
이번 시간에는 지난 시간에 이어 Pandas의 다양한 기능에 대해 공부한다.
Groupby 기본
Groupby는 데이터를 분할하고(split), 함수를 적용한 다음(apply), 합치는(combine) 역할을 한다.
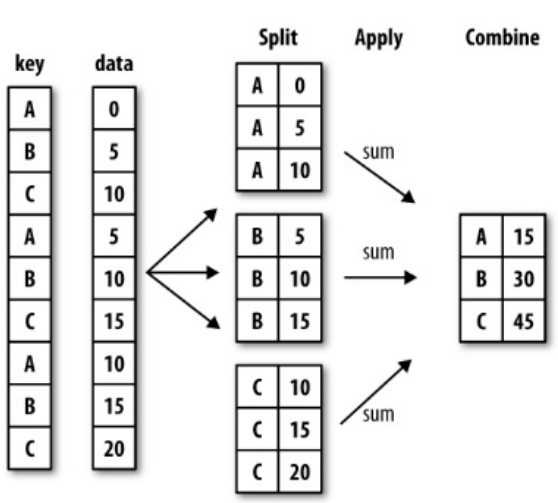
코드는 다음과 같다.
df.groupby("묶음의 기준이 되는 column")["적용받는 column"].sum()
sum외에 다른 연산을 사용할 수도 있다. Groupby를 적용한 전 후를 비교하면 다음과 같다.
>>> df
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
2 Devils 2 2014 863
3 Devils 3 2015 673
4 Kings 3 2014 741
5 kings 4 2015 812
6 Kings 1 2016 756
7 Kings 1 2017 788
8 Riders 2 2016 694
9 Royals 4 2014 701
10 Royals 1 2015 804
11 Riders 2 2017 690
>>> df.groupby("Team")["Points"].sum()
Team
Devils 1536
Kings 2285
Riders 3049
Royals 1505
kings 812
Name: Points, dtype: int64
한 개 이상의 column을 묶을 수도 있다.
>>> df.groupby(["Team", "Year"])["Points"].sum()
Team Year
Devils 2014 863
2015 673
Kings 2014 741
2016 756
2017 788
Riders 2014 876
2015 789
2016 694
2017 690
Royals 2014 701
2015 804
kings 2015 812
Name: Points, dtype: int64
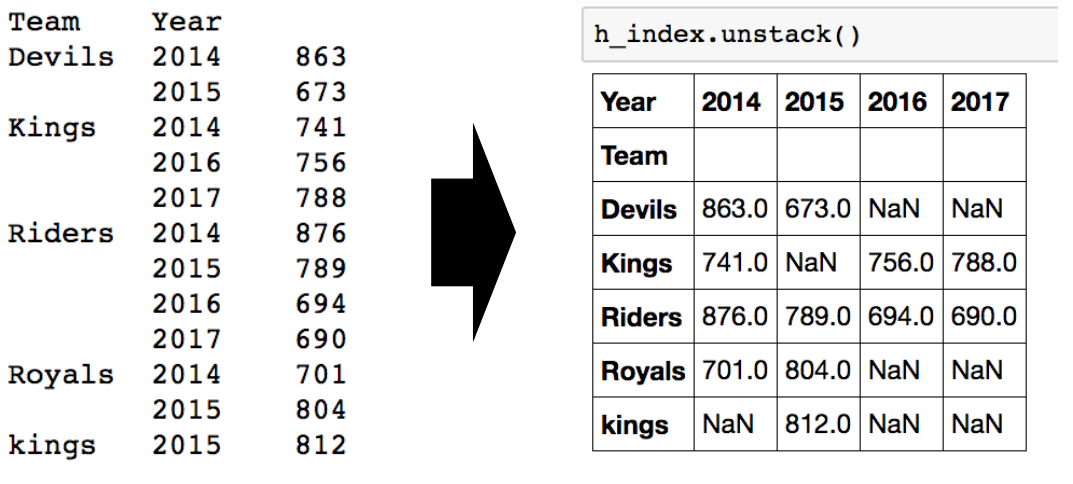
두 개의 column으로 groupby를 할 경우 인덱스가 2개 생긴다. 이를 unstack()을 통해 행렬로 바꿀 수 있다.
>>> h_index = df.groupby(["Team", "Year"])["Points"].sum()
>>> h_index.unstack()
Year 2014 2015 2016 2017
Team
Devils 863.0 673.0 NaN NaN
Kings 741.0 NaN 756.0 788.0
Riders 876.0 789.0 694.0 690.0
Royals 701.0 804.0 NaN NaN
kings NaN 812.0 NaN NaN
swaplevel()을 이용하면 인덱스의 레벨을 바꿀 수 있다.
>>> h_index.swaplevel()
Year Team
2014 Devils 863
2015 Devils 673
2014 Kings 741
2016 Kings 756
2017 Kings 788
2014 Riders 876
2015 Riders 789
2016 Riders 694
2017 Riders 690
2014 Royals 701
2015 Royals 804
kings 812
Name: Points, dtype: int64
인덱스 레벨을 기준으로 기본적인 연산도 할 수 있다.
>>> h_index.sum(level=0)
Team
Devils 1536
Kings 2285
Riders 3049
Royals 1505
kings 812
Name: Points, dtype: int64
>>> h_index.sum(level=1)
Year
2014 3181
2015 3078
2016 1450
2017 1478
Name: Points, dtype: int64
>>>
Groupby 심화
분할(split)된 상태 자체를 추출할 수 있다.
>>> grouped = df.groupby("Team")
>>> for name, group in grouped:
... print(name)
... print(group)
...
Devils
Team Rank Year Points
2 Devils 2 2014 863
3 Devils 3 2015 673
Kings
Team Rank Year Points
4 Kings 3 2014 741
6 Kings 1 2016 756
7 Kings 1 2017 788
Riders
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
8 Riders 2 2016 694
11 Riders 2 2017 690
Royals
Team Rank Year Points
9 Royals 4 2014 701
10 Royals 1 2015 804
kings
Team Rank Year Points
5 kings 4 2015 812
당연히 특정 key 값을 가진 그룹만 추출할 수도 있다.
>>> grouped.get_group("Devils")
Team Rank Year Points
2 Devils 2 2014 863
3 Devils 3 2015 673
추출된 정보에는 다양한 적용(apply)이 가능하다. 먼저 aggregation을 살펴보자.
>>> grouped.agg(sum) # 합을 적용
Rank Year Points
Team
Devils 5 4029 1536
Kings 5 6047 2285
Riders 7 8062 3049
Royals 5 4029 1505
kings 4 2015 812
>>> import numpy as np
>>> grouped.agg(np.mean) # 평균을 적용
Rank Year Points
Team
Devils 2.500000 2014.500000 768.000000
Kings 1.666667 2015.666667 761.666667
Riders 1.750000 2015.500000 762.250000
Royals 2.500000 2014.500000 752.500000
kings 4.000000 2015.000000 812.000000
>>> grouped["Points"].agg([np.sum, np.mean, np.std]) # Points에 대해 다양한 연산 적용
sum mean std
Team
Devils 1536 768.000000 134.350288
Kings 2285 761.666667 24.006943
Riders 3049 762.250000 88.567771
Royals 1505 752.500000 72.831998
kings 812 812.000000 NaN
위는 합과 평균을 적용한 예시이다. 뿐만 아니라 람다 함수도 적용할 수 있다.
다음으로 살펴볼 transformation은 key값 별로 요약된 정보가 아니라 개별 데이터의 변환을 지원한다. 적용 예시를 살펴보자.
>>> df
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
2 Devils 2 2014 863
3 Devils 3 2015 673
4 Kings 3 2014 741
5 kings 4 2015 812
6 Kings 1 2016 756
7 Kings 1 2017 788
8 Riders 2 2016 694
9 Royals 4 2014 701
10 Royals 1 2015 804
11 Riders 2 2017 690
>>> score = lambda x: (x)
>>> grouped.transform(score)
Rank Year Points
0 1 2014 876
1 2 2015 789
2 2 2014 863
3 3 2015 673
4 3 2014 741
5 4 2015 812
6 1 2016 756
7 1 2017 788
8 2 2016 694
9 4 2014 701
10 1 2015 804
11 2 2017 690
>>> score = lambda x: (x.max())
>>> grouped.transform(score)
Rank Year Points
0 2 2017 876
1 2 2017 876
2 3 2015 863
3 3 2015 863
4 3 2017 788
5 4 2015 812
6 3 2017 788
7 3 2017 788
8 2 2017 876
9 4 2015 804
10 4 2015 804
11 2 2017 876
두 번째 예시를 집중해서 보자. 같은 key값에 대해서, 각 특성의 최대 값으로 모든 데이터가 대체된 것을 확인할 수 있다.
마지막으로 filter는 특정 조건으로 데이터를 검색할 때 사용한다. 만약 ‘Team’별로 그룹을 묶되, 데이터의 개수가 3개 이상인 것만 검색하고 싶으면 다음과 같이 하면 된다.
>>> df.groupby("Team").filter(lambda x: len(x) >= 3)
Team Rank Year Points
0 Riders 1 2014 876
1 Riders 2 2015 789
4 Kings 3 2014 741
6 Kings 1 2016 756
7 Kings 1 2017 788
8 Riders 2 2016 694
11 Riders 2 2017 690
여기까지 배웠으면 다음 코드의 의미를 해석할 수 있어야 한다.
df_phone[df_phone['item'] == 'call'].groupby('network')['duration'].sum()
천천히 해석해보자. 먼저 df_phone이라는 dataframe 중에 ‘item’ 특성이 ‘call’인 것만 추출한다. 그리고 이 데이터만을 대상으로 groupby를 진행하는데, ‘network’를 기준으로 묶어줄 것이다. 또한 그냥 묶는 것이 아니고, ‘duration’을 합해서(sum) 묶어줄 것이다.
다음 코드도 해석해보자.
df_phone.groupby(['month', 'item']).agg({'duration':sum, 'network_type': "count", 'date': 'first'})
‘month’와 ‘item’을 기준으로 묶을 예정인데, 특성마다 적용하는 연산이 좀 다르다. ‘duration’에는 합을 구하고, ‘network_type’에는 개수를 세고, ‘date’는 가장 앞선 날짜를 추출한다.
하나의 특성에 대해 다양한 연산을 적용하고 싶으면 다음과 같이 써도 된다.
df_phone.groupby(['month', 'item']).agg({'duration': [min], 'network_type': "count", 'date': [min, 'first', 'nunique']})
피벗 테이블과 크로스탭
사실 피벗 테이블과 크로스탭 없이도 위에서 사용한 groupby를 잘 쓰면 거의 모든 것을 할 수 있다. 그래도 뭐라도 한 가지 더 알고 있는 것이 좋으니 배워보자.
피벗 테이블은 엑셀에서 사용한 그것과 동일하다.
df_phone.pivot_table(['duration'], index = [df_phone.month, df_phone.item], columns = df_phone.network, aggfunc = "sum", fill_value = 0)
위 코드의 실행 결과는 다음과 같다.
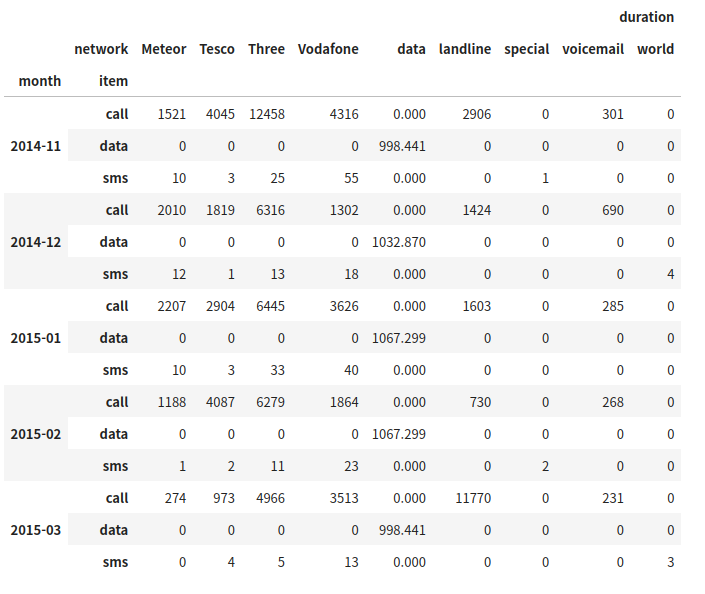
어떤 요소가 어디에 들어가는지를 잘 살펴보자.
크로스탭은 두 column의 교차 빈도, 비율, 덧셈 등을 구할 때 사용할 수 있다. 피벗 테이블의 특수한 형태라고 생각하면 된다.
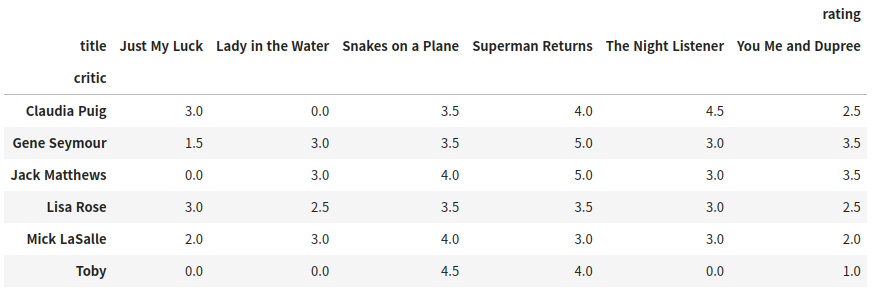
일단 다음과 같은 데이터가 있다.
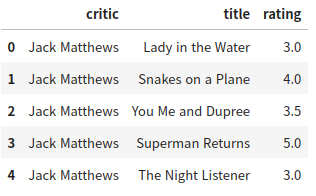
다음 코드를 적용하면 크로스탭을 구할 수 있다.
pd.crosstab(index = df.movie.critic, columns = df.movie.title, values = df.movie.rating, aggfunc = 'first').fillna(0)
Merge
Merge는 두 개의 데이터를 하나로 합치는 기능이다. 기본적인 사용법은 다음과 같다.
>>> df_a
subject_id test_score
0 1 51
1 2 15
2 3 15
3 4 61
4 5 16
5 7 14
6 8 15
7 9 1
8 10 61
9 11 16
>>> df_b
subject_id first_name last_name
0 4 Billy Bonder
1 5 Brian Black
2 6 Bran Balwner
3 7 Bryce Brice
4 8 Betty Btisan
>>> pd.merge(df_a, df_b, on='subject_id')
subject_id test_score first_name last_name
0 4 61 Billy Bonder
1 5 16 Brian Black
2 7 14 Bryce Brice
3 8 15 Betty Btisan
‘subject_id’를 기준으로 하여 합쳤다. 만약 기준으로 삼고 싶은 두 column의 이름이 다르다면 다음처럼 쓰면 된다.
pd.merge(df_a, df_b, left_on='subject_id', right_on='subject_id')
Join의 방식에는 다음처럼 네 가지가 있다.
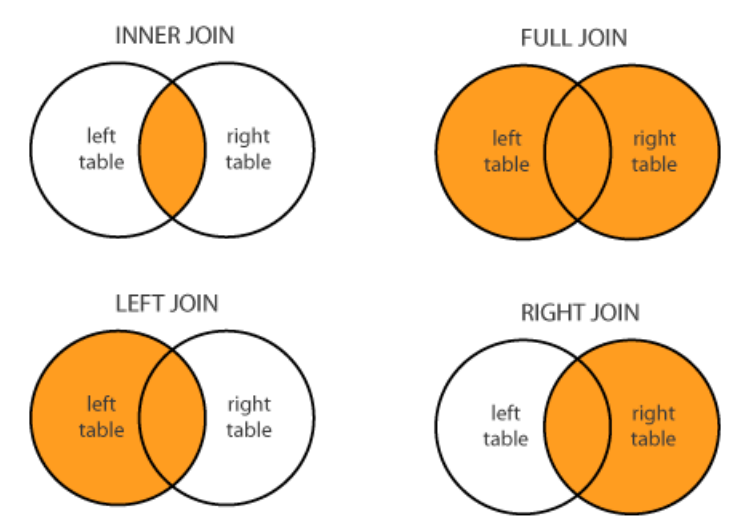
기본적으로 merge는 inner join을 한다. 만약 full join으로 누락되는 데이터 없이 모두 표현하고 싶다면 다음처럼 하면 된다.
>>> pd.merge(df_a, df_b, on='subject_id', how='outer')
subject_id test_score first_name last_name
0 1 51.0 NaN NaN
1 2 15.0 NaN NaN
2 3 15.0 NaN NaN
3 4 61.0 Billy Bonder
4 5 16.0 Brian Black
5 7 14.0 Bryce Brice
6 8 15.0 Betty Btisan
7 9 1.0 NaN NaN
8 10 61.0 NaN NaN
9 11 16.0 NaN NaN
10 6 NaN Bran Balwner
모든 ‘subject_id’에 대해서 merge 되었다. Left join은 how='left', right join은 how='right'로 한다.
DB Persistence
열심히 처리한 데이터를 다음에도 사용하거나 공유할 일이 많을 것이다. 크게 3가지 방법으로 이를 처리할 수 있다.
먼저, 데이터를 로드할 때 데이터베이스와 연결해 놓을 수 있다.
import sqlite3
conn = sqlite3.connect("./data/flights.db")
cur = conn.cursor()
cur.execute("select * from airlines limit 5;")
results = cur.fetchall()
results
Dataframe 생성은 다음과 같이 한다.
df_airplines = pd.read_sql_query("select * from airlines;", conn)
다음으로 엑셀로 저장할 수 있다.
writer = pd.ExcelWriter('./data/df_routes.xlsx', engine='xlsxwriter')
df_routes.to_excel(writer, sheet_name = 'Sheet1')
참고로 위 방법을 사용하려면 openpyxl과 XlsxWriter이 설치되어 있어야 한다.
마지막으로 가장 많이 사용하는 방법은 pickle을 사용하는 것이다. Pickle은 가장 일반적인 파이썬 파일 persistence이다.
df_routes.to_pickle("./data/df_routes.pickle") # 데이터 저장
df_routes_pickle = pd.read_pickle("./data/df_routes.pickle") # 데이터 불러오기
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기