
사용자 정의 훈련 반복
fit() 메서드는 하나의 optimizer만 사용한다. 따라서 Wide & Deep 신경망과 같이 여러 optimizer가 필요한 경우 훈련 반복을 직접 구현해야 할 수 있다.
훈련 반복을 직접 다룰 때는 모델을 따로 컴파일할 필요가 없다.
아래와 같이 훈련 반복에 필요한 요소(배치 랜덤 추출, 진행 그래프 출력)들을 직접 정의해주어야 한다.
# 모델 정의
l2_reg = tf.keras.regularizers.l2(0.05)
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(30, activation="elu", kernel_initializer="he_normal",
kernel_regularizer=l2_reg),
tf.keras.layers.Dense(1, kernel_regularizer=l2_reg)
])
# 배치 랜덤하게 추출
def random_batch(X, y, batch_size=32):
idx = np.random.randint(len(X), size=batch_size)
return X[idx], y[idx]
# 진행 상태 출력 그래프
def print_status_bar(step, total, loss, metrics=None):
metrics = " - ".join(["{}: {:.4f}".format(m.name, m.result())
for m in [loss] + (metrics or [])])
end = "" if step < total else "\n"
print("\r{}/{} - ".format(step, total) + metrics, end=end)
# 하이퍼파라미터 정의
n_epochs = 5
batch_size = 32
n_steps = len(X_train) // batch_size
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
loss_fn = tf.keras.losses.MSE
mean_loss = tf.keras.metrics.Mean(name='mean_loss')
metrics =[tf.keras.metrics.MeanAbsoluteError()]
# 모델 훈련
for epoch in range(1, n_epochs + 1):
print(f"Epoch {epoch}/{n_epochs}")
for step in range(1, n_steps + 1):
X_batch, y_batch = random_batch(X_train_scaled, y_train)
with tf.GradientTape() as tape:
y_pred = model(X_batch, training=True)
main_loss = tf.reduce_mean(loss_fn(y_batch, y_pred))
loss = tf.add_n([main_loss] + model.losses)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
mean_loss(loss)
for metric in metrics:
metric(y_batch, y_pred)
print_status_bar(step, n_steps, mean_loss, metrics)
for metric in [mean_loss] + metrics:
metric.reset_states()
사용자 정의 훈련 반복을 만들면 길고, 버그가 발생하기 쉽고, 유지 보수하기 어렵다.
Tensorflow 함수
파이썬으로 정의된 함수를 tensorflow 함수로 변환할 수 있다.
# python function
def cube(x):
return x ** 3
# convert to tensorflow
tf_cube = tf.function(cube)
tf_cube
# use decorator(more common)
@tf.function
def tf_cube(x):
x ** 3
@tf.function과 같이 데코레이터를 사용하는 것이 더 일반적이다.
파이썬 함수가 tensorflow 함수로 변환되는 과정에서는 계산 그래프가 활용된다. tf.function()은 파이썬 함수에서 수행되는 계산을 분석하고 동일한 작업을 수행하는 계산 그래프를 생성한다.
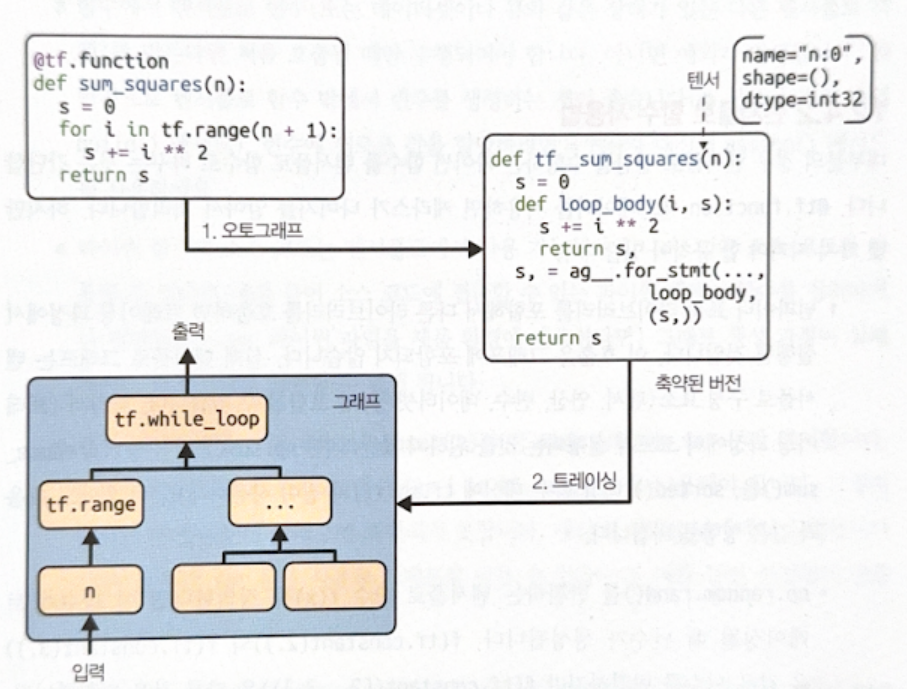
변환 과정은 두 단계로 나뉜다.
- 오토그래프(aurograph)
- 파이썬 소스코드를 분석하여 제어문(for, while, if, return, break 등)을 모두 찾는다.
- 이를 알맞은 tensorflow 연산으로 바꾼다.
- 심볼릭 텐서(symbolic tensor)라는 값이 없는 텐서(이름, 데이터 타입, 크기만 존재)를 전달하여 함수를 호출한다(이를 ‘그래프 모드 실행’이라고 한다). 이 과정을 통해 그래프에 노드가 추가된다.
- 트레이싱(tracing): 최종 그래프를 생성한다.
Tensorflow 함수는 파이썬 함수보다 더 빠르게 실행된다. 여기에 더해 tf.function()을 호출할 때 jit_compile=True로 설정하면 XLA를 활용하여 전체 계산을 단일 커널로 컴파일하기 때문에 속도가 훨씬 더 빨라진다.
앞서 사용자 정의 손실 함수, 지표, 층 등을 파이썬 함수로 구현하여 keras에 적용하였는데, 이처럼 keras에 적용하는 경우에는 자동으로 tensorflow 함수로 변환되므로 따로 바꿀 필요가 없다.
Tensorflow 함수를 사용할 때는 다음 사항을 알고 있는 것이 좋다.
- 호출에 사용되는 입력 크기와 데이터 타입에 맞추어 매번 새로운 그래프를 생성한다. 즉, 같은 입력 크기와 데이터 타입이라면 같은 그래프가 사용되지만, 둘 중 하나만 달라도 새로운 그래프가 생긴다.
- numpy, 표준 라이브러리 등 다른 라이브러리를 호출하면 트레이싱 과정에서 실행된다. 따라서 이 호출은 그래프에 포함되지 않는다. 트레이싱 과정에서 실행되기를 원치 않는다면 비슷한 기능을 하는 tensorflow 연산을 사용하자.
- 다른 파이썬 함수나 tensorflow 함수를 호출할 수 있다. 호출하는 함수들에는
@tf.function를 적용할 필요가 없다. - Tensorflow 함수 밖에서 변수를 생성하는 것이 좋다. 함수 안에서 할당할 경우,
assign()을 이용한다. - 파이썬 함수의 소스코드는 tensorflow에서 사용 가능해야 한다.
- 반복문을 사용할 때는
for i in tf.range(x)와 같이 텐서나tf.data.Dataset을 순회하는 for문만을 사용해야 한다.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기