
인간 수준의 성능과 AI 성능 발전 속도의 상관관계
우리는 인공지능 모델이 인간 수준의 성능을 내기를 바란다. 심지어 간혹 인간의 수준을 뛰어넘기를 바랄 때도 있다.
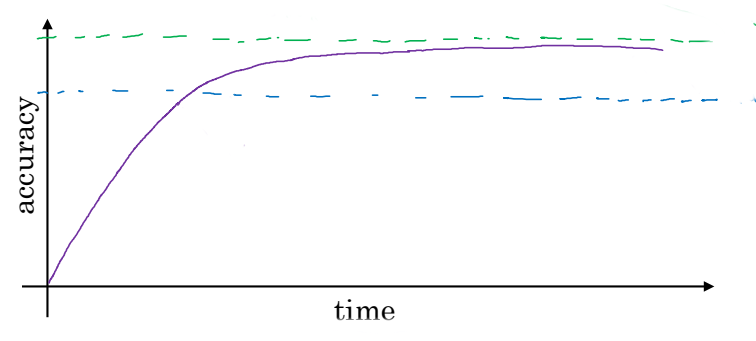
위 그래프는 시간에 따른 인공지능 모델의 성능 그래프이다. 아래쪽 점선은 인간 수준의 성능을 뜻하는데, AI 모델은 그 수준까지는 빠른 속도로 발전한다. 그러나 윗 점선인 최적의 성능, 즉 베이지안 최적 오차까지는 천천히 발전한다.
베이지안 최적 오차(Bayes optimal error)는 이론적인 성능의 한계를 의미한다. 어떠한 모델, 사람이든 간에 이 오차보다 더 작은 오차를 낼 수는 없다.
AI 모델은 왜 사람의 성능을 넘어서면 발전 속도가 급격히 감소할까?
그 이유는 크게 두 가지가 있다.
먼저, 사람의 성능은 베이지안 오차와 유사하다. 예를 들어, 사람은 고양이 사진을 거의 실수 없이 구분해낼 수 있다. 사람의 성능이 한계에 가깝기 때문에, 그 수준을 넘어서기가 힘들고, 설령 넘어선다고 하더라도 이미 매우 높은 수준에 도달했기에 더 발전하기가 쉽지 않다.
다른 이유는 인간의 성능을 뛰어넘기 전까지 사용했던 성능 향상 기법을 더 이상 사용할 수 없기 때문이다. 인간의 성능을 뛰어넘기 전에는 성능 향상을 촉진하기 위해 인간에 의해 정답이 레이블된 데이터를 사용하거나 (앞으로 배울) 수동 오차 분석으로 아이디어를 얻을 수 있다. 편향과 분산에 대해 더 좋은 분석을 얻을 수도 있다. 그러나 인간의 성능을 뛰어넘는 순간 이 방법들을 사용할 수 없기에 AI 모델의 발전이 느려진다.
회피 가능 편향
인간 수준 오차와 Training 오차의 간격을 회피 가능 편향(Avoidable bias)라고 한다.
| 오차 종류 | Case 1 | Case 2 |
|---|---|---|
| Humans ($\approx$ Bayes) | 1% | 7.5% |
| Training | 8% | 8% |
| Dev | 10% | 10% |
Case 1을 먼저 보자. Training 오차와 Dev 오차의 간격, 즉 분산보다 회피 가능 편향이 더 크다. 이 경우 회피 가능 편향을 줄이는 데 집중해야 한다.
Case 2에서는 분산이 더 크다. 회피 가능 편향은 비교적 작다. 분산을 줄이는 데 집중해야 한다.
우리는 앞서 최소 오차(0%)와 Training 오차의 간격을 편향으로 정의했다. 회피 가능 편향이라는 단어는 아직 편향을 더 줄일 수 있다는 의미를 내포하고 있다.
‘인간 수준 성능’은 가이드다.
인간 수준 성능이란 무엇을 의미할까? 인간의 오차에는 다양한 종류가 있을 수 있다. 한 사람의 오차, 여러 사람이 같이 고민해서 낸 결론의 오차, 전문가의 오차, 비전문가의 오차 등등… 그러나 중요한 사실은 우리는 인간 수준 오차를 베이지안 오차와 동일 선상에 놓을 것이라는 점이다. 즉, 인간 수준의 오차는 가장 작은 값을 선택하는 것이 맞다.
인간 수준 오차를 잘 선택하는 것은 중요하다. 우리가 AI 모델을 앞으로 어떻게 발전시킬지에 대해 일종의 가이드를 제공하기 때문이다. 만약 회피 가능 편향이 더 크다면 우리는 편향을 줄이는 방향으로 모델을 발전시켜야 하지만, 분산이 더 크다면 분산을 줄이는 방향으로 모델을 발전시킬 것이다.
회피 가능 편향과 분산의 차이가 좀 난다면 인간의 여러 오차 중 아무거나 선택해도 큰 상관이 없다. 그러나 회피 가능 편향과 분산이 소수점을 다투는 상황이라면 어떤 인간의 오차를 선택하느냐에 따라 앞으로의 개선 방향성이 아예 달라질 수 있다.
인간 수준의 성능 뛰어넘기
AI 모델이 인간의 성능을 뛰어넘는 것은 매우 어렵지만 불가능하지는 않다. 최근에는 다양한 사례들에서 인간의 성능을 뛰어넘는 모델들이 등장하고 있다. 예를 들어, 온라인 광고, 제품 추천, 유통 시간 예측, 대출 승인 여부 등의 분야에서는 인간보다 AI의 분석을 믿는 것이 더 좋다.
위 사례들은 모두 공통점이 있다. 구조화된 데이터를 사용하고, 자연 인지 문제가 아니며, 많은 양의 데이터를 기반으로 한다는 것이다.
특히 언어 인식, 이미지 분류, 의료 진단과 같은 자연 인지 문제는 AI 모델로는 인간의 성능을 뛰어넘기 매우 힘든 분야이다. 그러나 최근에는 이 분야에서마저도 인간의 성능을 초월하는 모델들이 등장하고 있다.
모델의 성능을 개선하는 방법
지도 학습 알고리즘이 잘 작동하려면 아래의 두 과정을 거쳐야 한다.
- Training set에 잘 들어맞기. $\rightarrow$ 회피 가능 편향 줄이기
- Training set의 성능이 Dev set, test set에도 잘 작동하도록 일반화 하기 $\rightarrow$ 분산 줄이기
편향과 분산을 줄이는 것은 다음과 같은 방법으로 가능하다.
| 줄이고자 하는 것 | |
|---|---|
| 회피 가능 오차 | - 더 큰 모델 사용 - 더 길고 나은 최적화 알고리즘 사용(ex. 모멘텀, RMSprop, Adam) - 신경망 구조 및 초매개변수 바꾸기 |
| 분산 | - 더 많은 데이터 - 정규화 - 신경망 구조 및 초매개변수 바꾸기 |
모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기