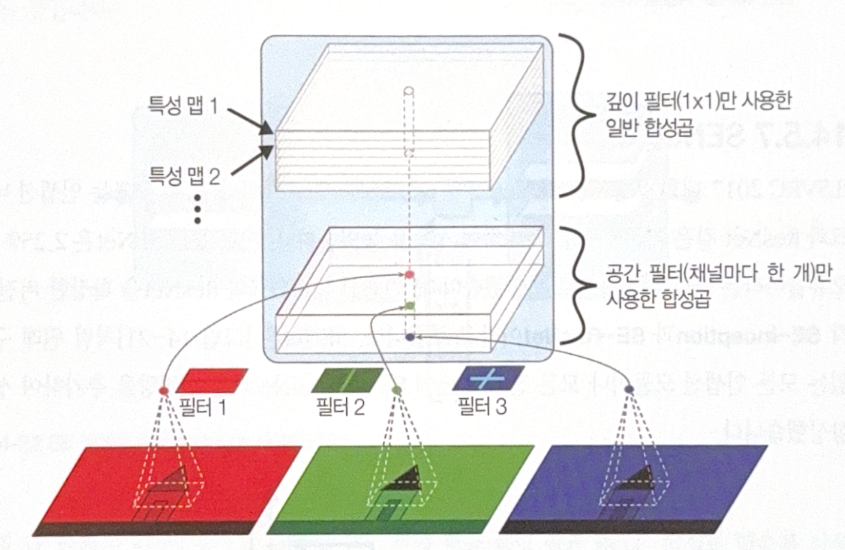
Use depthwise separable convolution layer as a default layer, because it uses less memory and calculations. In keras, use SeparableConv2D instead of Conv2D. The first part of layer is implemented separately, DepthwiseConv2D.
SENet
SENet uses SE block, a small NN, at all inception module or residual units. Inception NN with SE block is SE-Inception, ResNet with SE block is SE-ResNet.
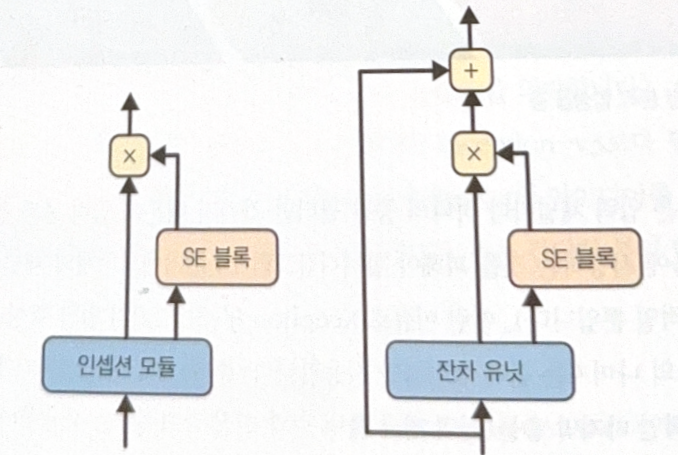
Analyze the outputs of SE block added part in depthwise (doesn’t care about spatial patterns). Learn which features are most activated at the same time, and correct feature maps. For example, if mouth and nose feature maps are strongly activated and eyes maps are not, the block will increase the output of eyes maps.
One SE block is composed of 3 layers.
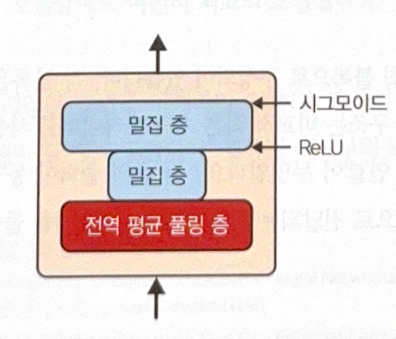
- Global average pooling layer: Calculate the average activation of each feature map.
- 1st Dense: Compression. Significantly fewer neurons than the output of step 1. This allow SE block to learn generalized patterns.
- 2nd Dense: Return corrected vector with the size of input of step 1.
- Multiply feature maps and the output of step 3 to update feature values.
Other Structures
- ResNeXt
- DenseNet: Use dense connection.
- MobileNet: For mobile and web applications.
- CSPNet
- EfficientNet: Use compound scaling
to increase depth(# layers), width(# filters), resolution(input size) at the same time. Find a well-performing structure in small ImageNet and use coumpund scaling to make the bigger version. Best model as of now.
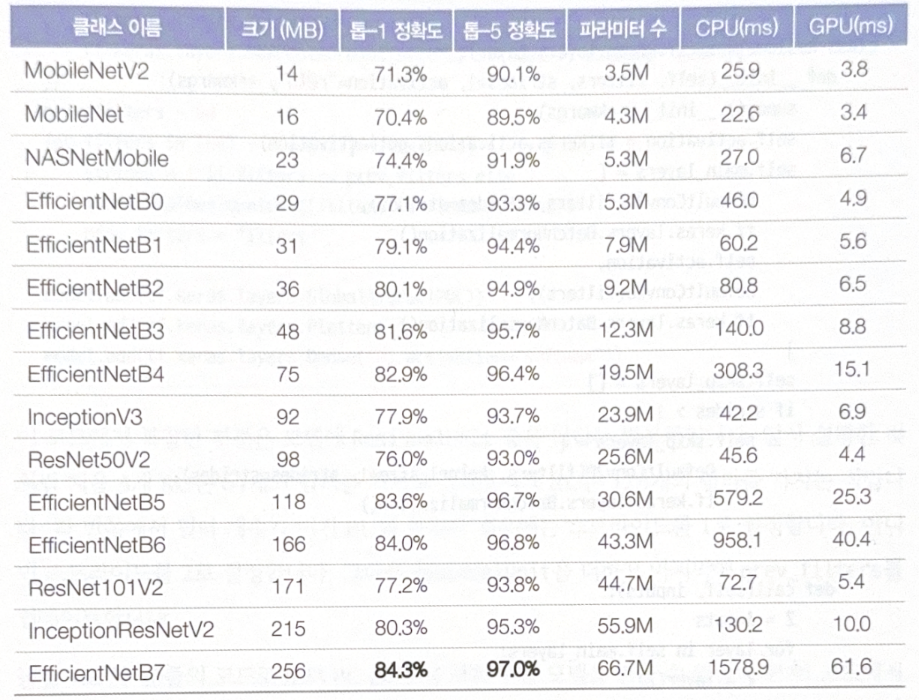
Choosing appropriate structure
The following table is for chooing the most appropriate structure.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기