
머신러닝 & 데이터 분석에 사용되는 도구들
머신러닝과 데이터 분석에 사용하는 파이썬 관련 도구들은 다음과 같다.
| 도구 | 설명 |
|---|---|
| ANACONDA | 과학 계산용 파이썬 모듈이 통합되어 있음. |
| CONDA | 파이썬 가상 환경 관리 패키지. |
| Jupyter | 데이터 분석을 위한 파이썬 IDE. |
| pandas | 파이썬 데이터 분석 라이브러리. |
| NumPy | 고성능 array 처리 라이브러리. |
| matplotlib | 데이터 시각화를 위한 파이썬 패키지. |
머신러닝 개발 과정
머신러닝의 기본적인 개발 과정은 다음과 같다.
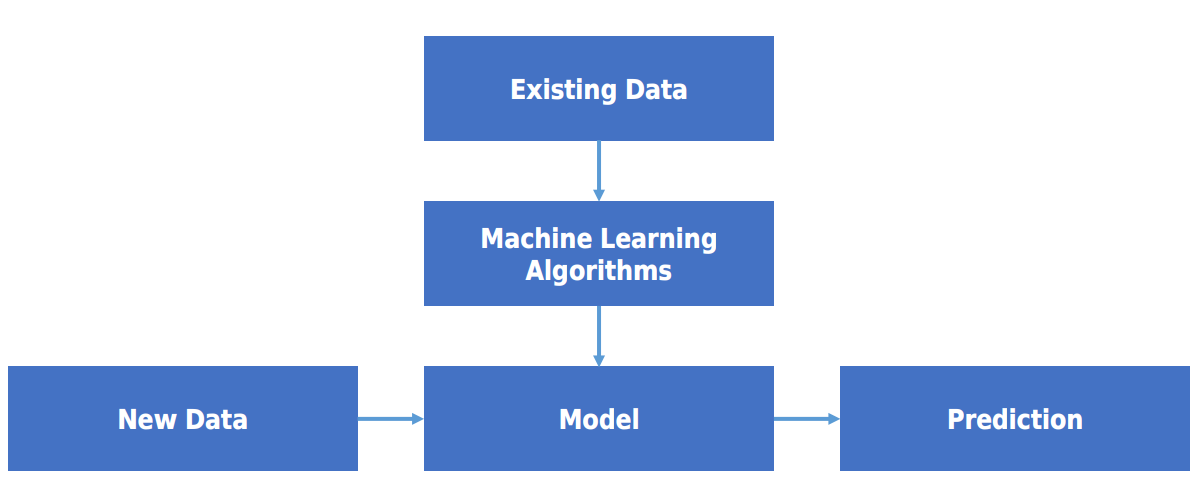
먼저, 기존에 존재하는 데이터를 이용해 머신러닝 모델을 개발한다. 모델을 개발할 때는 머신러닝 알고리즘을 사용해야 한다. 모델과 알고리즘의 정확한 정의는 다음과 같다.
- 모델(model): 예측을 위한 수학 공식, 함수, 확률 분포 등.
- 알고리즘(algorithms): 문제를 풀기 위한 과정. 모델을 생성하기 위한 훈련 과정.
모델을 만들었으면 새로운 데이터를 사용해 예측을 생성한다.
예시를 살펴보자. 봉준호 감독의 영화 영화 ‘옥자’는 멀티플렉스에서 개봉하지 못하고 넷플릭스를 통해 공개되었다. 다음은 만약 ‘옥자’가 제대로 개봉되었다면 얼마나 많은 관객을 모았을까를 분석한 것이다.
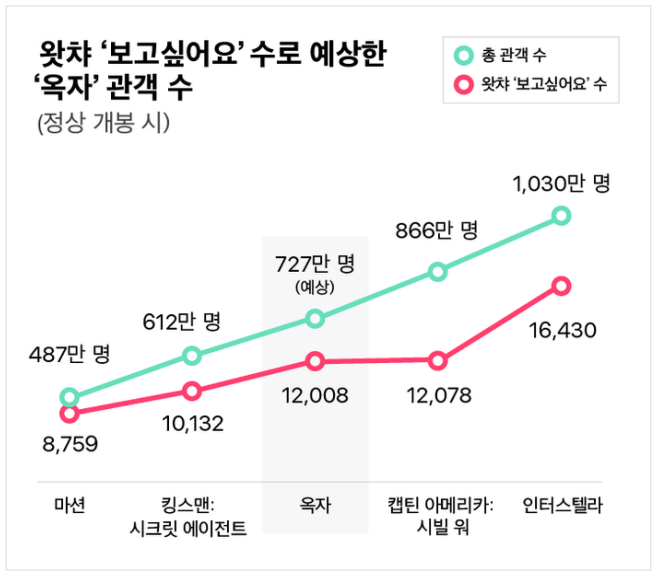
OTT 왓챠의 ‘보고싶어요’ 수를 이용해 관객 수를 짐작했다. 정상적으로 개봉한 다른 영화의 ‘보고싶어요’ 수와 관객 수의 상관관계를 구한 뒤 이를 ‘옥자’에 적용하였다 (이 과정이 알고리즘이다). 분석에는 단순한 선형 회귀(일차 함수)가 사용되었음을 짐작할 수 있다. 여기서 일차 함수 식이 모델이 된다.
모델 학습에 영향을 주는 것들
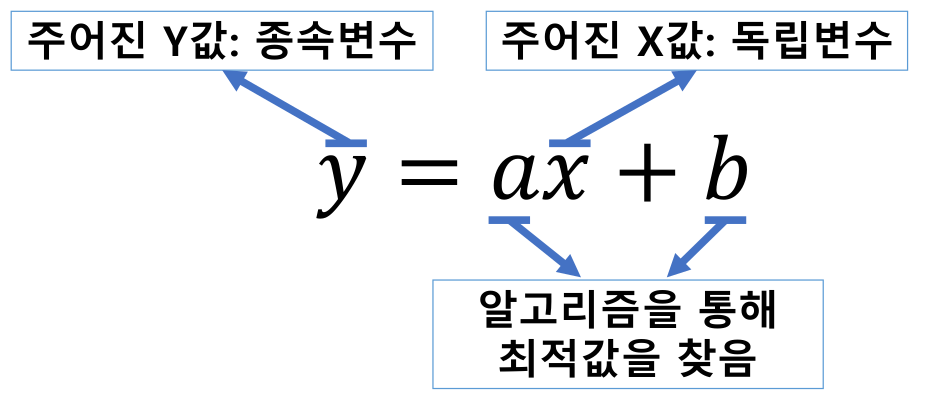
위 선형 회귀 식에서 주어진 값 x를 독립변수, 식을 통해 계산되는 결과 y를 종속변수라고 한다. 그리고 우리는 알고리즘(학습)을 통해 최적의 a, b 값을 찾아야 한다.
y값에 영향을 주는 x값은 하나가 아닐 수 있다. 아니, 하나가 아닌 경우가 훨씬 많다. 유명한 머신러닝 기초 문제로 ‘보스턴 집 값 예측’ 문제가 있다 (사실 지역은 크게 상관 없다). 집 값에 영향을 줄 수 있는 다양한 요소(방의 개수, 범죄율 등)를 입력으로 하여 출력으로 집 값을 예측하는 문제이다.
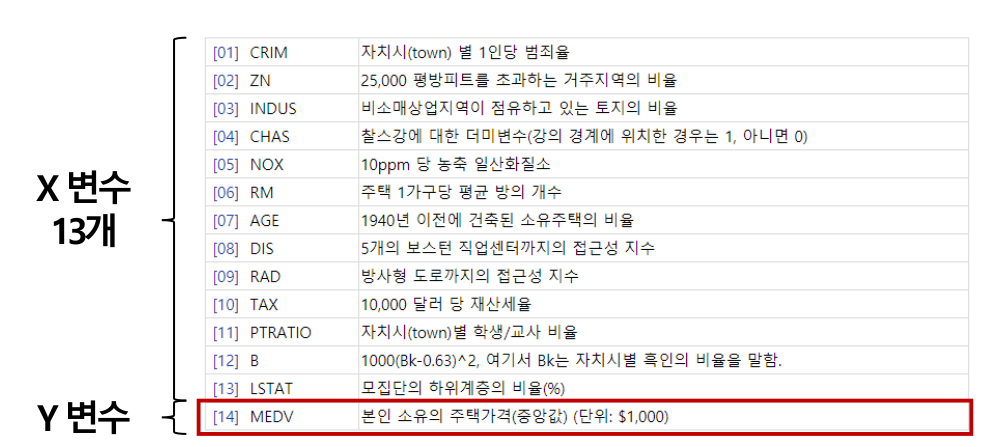
보다시피 아주 많은 독립변수(13개)가 하나의 종속변수를 결정한다. 이를 식으로 나타내면 다음과 같을 것이다.
\[y = \beta_1 x_1 + \beta_2 x_2 + \beta_3 x_3 + \beta_4 x_4 + \beta_5 x_5 + \beta_6 x_6 + \beta_7 x_7 + \beta_8 x_8 \\ + \beta_9 x_9 + \beta_10 x_10 + \beta_11 x_11 + \beta_12 x_12 + \beta_13 x_13 + \beta_0 \cdot 1 + \beta_1 x_1\]$\beta_1$ 은 상수 항이다.
머신러닝에서는 독립변수를 특성(feature)이라고 부른다. 데이터의 특징을 나타내며, 일반적으로 표로 데이터를 표현할 때 열(column)을 의미하기도 한다. 하나의 데이터는 특성 벡터로 표현할 수 있다. 예를 들어, 다음과 같이 표현한다.

선형 회귀 식에서 보았던 계수는 이제 가중치 벡터(w)로 표현한다.
\[\bf{w} = \begin{bmatrix} w_0 \\ w_1 \\ w_2 \\ w_3 \\ \cdots \\ w_{13} \end{bmatrix}\]이제 식을 다시 써보자.
\[\displaystyle y = w_1 x_1 + \dots + w_{13} x_{13} + w_0 x_0 = \sum_{i=0}^{13}{w_i x_i} = \bf{w^T x}\]데이터의 전처리
데이터를 분석하려면 일단 데이터를 불러와야한다. 데이터를 테이블 형식으로 불러왔을 때 기본적인 용어는 다음과 같다.
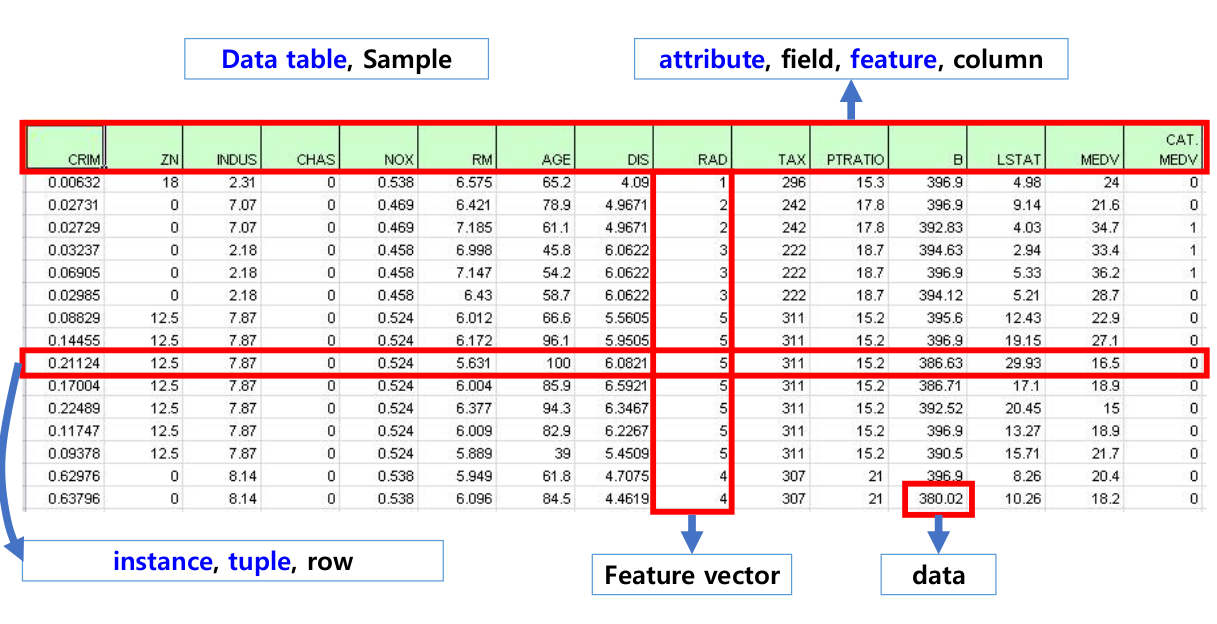
| 용어 | 설명 |
|---|---|
| Data table, Sample | 전체 데이터 |
| attribute, field, feature, column | 독립변수, 특성 |
| instance, tuple, row | 하나의 사례 |
| feature vector | 하나의 특성에 대해 벡터로 표현한 것. |
데이터가 처음부터 분석하기에 완벽하면 좋겠지만 일반적으로는 엉망인 경우가 많다. 어떤 값이 비어있거나, 해당 위치게 걸맞지 않은 경우(예를 들어 숫자여야 하는데 문자인 경우)가 있을 수 있다. 따라서 우리는 pandas를 이용해 데이터를 전처리해주어야 한다.
자세한 방법은 다음 시간부터 배운다.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기