
About this Article
- Authors: Jeongho Kim, Hoiyeong Jin, Sunghyun Park, Jaegul Choo
- Journal: arXiv
- Year: 2025
- Official Citation: Kim, J., Jin, H., Park, S., & Choo, J. (2025). PromptDresser: Improving the Quality and Controllability of Virtual Try-On via Generative Textual Prompt and Prompt-aware Mask. arXiv preprint arXiv:2412.16978.
Accomplishments
- Developed PromptDresser, a powerful virtual clothing tool with distinctive masking techniques.
Key Points
1. Overview
PromptDresser is a text-prompted based virtual dresser. PromptDresser can change the clothing item based on the provided clothing image. edit the wearing style with text prompting. It has three key features.
- Prompt generation by using LMM.
- Prompt-aware Mask Generation(PMG)
- Random dilation mask augmentation
2. Architecture
1. Latent Diffusion Model (LDM)
To make the model understand the image well(here, well means to learn characteristics which is useful dressing), authors used diffusion. LDM consists of three components
- Variational Auto-Encoder (VAE) with an Encoder $g(\cdot)$ and Decoder $g(.)$
- Text Encoder $\tau(\cdot)$
- Main U-Net $\epsilon_{\beta}(\cdot)$
Details of components:
- VAE Encoder: Encodes an image x into a low-dimensional latent space. $z_{0}=\delta(x)$
- VAE Decoder: Changes latent space vector back to RGB space. $\hat{x}=$(z_{0})$
- U-Net: Trained to predict the original noise e from the noised latent variable $z_{t}$. By subtracting this predicted noise, it can restore $z_{0}$
-
Loss function of LDM: Minimize the difference between original noise($\epsilon$) and predicted noise
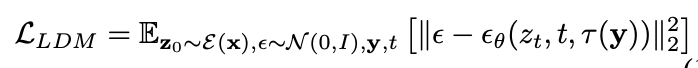
, where $\tau(y)$ is an encoded text prompt.
2. Overall Framework
Steps: (1) LMMs produce text prompts of the input image by using given attributes. One produces text prompts (main prompt) just about a person(e.g. pose) and the other produces text prompts (reference prompt) about clothings.
(2) Main prompt is processed by text encoder and goes into the main U-Net as a condition which the NN should follow.
(3) Reference prompt is processed by text encoder and goes into reference U-Net as a condition which the NN should follow.
(4) Reference U-Net is a frozen net, preserves the details of clothings.
(5) After an input image of a clothing is processed through the reference U-Net, their layers are concatenated to the corresponding layers of main U-Net.
(6) Main U-Net generates the final output image.
Inputs of Main U-Net
- a noise image($z_{t}$)
- a resized dilated clothing-agnostic mask $(\mathbb{R}(m_{d}))$: Generated by random dilation mask augmentation
- a latent agnostic map $(\xi(x_{a}^{p}))$: Generated by VAE encoder and decoder.
3. Random Dilation Mask Augmentation
Random dilation mask augmentation is used during training to make the model be able to handle various types(length and fit) of masking. They randomly dilated(expanded) fine mask $m_{f}$ to the range of coarse(rough) mask $m_{c}$ for n times with a structuring element b (decide the rate and direction of dilation):
\[m_{d}=(m_{f}\oplus^{n}b)\cap m_{c}.\]4. Prompt-aware Mask Generation (PMG)
Prompt-aware mask generation is used during inference (actual use). By using an input image, PMG generates two types of maskings, one is a prompt-aware mask and the other is a fine-mask. Model uses the union of the two masks.
Figures & Table Explanation
1. Figure 1: Generated results of PromptDresser (Ours).
- (a): Qualitative comparison with other models.
- (b): Results when multiple attributes were given.
- (c): Only styles were changed.
2. Figure 4, Figure 5, Table 1, Table 2: Qualitative and quantitative evaluation of PromptDresser and other baselines.
PromptDresser generated the best quality image. It especially removed the shape of existing clothings (Figure 5), which is not good at other baselines. In quantitative evaluation, PromptDresser was good at unpaired (no answer) test, FID and KID. By adding DensePose (pose-specialized NN), it($Ours_{pose}$) was also good at paired (answer images exist) text. However, Ourspose was not good at unpaired test, authors decided not to use pose-specified conditioning. Table 2 is also a quantitative comparison on the other dataset. It shows the result according to the part of a body.
3. Table 3: Results of text alignment test.
To check whether the model reflects the prompt as intended, authors conducted text alignment test. They fixed tucking style and fit attributes in one type and evaluated whether the model’s output reflected the attributes correctly by using LMM. Table 3 shows the ratio of correctly generated images, and PromptDresser was the best.
4. Figure 6, Table 4: Results of ablation study.
Figure 6 is the result with holistic description about the image by LMM, without pre-determined attributes. As the specified attributes to focus on were missing, LMM cannot distinguish whether a attribute is important or not, and therefore, the result was not good(fit was not preserved). Figure 4 is the result without PMG. Without PMG, the coarse mask was often inaccurate.
5. Figure 7: Extended application result (adding outerwear).
Baseline model couldn’t layer the outerwear, removing the existing clothing and fit the outerwear to the area. However, PromptDresser could layer the new clothing on the existing inner wear.
6. Figure 8: Results of user study.
Forty participants rated several models on two datasets (Figure 8a, b). And they also checked whether the result is aligned with the prompts (Figure 8c). PromptDresser was the best.
댓글남기기