
이번 시간에는 matplotlib의 다양한 기능에 대해 공부한다.
matplotlib
matplotlib은 파이썬의 데이터 시각화를 위한 도구이다. 판다스를 연동해서 사용할 수도 있다.
matplotlib 기본 사용법
matplotlib에서는 pyplot 객체를 사용해서 데이터를 표시한다. pyplot 객체에는 figure라는 모판이 있고, plt.show()를 통해 이를 나타내면 모판을 모두 비우는 작업(flush라고 한다)으로 지금까지 그려왔던 그림을 보여준다.
몇 가지 기본적인 코드를 살펴보자.
import matplotlib.pyplot as plt
X = range(100)
Y = [value**2 for value in X]
plt.plot(X, Y)
plt.show()
import numpy as np
X_1 = range(100)
Y_1 = [np.cos(value) for value in X]
X_2 = range(100)
Y_2 = [np.sin(value) for value in X]
plt.plot(X_1, Y_1)
plt.plot(X_2, Y_2)
plt.show()
두 번째 예시에서 plt.plot()으로 모판에 그림을 그린 뒤, plt.show()를 통해 flush하는 과정이 잘 드러난다.
색깔 지정
color = 혹은 c=로 그래프의 색을 지정해줄 수 있다.
X_1 = range(100)
Y_1 = [value for value in X]
X_2 = range(100)
Y_2 = [value + 100 for value in X]
plt.plot(X_1, Y_1, color="#eeefff")
plt.plot(X_2, Y_2, c="r")
plt.show()
라인 스타일 지정
linestyle=, ls=로 라인의 스타일도 지정해줄 수 있다.
plt.plot(X_1, Y_1, c='b', linestyle='dashed')
plt.plot(X_2, Y_2, c='r', ls='dotted')
plt.show()
제목 지정
제목은 다음과 같이 지정한다.
plt.plot(X_1, Y_1, c='b', linestyle='dashed')
plt.plot(X_2, Y_2, c='r', ls='dotted')
plt.title("Two Lines") #제목 지정
plt.show()
제목에는 Latex 타입의 수식도 넣을 수 있다.
범례 지정
legend 함수로 범례를 표시할 수 있다. loc=로 범례의 위치를 지정할 수 있다.
plt.plot(X_1, Y_1, c='b', ls='dashed', label='line_1')
plt.plot(X_2, Y_2, c='r', ls='dotted', label='line_2')
plt.legend(shadow=True, fancybox=True, loc="lower right")
plt.show()
그래프 그리드(grid), XY축 한계 지정
그래프의 그리드(grid)와 x, y축의 범위 한계도 지정할 수 있다.
plt.plot(X_1, Y_1, c='b', ls='dashed', label='line_1')
plt.plot(X_2, Y_2, c='r', ls='dotted', label='line_2')
plt.legend(shadow=True, fancybox=True, loc="lower right")
plt.grid(True, lw=0.4, ls='--', c=".90")
plt.xlim(-100, 200)
plt.ylim(-200, 200)
자세히 보면 그리드가 있다
다양한 그래프 그리기
matplotlib은 산점도, 막대 그래프 등 다양한 모양의 그래프를 지원한다.
산점도
산점도는 scatter함수를 사용한다. marker=로 scatter의 모양을 지정할 수 있다.
data_1 = np.random.rand(512, 2)
data_2 = np.random.rand(512, 2)
plt.scatter(data_1[:, 0], data_1[:, 1], c='b', marker='x')
plt.scatter(data_2[:, 0], data_2[:, 1], c='r', marker='^')
plt.show()
s=로 데이터의 크기를 지정할 수 있다. 원의 크기를 달리해서 데이터의 크기를 비교할 때 용이하게 사용할 수 있다.
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = np.pi * (15 * np.random.rand(N)) ** 2
plt.scatter(x, y, s=area, c=colors, alpha=0.5)
plt.show()
alpha=는 투명도를 지정한다.
막대 그래프
bar함수를 사용하면 막대 그래프를 그릴 수 있다.
data = [[5., 25., 50., 20.],
[4., 23., 51., 17],
[6., 22., 52., 19]]
X = np.arange(0,8,2)
plt.bar(X + 0.00, data[0], color = 'b', width = 0.50)
plt.bar(X + 0.50, data[1], color = 'g', width = 0.50)
plt.bar(X + 1.0, data[2], color = 'r', width = 0.50)
plt.xticks(X + 0.50, ("A","B","C","D")) # x축 눈금 지정
plt.show()
쌓은 막대 그래프를 그릴 수도 있다.
color_list = ['b', 'g', 'r']
data_label = ["A","B","C"]
X = np.arange(data.shape[1])
for i in range(data.shape[0]): # 데이터 쌓기
plt.bar(X, data[i], bottom = np.sum(data[:i], axis = 0), color = color_list[i], label=data_label[i])
plt.legend()
plt.show()
히스토그램
히스토그램도 가능하다. hist함수를 쓴다.
X = np.random.randn(100)
plt.hist(X, bins=100)
plt.show()
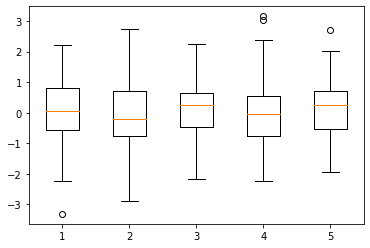
boxplot
실험 결과를 나타낼 때 주로 많이 사용하는 boxplot도 그릴 수 있다.
data = np.random.randn(100, 5)
plt.boxplot(data)
plt.show()
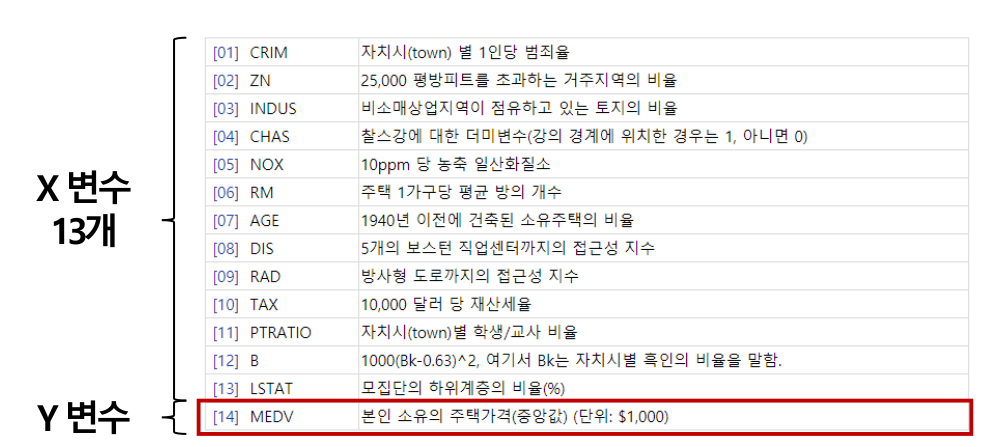
판다스와 matplotlib
판다스 데이터를 matplotlib으로 시각화 할 수 있다. 지난 강의에서 살펴보았던 보스턴 집 값 데이터를 시각화해보자.
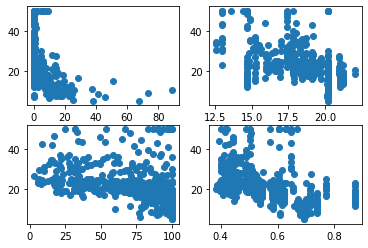
먼저, 데이터의 상관관계를 scatter로 살펴보자.
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data_url = './housing.data'
df_data = pd.read_csv(data_url, sep='\s+', header = None)
df_data.columns = [
'CRIM','ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO' ,'B', 'LSTAT', 'MEDV'] # Column Header 이름 지정
df_data.head()
fig = plt.figure()
ax = []
for i in range(1, 5):
ax.append(fig.add_subplot(2, 2, i))
ax[0].scatter(df_data['CRIM'], df_data['MEDV'])
ax[1].scatter(df_data['PTRATIO'], df_data['MEDV'])
ax[2].scatter(df_data['AGE'], df_data['MEDV'])
ax[3].scatter(df_data['NOX'], df_data['MEDV'])
plt.show()
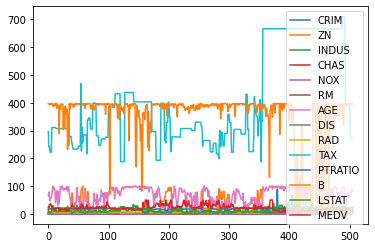
그냥 plot 함수로 전체 데이터의 그래프를 그릴 수도 있다.
df_data.plot()
각 column의 데이터를 그래프로 그려보자.
fig = plt.figure()
ax_1 = fig.add_subplot(1, 2, 1)
ax_2 = fig.add_subplot(1, 2, 2)
ax_1.plot(df_data['MEDV'])
ax_2.hist(df_data['MEDV'], bins=50)
ax_1.set_title("House price MEDV")
ax_2.set_title("House price MEDV")
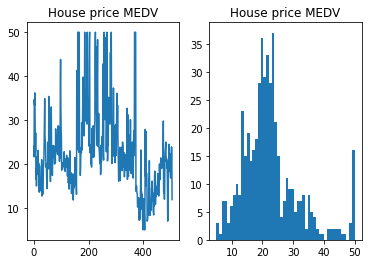
위 코드에서 사용된 add_subplot은 2개 이상의 그래프를 동시에 그릴 때 유용하게 사용할 수 있다.
add_subplot(행의 수, 열의 수, index)
2개 이상의 그래프를 화면에 표현하는 방법을 지정하는 것이라고 이해하면 된다. 위의 예시에서는 2개의 그래프가 등장한다. 행의 수가 1, 열의 수가 2이므로 두 그래프가 가로로 배치되고, 각 그래프에 대해 인덱스를 지정하여 그 순서대로 나타난다.
이번엔 boxplot으로 그려보자.
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scale_data = std_scaler.fit_transform(df_data)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.boxplot(scale_data, labels=df_data.columns)
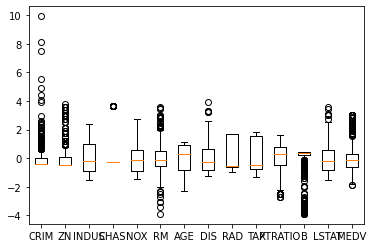
StandardScaler는 데이터를 평균 0 , 분산 1로 조정한다. 위 그래프는 스케일이 다른 column들을 한 boxplot에 나타내야 하기 때문에 스케일 조정이 필요하다.
가장 유용하게 사용될 그래프는 다음 scatter_matrix라고 생각한다. 모든 column들에 대해서 상관관계를 한 번에 보여준다.
pd.plotting.scatter_matrix(df_data, diagonal='kde', alpha=1)
plt.show()
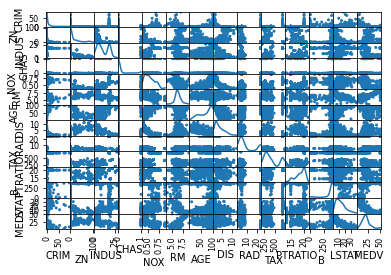
대각선에는 해당 column의 분포가, 나머지에는 column간의 상관관계가 나타난다.
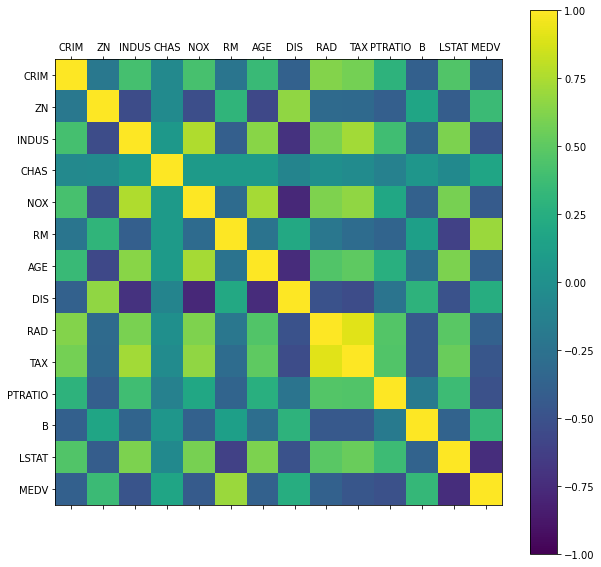
다음처럼 색깔로 표현할 수도 있다.
corr_data = np.corrcoef(scale_data.T)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
cax = ax.matshow(corr_data, vmin=-1, vmax=1, interpolation='nearest')
fig.colorbar(cax)
fig.set_size_inches(10, 10)
ticks = np.arange(0, 14, 1)
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(df_data.columns)
ax.set_yticklabels(df_data.columns)
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기