
데이터 API
tf.data.API의 중심에는 tf.data.Dataset 개념이 있다. 다음은 간단한 텐서로 구성된 dataset을 만들고 순환하는 과정이다.
# 텐서 0~9를 가지는 dataet 생성
import tensorflow as tf
X = tf.range(10)
dataset = tf.data.Dataset.from_tensor_slices(X)
# 아이템 순환
dataset = tf.data.Dataset.from_tensor_slices(tf.range(10))
for item in dataset:
print(item)
연쇄 변환
변환 메서드를 호출하여 여러 변환을 수행할 수 있다. 각 변환은 새로운 dataset을 반환한다.
>>> dataset = tf.data.Dataset.from_tensor_slices(tf.range(10))
>>> dataset = dataset.repeat(3).batch(7)
>>> for item in dataset:
... print(item)
...
tf.Tensor([ 0 2 4 6 8 10 12], shape=(7,), dtype=int32)
tf.Tensor([14 16 18 0 2 4 6], shape=(7,), dtype=int32)
tf.Tensor([ 8 10 12 14 16 18 0], shape=(7,), dtype=int32)
tf.Tensor([ 2 4 6 8 10 12 14], shape=(7,), dtype=int32)
tf.Tensor([16 18], shape=(2,), dtype=int32)
위 코드는 다음과 같이 작동한다.
- 원본 데이터에서
repeat()메서드를 호출한다. 이는 원본 dataset의 아이템을 지정된 횟수만큼 반복하는 새로운 dataset을 반환한다. batch()메서드를 호출하면 1에서 만들어진 새로운 dataset의 아이템을 7개씩 묶어서 새로운 dataset을 만든다. 길이가 모자란 마지막 batch를 버리고 싶다면drop_remainder=True로 지정한다.
map(), filter() 메서드도 적용할 수 있다.
>>> # map
>>> dataset = dataset.map(lambda x: x * 2)
>>> for item in dataset:
... print(item)
...
tf.Tensor([ 0 2 4 6 8 10 12], shape=(7,), dtype=int32)
tf.Tensor([14 16 18 0 2 4 6], shape=(7,), dtype=int32)
tf.Tensor([ 8 10 12 14 16 18 0], shape=(7,), dtype=int32)
tf.Tensor([ 2 4 6 8 10 12 14], shape=(7,), dtype=int32)
tf.Tensor([16 18], shape=(2,), dtype=int32)
>>> # filter
>>> dataset = dataset.filter(lambda x: tf.reduce_sum(x) > 50)
>>> for item in dataset:
... print(item)
...
tf.Tensor([14 16 18 0 2 4 6], shape=(7,), dtype=int32)
tf.Tensor([ 8 10 12 14 16 18 0], shape=(7,), dtype=int32)
tf.Tensor([ 2 4 6 8 10 12 14], shape=(7,), dtype=int32)
map()메서드에는 간혹 매우 복잡한 계산이 포함되기도 한다.num_parallel_call매개변수에 실행할 스레드의 개수나tf.data.AUTOTUNE을 지정할 수도 있다.map()메서드에 전달하는 함수는 tensorflow 함수로 변환 가능해야 한다.
Dataset에 있는 몇 개의 아이템만 보고 싶다면 take() 메서드를 사용하면 된다.
>>> for item in dataset.take(2):
... print(item)
...
tf.Tensor([14 16 18 0 2 4 6], shape=(7,), dtype=int32)
tf.Tensor([ 8 10 12 14 16 18 0], shape=(7,), dtype=int32)
데이터 셔플링
shuffle() 메서드를 이용해서 간단하게 샘플을 섞을 수 있다. 원리는 다음과 같다.
- 원본 dataset에서
buffer_size개수만큼 데이터를 추출한다. 이 데이터는 버퍼에 채워진다. - 새로운 아이템이 요청되면 버퍼에서 랜덤하게 하나를 꺼내서 반환한다.
- 원본 dataset에서 데이터 하나를 추출하여 비워진 버퍼를 채운다.
- 원본 dataset의 모든 아이템이 사용될 때까지 반복한다.
버퍼의 크기가 충분히 커야 하지만, 보유한 메모리는 초과하거나 원본 dataset보다 커서는 안된다.
dataset = tf.data.Dataset.range(10).repeat(2)
dataset = dataset.shuffle(buffer_size=4, seed=42).batch(7)
for item in dataset:
print(item)
데이터 순회하며 읽기
캘리포니아 주택 dataset을 적재하고 섞은 다음 train set, dev set, test set으로 나누었다고 하자. 이를 여러 csv 파일로 나누었다. train_filepaths에 훈련 파일 경로가 담겨 있을 때 다음과 같이 dataset을 만들 수 있다.
filepath_dataset = tf.data.Dataset.list_files(train_filepaths, seed=42)
interleave()로 한 번에 다섯 개 파일을 한 줄 씩 번갈아 가며 읽을 수 있다.
n_readers = 5
dataset = filepath_dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1), # 첫 줄은 열 이름이므로 건너 뛰기
cycle_length=n_readers
)
interleave()는 한 번에 5개의 경로(파일)를 불러와서 한 번에 한 줄씩 순회하며 읽는다. 모든 줄을 읽었다면 다음 5개를 가져와서 순회하며 읽기를 반복한다. 만약 어느 한 파일의 길이가 지나치게 길다면 그 파일의 끝 부분은 제대로 interleaving이 되지 않을 것이다.
데이터 전처리
다음 코드는 데이터 전처리를 위한 함수이다.
X_mean, X_std = scaler.mean_, scaler.scale_
n_inputs = 8
def parse_csv_line(line):
defs = [0.] * n_inputs + [tf.constant([], dtype=tf.float32)]
fields = tf.io.decode_csv(line, record_defaults=defs)
return tf.stack(fields[:-1]), tf.stack(fields[-1:])
def preprocess(line):
x, y = parse_csv_line(line)
return (x - X_mean) / X_std, y
parse_csv_line()
CSV 한 라인을 받아 파싱(parsing)한다.
defs에는 각 열의 기본값, 열 개수, 데이터 타입 등의 정보가 들어있다 (이 예시에서는 모든 특성이 실수이고 누락된 값의 기본 값은 0이다). 마지막 열(타깃)에는 빈 배열을 제공하는데, 이는 기본 값이 없음을 의미한다.tf.io.decode_csv()함수는 열마다 한 개씩 스칼라 텐서의 리스트를 반환한다.- 반환해야하는 것은 1D 텐서배열이므로, 스칼라 텐서인
tf.io.decode_csv()함수의 결과를 쌓아(tf.stack) 1D 배열을 만든다.
preprocess()
데이터의 스케일을 조정한다.
데이터 적재와 전처리 합치기, 프리페치
지금까지의 과정을 하나의 함수로 구현할 수 있다.
def csv_reader_dataset(filepaths, n_readers=5, n_read_threads=None,
n_parse_threads=5, shuffle_buffer_size=10000, seed=42,
n_parse_batch_size=32):
dataset = tf.data.Dataset.list_files(filepaths, seed=seed)
dataset = dataset.interleave(
lambda filepath: tf.data.TextLineDataset(filepath).skip(1),
cycle_length=n_readers, num_parallel_calls=n_read_threads
)
dataset = dataset.map(preprocess, num_parallel_calls=n_parse_threads)
dataset = dataset.shuffle(shuffle_buffer_size, seed=seed)
return dataset.batch(n_parse_batch_size).prefetch(1)
마지막에 사용된 prefetch() 메서드는 성능에 아주 중요한 역할을 한다. prefetch()를 지정하면, 지정된 개수만큼의 batch가 항상 미리 준비되도록 한다. 즉, 다음과 같이 동작한다.
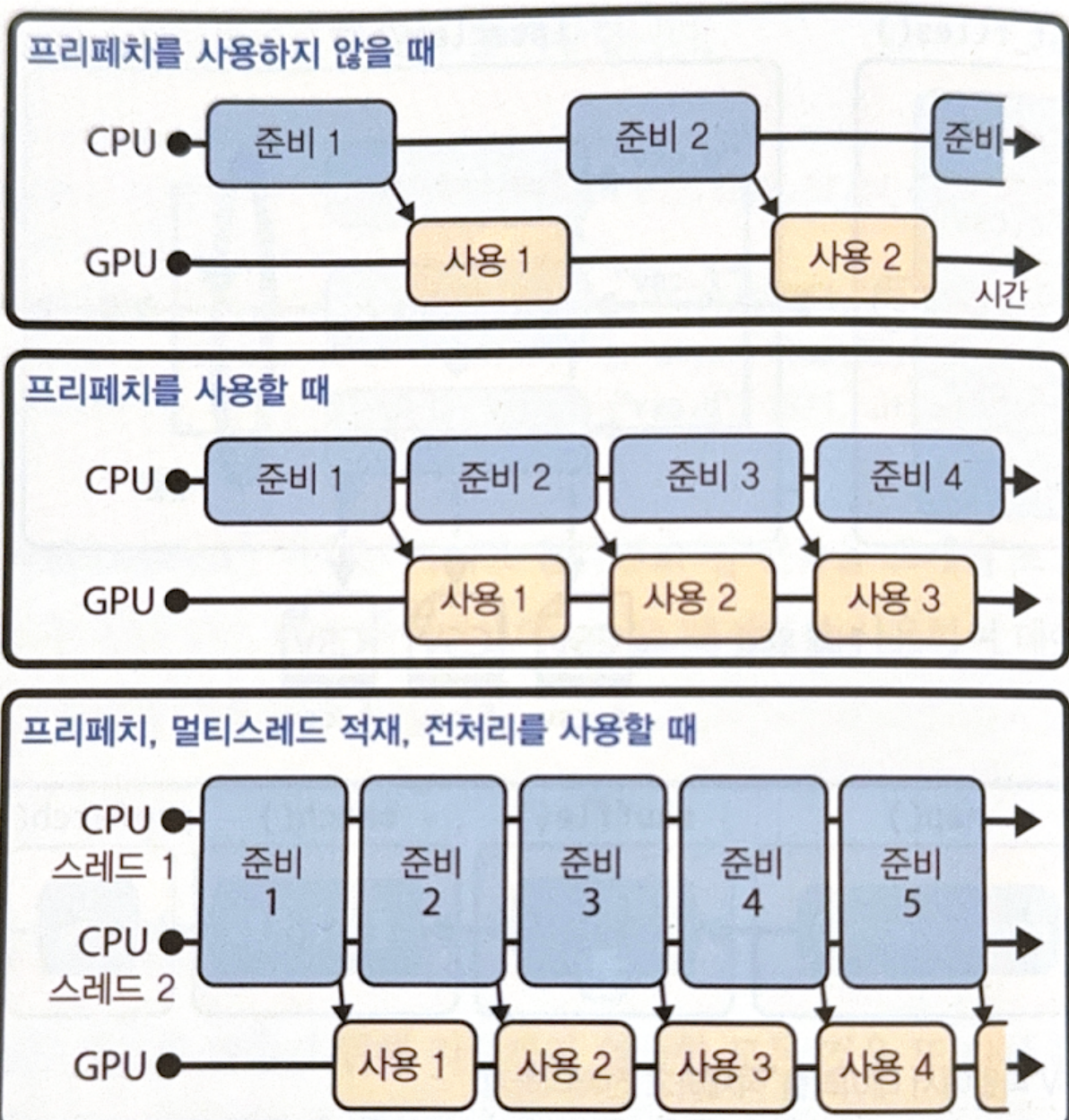
마지막 그림처럼 GPU를 거의 100% 사용하려면 interleave()와 map() 메서드에서 num_parallel_calls 매개변수를 지정하면 된다.
keras와 dataset 사용하기
지금까지 전처리한 dataset을 keras에서 사용하는 것은 간단하다.
# load set
train_set = csv_reader_dataset(train_filepaths)
valid_set = csv_reader_dataset(valid_filepaths)
test_set = csv_reader_dataset(test_filepaths)
# define, compile and train
model = tf.keras.Sequential([
tf.keras.layers.Dense(30, activation="relu", kernel_initializer="he_normal",
input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(1),
])
model.compile(loss="mse", optimizer="sgd")
model.fit(train_set, validation_data=valid_set, epochs=5)
# test and predict
test_mse = model.evaluate(test_set)
new_set = test_set.take(3)
y_pred = model.predict(new_set)
사용자 정의 훈련 반복을 만드는 방법에는 두 가지가 있다.
- Train set 반복
- 한 번의 epoch 동안 모델을 훈련하는 tensorflow 함수 제작하여 반복
두 번째 방법이 훈련 속도를 높이기에는 더 좋다.
# 방법 1 - train set 반복
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_fn = tf.keras.losses.MSE
n_epochs = 5
for epoch in range(n_epochs):
for X_batch, y_batch in train_set:
print("\rEpoch {}/{}".format(epoch + 1, n_epochs), end="")
with tf.GradientTape() as tape:
y_pred = model(X_batch)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 방법 2 - tensorflow 함수 제작
@tf.function
def train_one_epoch(model, optimizer, loss_fn, train_set):
for X_batch, y_batch in train_set:
with tf.GradientTape() as tape:
y_pred = model(X_batch)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_fn = tf.keras.losses.MSE
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기