
사용자 정의 층
Tensorflow에 없는 특이한 층이 필요하다면 사용자 정의 층을 만들어야 한다. tf.keras.layers.Lambda를 사용하면 가중치가 필요 없는 사용자 정의 층을 쉽게 만들 수 있다.
exponential_layer = tf.keras.layers.Lambda(lambda x: tf.exp(x))
가중치를 가진 층(상태가 있는 층)을 만들려면 tf.keras.layers.Layer를 상속하여 클래스를 만들어야 한다. 다음 클래스는 Dense층의 간소화 버전이다.
class MyDense(tf.keras.layers.Layer):
def __init__(self, units, activation=None, **kwargs):
super().__init__(**kwargs)
self.units = units
self.activation = tf.keras.activations.get(activation)
def build(self, batch_input_shape):
self.kernel = self.add_weight(
name="kernel", shape=[batch_input_shape[-1], self.units],
initializer="glorot_normal")
self.bias = self.add_weight(
name="bias", shape=[self.units], initializer="zeros")
def call(self, X):
return self.activation(X @ self.kernel + self.bias)
def get_config(self):
base_config = super().get_config()
return {**base_config, "units": self.units,
"activation": tf.keras.activations.serialize(self.activation)}
build(): 가중치마다add_weight()를 호출하여 층의 변수를 만든다. 층이 처음 사용될 때 호출된다.call(): 층에 필요한 연산을 수행한다. 즉, 출력을 만든다.
여러 가지 입력을 받는 층(e.g. Concatenate)을 만들려면 call() 메서드에 모든 입력이 포함된 튜플을 전달해야 한다. 다음과 같이 말이다.
class MyMultiLayer(tf.keras.layers.Layer):
def call(self, X):
X1, X2 = X
return X1 + X2, X1 * X2, X1 / X2
훈련과 테스트에서 다르게 작동하는 층(e.g. dropout, batch normalization)이 필요하다면 call() 메서드에 training 변수를 추가하여 훈련에서는 True, 테스트에서는 False가 되도록 해야 한다. 다음 코드는 훈련하는 동안에는 가우스 잡음을 추가하고, 테스트에서는 추가하지 않는 층이다.
class MyGaussianNoise(tf.keras.layers.Layer):
def __init__(self, stddev, **kwargs):
super().__init__(**kwargs)
self.stddev = stddev
def call(self, X, training=False):
if training:
noise = tf.random.normal(tf.shape(X), stddev=self.stddev)
return X + noise
else:
return X
사용자 정의 모델
다음과 같은 모델을 직접 정의해야 한다고 해보자.
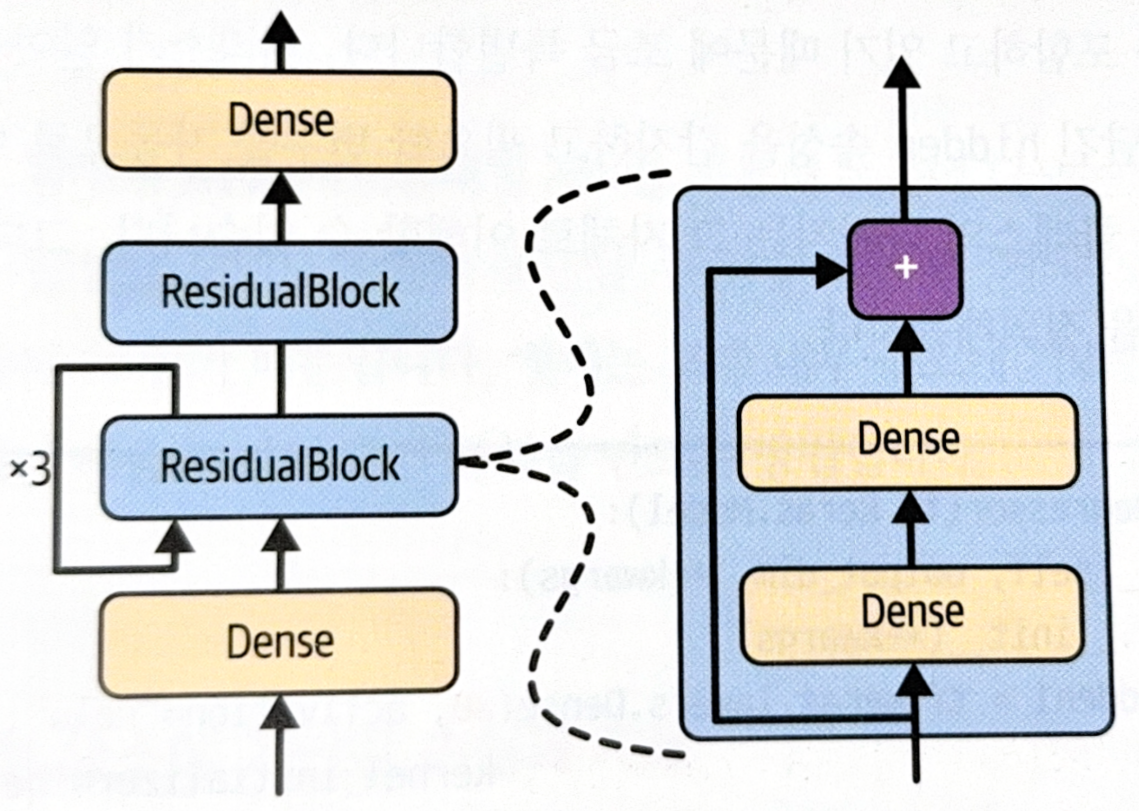
위 모델을 다음과 같은 구조를 가지고 있다.
- 첫 번째 완전 연결 층(Dense) 통과.
- 첫 번째 ResidualBlock 3번 반복. ResidualBlock은 2개의 Dense 층과 스킵 연결로 구성.
- 두 번째 ResidualBlock 통과.
- 두 번째 완전 연결 층(Dense) 통과.
가장 먼저 ResidualBlock 층을 만들어야 한다.
class ResidualBlock(tf.keras.layers.Layer):
def __init__(self, n_layers, n_neurons, **kwargs):
super().__init__(**kwargs)
self.hidden = [tf.keras.layers.Dense(n_neurons, activation='relu',
kernel_initializer='he_normal')
for _ in range(n_layers)]
def call(self, inputs):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
return inputs + Z
그 다음에는 subclassing API를 이용해 모델을 정의한다.
class ResidualRegressor(tf.keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden1 = tf.keras.layers.Dense(30, activation='relu',
kernel_initializer='he_normal')
self.block1 = ResidualBlock(2, 30)
self.block2 = ResidualBlock(2, 30)
self.out = tf.keras.layers.Dense(output_dim)
def call(self, inputs):
Z = self.hidden1(inputs)
for _ in range(1 + 3):
Z = self.block1(Z)
Z = self.block2(Z)
return self.out(Z)
물론 저장된 모델을 로드하고 싶다면 ResidualBlock 클래스와 ResidualRegressor 클래스 모두에 get_config() 메서드를 구현해야 한다. save_weights()와 load_weights()를 사용해 가중치를 저장하고 로드하는 것도 가능하다.
모델 구성 요소에 기반한 손실과 지표
은닉 층의 가중치나 활성화 함수 같이 모델 구성 요소에 기반한 손실은 모델 내부 상황을 모니터링할 때 유용하게 사용할 수 있다.
다음 코드는 맨 위 은닉 층에 보조 출력을 가지는 모델을 만든 것이다. 이 보조 출력에 연결된 손실을 재구성 손실(reconstruction loss)이라고 한다. 재구성과 입력 사이의 MSE이다. 재구성 손실을 주 손실에 더하여 모델이 은닉 층을 통과하면서 가능한 많은 정보를 유지하도록 한다.
class ReconstructionRegressor(tf.keras.Model):
def __init__(self, output_dim, **kwargs):
super().__init__(**kwargs)
self.hidden = [tf.keras.layers.Dense(n_neurons, activation='relu',
kernel_initializer='he_normal')
for _ in range(n_layers)]
self.out = tf.keras.layers.Dense(output_dim)
self.reconstruction_mean = tf.keras.metrics.Mean(name='reconstruction_error') # 1
def build(self, batch_input_shape):
n_inputs = batch_input_shape[-1]
self.reconstruct = tf.keras.layers.Dense(n_inputs) # 2
def call(self, inputs, training=False):
Z = inputs
for layer in self.hidden:
Z = layer(Z)
reconstruction = self.reconstruct(Z)
recon_loss = tf.reduce_mean(tf.square(reconstruction - inputs)) # 3
self.add_loss(0.05 * recon_loss)
if training:
result = self.reconstruction_mean(recon_loss)
self.add_metric(result) # 4
return self.out(Z)
눈여겨 볼 부분들은 다음과 같다.
- 훈련하는 동안 재구성 오차를 추적하기 위해 Mean 스트리밍 지표를 만들었다.
- 완전 연결 층을 하나 더 추가하여 입력을 재구성하였다.
- 재구성 손실을 계산하고
add_loss()메서드로 모델의 손실 리스트에 추가한다. 주손실을 압도하지 않도록 가중치를 0.05로 조절하였다. self.add_metric(result)으로 하면 keras가 훈련 중에 자동으로 평균을 추적하여 화면에 출력한다.
자동 미분으로 gradient 계산하기
Tensorflow에서는 tf.GradientTape()를 이용하여 후진 모드 자동 미분을 쉽게 계산할 수 있다.
def f(w1, w2):
return 3 * w1 ** 2 + 2 * w1 * w2
w1, w2 = tf.Variable(5.), tf.Variable(3.)
with tf.GradientTape() as tape:
z = f(w1, w2)
gradients = tape.gradient(z, [w1, w2])
tf.GradientTape() 블록에서는 변수와 관련된 모든 연산을 자동으로 기록하고, tape.gradient(z, [w1, w2])에서는 두 변수 [w1, w2]에 대한 z의 gradient를 요청한다.
gradient() 메서드가 호출된 이후에는 테이프가 지워진다. gradient() 메서드를 여러 번 호출하고 싶다면 다음과 같이 persistent=True로 설정한 다음, 테이프 사용이 끝나면 수동으로 지워주어야 한다.
# Use tape twice
with tf.GradientTape(persistent=True) as tape:
z = f(w1, w2)
dz_dw1 = tape.gradient(z, w1)
dz_dw2 = tape.gradient(z, w2)
del tape
물론 이전 강에서 살펴보았듯이, 변수가 아닌 constant와 같은 객체에 대해서는 gradient 계산이 불가능하다. 하지만 필요할 경우 강제로 계산하게 할 수 있다.
# solution for not variable
with tf.GradientTape() as tape:
tape.watch(c1)
tape.watch(c2)
z = f(c1, c2)
gradients = tape.gradient(z, [c1, c2])
GradientTape는 여러 값(파라미터)에 대한 한 값(손실)의 gradient를 계산한다. 만약 여러 손실이 포함된 벡터의 gradient를 계산하면 tensorflow는 벡터의 합의 gradient를 계산한다. 개별 gradient를 계산하고 싶다면
jacobian()메서드를 호출하자.
신경망의 일부분에 gradient가 역전파되지 않도록 하려면 tf.stop_gradient()를 사용한다. 정방향 계산은 정상적으로 수행되지만 역전파 시에는 gradient를 전파하지 않는다.
# don't backpropagate for a part
def f(w1, w2):
return 3 * w1 ** 2 + tf.stop_gradient(2 * w1 * w2)
with tf.GradientTape() as tape:
z = f(w1, w2)
tape.gradient(z, [w1, w2])
간혹 gradient를 계산할 때 수치적인 문제가 발생할 수도 있다. 실제 gradient는 무한대 값이 아니지만, 계산 결과 무한대가 나올 수도 있다. 특히 지수 함수의 경우 매우 빠르게 증가하므로 자주 문제가 된다. 이럴 때는 수치적으로 안정되도록 함수를 다시 작성할 수 있다. 다음은 softplus 함수를 다시 작성한 것이다.
# better softplus
def my_softplus(z):
return tf.math.log(1 + tf.exp(-tf.abs(z))) + tf.maximum(0., z)
수치적으로 안정적인 함수더라도 gradient가 불안정할 수 있다. 이러한 경우 자동 미분을 사용하는 대신 gradient 계산에 사용할 식을 따로 tensorflow에 알려주어야 한다. @tf.custom_gradient 데코레이터를 사용하면 되며, 일반적인 함수 결과와 gradient 계산 함수를 모두 반환해야 한다.
# don't use automatic differentiation
@tf.custom_gradient
def my_softplus(z):
def my_softplus_gradients(grads):
return grads * (1 - 1 / (1 + tf.exp(z)))
result = tf.math.log(1 + tf.exp(-tf.abs(z))) + tf.maximum(0., z)
return result, my_softplus_gradients
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기