
함수형 API
함수형 API를 사용하면 Wide & Deep 신경망과 같이 복잡한 신경망도 구현할 수 있다. Wide & Deep 신경망은 아래 그림과 같이 짧은 경로를 추가해 단순한 패턴을 학습하도록 한 신경망이다.
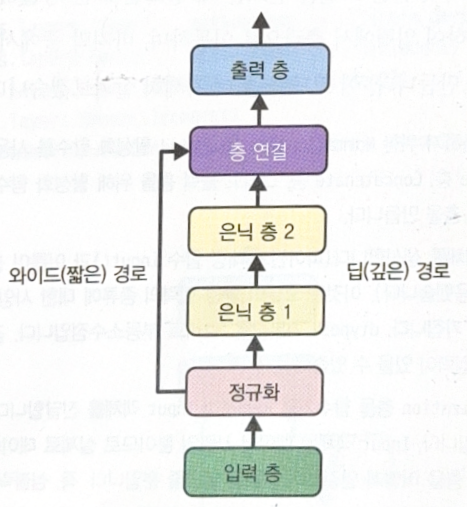
일부 특성을 짧은 경로로 전달하고 싶다면 여러 입력을 사용하면 된다. 아래 코드는 인덱스 0부터 4까지와 2부터 7까지를 나누어서 깊은 경로와 짧은 경로로 각각 보낸다.
input_wide = tf.keras.layers.Input(shape=[5])
input_deep = tf.keras.layers.Input(shape=[6])
norm_layer_wide = tf.keras.layers.Normalization()
norm_layer_deep = tf.keras.layers.Normalization()
norm_wide = norm_layer_wide(input_wide)
norm_deep = norm_layer_deep(input_deep)
hidden1 = tf.keras.layers.Dense(30, activation='relu')(norm_wide)
hidden2 = tf.keras.layers.Dense(30, activation='relu')(hidden1)
concat = tf.keras.layers.concatenate([norm_deep, hidden2])
output = tf.keras.layers.Dense(1)(concat)
model = tf.keras.Model(inputs=[input_wide, input_deep], outputs=[output])
당연히 fit(), evaluate(), predict() 메서드를 호출할 때도 입력마다 하나씩 행렬의 튜플을 전달해야 한다.
보조 출력을 사용하면 하위 신경망이 그 자체로 유용한 것을 학습하는지 확인할 수 있다. 보조 출력을 추가하려면 적절한 층에 연결하고 모델의 출력 리스트에 추가하면 된다.
output = tf.keras.layers.Dense(1)(concat)
aux_output = tf.keras.layers.Dense(1)(hidden2)
model = tf.keras.Model(inputs=[input_wide, input_deep], outputs=[output, aux_output])
보조 출력을 사용했다면 모델의 컴파일 과정에서 주 출력의 손실에 더 많은 가중치를 부여하는 것이 좋다.
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
model.compile(loss=('mse', 'mse'), loss_weights=(0.9, 0.1), optimizer=optimizer,
metrics=['RootMeanSquaredError'])
Subclassing API
Sequential API나 함수형 API는 모두 선언적(declarative)이다. 선언적이라는 것은 사용할 층과 연결 방식을 먼저 정의하고 그 다음에 데이터를 주입하는 방식을 말한다. 이는 다음과 같은 장점을 가지고 있다.
- 모델의 저장, 복사, 공유가 쉽다.
- 모델의 구조를 출력하거나 분석하기 좋다.
- 프레임워크가 크기를 짐작하고 타입을 확인하여 에러를 일찍 발견할 수 있다.
하지만 단점도 있다.
- 반복문, 조건문 등을 다루기 어렵다.
명령형(imperative) 프로그래밍이 필요하다면 subclassing API를 사용할 수 있다. 생성자 안에서 필요한 층을 만들고, call() 메서드 안에 수행하려는 연산을 기술한다. 필요하다면 call() 메서드 안에 반복문, 조건문, 저수준 텐서플로 연산 등을 포함할 수 있다.
import keras
@keras.saving.register_keras_serializable()
class WideAndDeepModel(tf.keras.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs)
self.norm_layer_wide = tf.keras.layers.Normalization()
self.norm_layer_deep = tf.keras.layers.Normalization()
self.hidden1 = tf.keras.layers.Dense(units, activation=activation)
self.hidden2 = tf.keras.layers.Dense(units, activation=activation)
self.main_output = tf.keras.layers.Dense(1)
self.aux_output = tf.keras.layers.Dense(1)
def call(self, inputs):
input_wide, input_deep = inputs
norm_wide = self.norm_layer_wide(input_wide)
norm_deep = self.norm_layer_deep(input_deep)
hidden1 = self.hidden1(norm_deep)
hidden2 = self.hidden2(hidden1)
concat = tf.keras.layers.concatenate([norm_wide, hidden2])
output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return output, aux_output
model = WideAndDeepModel(30, activation="relu", name="my_cool_model")
하지만 subclassing API는 다음과 같은 단점이 있다.
- 모델의 구조가
call()메서드 안에 숨겨져 있어 keras가 쉽게 검사할 수 없다. - 모델을 복제할 수 없다.
summary()메서드를 호출해도 층의 연결 방식을 알 수 없다.
따라서 웬만하면 sequential API나 함수형 API를 사용하는 것이 좋다.
모델의 저장과 복원
모델의 저장은 다음과 같이 할 수 있다.
model.save('my_keras_model.keras')
모델을 로드하고 예측할 때는 다음과 같이 한다.
model = tf.keras.models.load_model('my_keras_model')
y_pred_main, y_pred_aux = model.predict((X_new_wide, X_new_deep))
save_weights()나 load_weights()를 사용하면 파라미터 값만 저장하고 로드할 수 있다. 연결 가중치, 편향, 전치리 통계치, 옵티마이저 상태 등이 여기에 포함되는데, 당연히 전체 모델을 저장하는 것보다 빠르다.
Callback
fit() 메서드의 callback 매개변수를 사용하면 훈련의 시작 전이나 후에 호출할 객체 리스트를 지정할 수 있다. 에포크의 시작 전 후, 배치 처리 전후에 호출할 수도 있다. 이를 잘 활용하면 일정한 간격으로 모델을 저장하거나 검증할 수 있고, 필요에 따라서는 훈련을 중지시킬 수도(조기 종료) 있다.
다음은 ModelCheckpoint를 이용해 일정한 간격으로 모델의 체크 포인트를 저장하는 코드이다. 필요에 따라서는 save_best_only=True로 설정하여 dev set에서 최상의 성능을 낸 모델만을 저장할 수 있다.
# checkpoint
checkpoint_cb = tf.keras.callbacks.ModelCheckpoint('my_checkpoints', save_best_only=True)
history = model.fit(
(X_train_wide, X_train_deep), (y_train, y_train), epochs=10,
validation_data=((X_valid_wide, X_valid_deep), (y_valid, y_valid)),
callbacks=[checkpoint_cb])
위 코드가 early stopping과 비슷한 효과를 내기는 하지만, 실제로 훈련이 종료되는 early stopping을 구현하려면 다음과 같이 한다.
# early stopping
early_stopping_cb = tf.keras.callbacks.EarlyStopping(patience=10,
restore_best_weights=True)
history = model.fit(
(X_train_wide, X_train_deep), (y_train, y_train), epochs=100,
validation_data=((X_valid_wide, X_valid_deep), (y_valid, y_valid)),
callbacks=[checkpoint_cb, early_stopping_cb])
에포크의 숫자를 아무리 크게 지정해도 상관이 없다. 모델이 향상되지 않으면 훈련이 자동으로 중지될 것이다.
필요에 따라서는 사용자 정의 callback을 만들 수도 있다.
# customized callback
class PrintValTrainRatioCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
ratio = logs["val_loss"] / logs["loss"]
print(f"Epoch={epoch}, val/train={ratio:.2f}")
tensorboard
Tensorboard는 유용한 시각화 도구이다. 학습 곡선을 그리거나 비교하고, 계산 그래프를 시각화하거나 훈련 통계 분석을 수행할 수 있다.
자세한 사용법은 코드를 참고하자.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기