
End-to-end 딥러닝이란?
End-to-end 딥러닝은 자료처리 시스템 및 학습시스템에서의 처리과정을 여러 단계로 설정하는 대신 한 번에 처리하는 것을 말한다. 즉, 데이터만 입력하고 원하는 목적이 곧바로 도출되도록 하는 것이다.
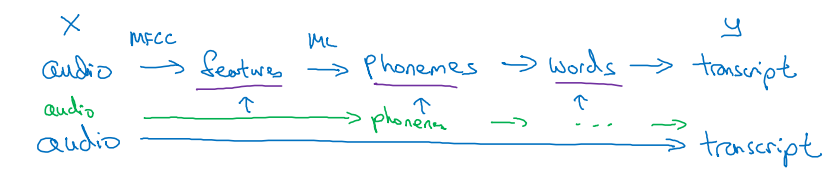
위 그림은 음성 인식 모델을 개발할 때의 기존의 단계적인 방식과 end-to-end 방식을 비교한 것이다. 기존의 단계적인 방식에서는 MFCC(오디오 파일 특징 추출 알고리즘)를 이용해 오디오 파일에서 특징을 추출하고, 머신러닝으로 음소들을 분리하였다. 그리고 이를 다시 조합해 단어를 만들고 최종적으로 텍스트 형식의 대본을 출력해낸다. 그러나 end-to-end 방식에서는 오디오 파일을 모델에 넣기만 하면 바로 대본이 출력된다.
End-to-end 딥러닝의 장점
End-to-end 딥러닝의 장점은 명확하다. 최종적으로 우리가 원하는 모델을 얻기 위해 필요했던 중간 단계들을 모두 생략하고, 훨씬 단순한 모델을 한 번에 만들 수 있다.
또, 데이터 자체를 이용할 수 있다. 음성 인식 모델을 여러 단계로 구분해서 개발할 때, 우리는 음소를 분류해내고자 했다. 그러나 ‘음소’는 인간이 만들어낸, 어쩌면 인공적인 기준이자 선입견일 수 있다. End-to-end 딥러닝은 이와 같은 인공적인 기준을 추가하지 않기 때문에 데이터 자체를 이용하는 것에 더 가까워질 수 있다.
End-to-end 딥러닝의 단점
End-to-end 딥러닝은 단점도 있다.
일단, 단계적인 모델 개발에 비해 매우 많은 양의 데이터가 필요하다. 골격 사이즈를 보고 청소년의 정상 발달 여부를 판단한다고 하자. End-to-end 모델 개발을 위해서는 ‘골격 이미지 & 나이’의 조합으로 이루어진 데이터가 필요하다. 반면 단계적인 모델로 개발한다고 하면 (1)골격 이미지에서 길이 데이터를 추출하는 단계, (2)길이 데이터로 나이를 판단하는 단계, 즉 2개의 단계가 필요하다. 후자의 경우가 전자보다 필요한 데이터를 찾기 더 쉬울 것이다.
또 다른 단점은 직접 개발한 유용한 요소들을 무시할 수도 있다는 것이다. 단계적인 모델 개발 과정에서 고안된 다양한 알고리즘이나 신경망들은 해당 모델뿐만 아니라 다른 모델에도 응용할 수 있을 정도로 매우 유용했으나, end-to-end 딥러닝처럼 중간과정이 필요 없어진 상황에서는 더 이상 이런 응용을 기대하기 힘들 것이다.
언제 End-to-end 딥러닝을 사용할까?
End-to-end 딥러닝은 ‘입력을 출력으로 바꾸는 과정의 복잡성을 해결할 충분한 데이터를 가지고 있을 때’ 사용하면 좋다. 좀 쉽게 말하자면, 데이터가 충분히 많으면서 쪼개지 않고 한 방에 해결해도 될 정도로 문제가 단순해야 한다.
회사 출입증을 대신할 얼굴 인식 모델을 개발한다고 해보자. 회사 출입구에서 카메라로 얻은 얼굴 이미지를 사용할텐데, 얼굴이 사진의 오른편에 치우치거나 너무 크게 나오거나 하는 등 일정하지 않을 가능성이 높다. 이 사진들을 그냥 end-to-end 딥러닝에 곧바로 사용하기보다는, 넓은 사진에서 얼굴을 찾은 뒤 얼굴만을 확대해주는 알고리즘을 앞에 한 단계 추가해주는 것이 더 유용할 것이다. 단계를 나누면 더 편하게 모델을 개발할 수 있는 것이다.
자율 주행 자동차 개발 과정도 비슷하다. 자율 주행이라는 것이 무엇인가? 주변 상황을 인식하고, 그로부터 자동차의 움직임을 결정하며, 그 자동차를 실제로 움직이는 모든 과정을 말하는 것이다. 이 과정을 end-to-end로 한 번에 처리하는 것은 말이 안된다. 각각의 단계를 나누어 개발하는 편이 더 쉬울 것이다.
End-to-end 딥러닝은 분명 매력적인 부분이 많지만, 우리가 처한 상황을 제대로 판단하고 사용해야 한다.
모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기