
단일 기준 오차 분석
고양이 구분 프로그램의 dev set에서 90%의 정확도를 보였다고 하자. 즉, 오차가 10%인 것이다. 오차의 원인 중 하나는 강아지 사진들이 고양이 사진으로 분류된 것이었다. 오차율을 줄이기 위해 강아지 사진을 더 잘 분류하도록 모델을 수정해야할까? 과연 그 일에 시간을 쏟을 가치가 있을까?
이를 판별하기 위해서는 dev set의 예시들 중에 기계가 잘못 분류한 수와 그 중에 강아지 사진이 몇 개인지를 파악해야 한다. 만약 100개의 잘못 분류된 예시 중에 강아지 사진이 5개라면, 강아지 분류 문제를 해결하더라도 오차율은 단 5%만 감소한다. 오차율이 9.5%가 된다는 뜻이다. 별로 도움이 안 될 것이다.
그러나 100개 중 50개가 강아지 사진이라면 오차율은 무려 50%가 감소하여 5%로 줄어들 것이다. 강아지 문제를 해결하기만 한다면 획기적인 개선을 기대할 수 있다.
앞서 우리가 한 과정은 ceiling(천장)을 파악하는 것이다. 문제 해결이 얼마나 도움이 될 지 그 한계를 파악한다면 우리가 거기에 시간을 쏟을지 말지가 결정될 것이다.
복수 기준 오차 분석
앞서 한 가지 문제에 대해 해결을 할지 말지를 결정하는 과정을 보았다. 만약 감지된 문제 발생 지점이 여러 개라면 어떻게 해야할까?
이 경우 표를 만들어보는 것이 좋다. 아래와 같이 말이다.
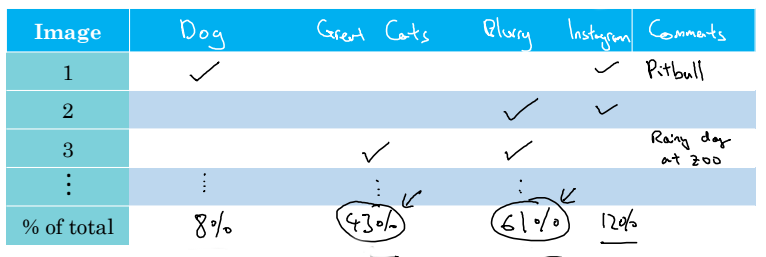
표의 가장 윗 줄에 문제가 발생한 기준들을 쓰고, dev set의 모든 예시들에 대해 검토를 진행하여 각 예시들에 대한 사유들을 파악해보는 것이다. 위 표에 따르면 Image 1은 강아지와 인스타그램 필터에 의해 오류가 발생하였다. Image 2는 흐릿한 사진이라 오류가 발생하였다.
이처럼 모든 예시들에 대해 원인 조사를 하고, 각 기준의 비율을 계산해서 가장 높은 비율의 문제부터 우선적으로 해결하면 된다.
잘못된 레이블된 예시 고치기
여기서는 잘못 레이블 된 예시를 고쳐야하는지 여부를 판단하는 방법을 살펴본다.
먼저 training set을 알아보자. 지도학습에서, 우리가 training set의 데이터를 제공할 때 잘못 레이블된 데이터가 끼어 있을 수 있다. 흰 강아지를 고양이로 레이블하는 것처럼 말이다.
다행히도, training set의 잘못 레이블된 데이터는 랜덤하기만 하다면 큰 문제는 되지 않는다. 즉, 계속해서 흰 강아지를 고양이로 분류해서 training set으로 제공하는 것은 문제가 되지만, 그렇지 않은 경우에는 크게 상관이 없다는 뜻이다.
하지만 dev set의 경우에는 조금 민감하게 살펴볼 필요가 있다. 여기서는 앞서 만든 표를 다시 활용하는데, 오류 기준에 ‘잘못 레이블됨’을 추가한다.

그리고 똑같이 그 비율을 조사하면 된다. 아래와 같이 말이다.
| 오차 종류 | Case 1 | Case 2 |
|---|---|---|
| Dev set에서의 전체 오차율 | 10% | 2% |
| 잘못 레이블된 데이터에 의한 오류 | 0.6% | 0.6% |
| 다른 이유에 의한 오류 | 9.4% | 1.4% |
Case 1을 보자. 잘못 레이블된 데이터에 의한 오류가 전체 오차의 6%에 불과하다. 반면, Case 2에서는 30%에 달한다. Case 1에서는 다른 이유들을 해결하는 것에 집중하는 게 좋지만, Case 2에서는 잘못 레이블된 데이터를 수정해주는 것도 효과적일 것이다.
잘못 레이블된 데이터를 수정할 때 알아야 하는 몇 가지 사항을 살펴보자.
- 앞선 다른 강의에서도 보았지만, dev set과 test set의 분포는 동일해야 한다. Dev set의 레이블을 바꾸어 주었다면 test set의 레이블도 바꾸는 것이 좋다.
-
모델이 오답으로 분류한 예시뿐만 아니라 정답으로 분류한 것도 다시 살펴보면
개선에 더 도움이 된다. 선생님이 중간고사 채점을 맞게 했는지 검토할 때, 틀린 문제뿐만 아니라 맞은 문제도 다시 살펴봐야 하는 것과 같은 이치이다.
- Training set의 분포는 dev set, test set과 조금 달라도 문제가 되지 않는다.
초기 시스템을 빠르게 구축하라.
딥러닝 모델을 만들 때 다음과 같은 절차를 따르면 한결 수월할 것이다.
- Dev set, test set, 척도를 세운다.
- 초기 시스템을 빠르게(대충) 구축한다.
- 편향, 분산, 오차 데이터를 이용해 모델의 개선 방향을 정한다.
대부분의 개발자들이 간과하는 것이 2번이다. 처음 시스템을 구축할 때 너무 복잡하게 만드려고 하기보다는 일단 대충 만들어 놓고 개선 방향을 정하는 것이 더 낫다.
모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기