
이번 시간에는 간단한 실습을 통해 list comprehension, 선형 대수가 텍스트 마이닝에서 어떻게 사용되는지를 알아본다.
비슷한 뉴스 선정하기
네이버와 같은 뉴스 사이트를 보면 주제와 내용이 비슷한 뉴스끼리 모아서 보여준다. 이렇게 비슷한 뉴스를 선정하는 프로그램은 어떻게 만들 수 있을까?
일단, 컴퓨터는 문자를 그대로 이해하지 못하기 때문에 문자를 숫자로 바꾸어주어야 한다. 두 문서가 유사하다는 것은 수학적으로는 거리가 가깝다고 이해할 수 있다. 즉, 우리는 문서 거리를 측정해서 문서 사이의 유사도를 판단할 것이다.
문자를 벡터로 바꾸기
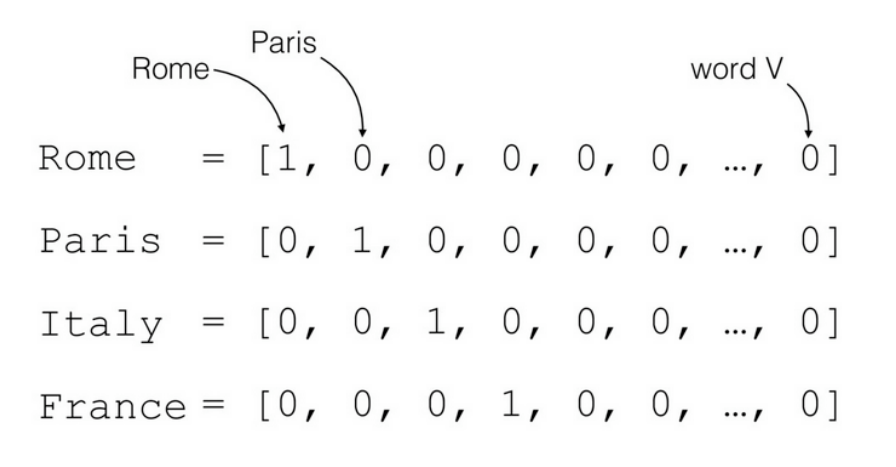
먼저 문자를 벡터로 바꾸어야한다. 한 가지 방법으로 원-핫 인코딩이 있다. 하나의 단어를 벡터의 인덱스로 할당해서, 단어가 존재하면 1, 존재하지 않으면 0으로 표현할 수 있다.
또 다른 방법으로는 bag of words를 사용할 수 있다. 단어별로 인덱스를 부여하는 것은 동일한데, 존재 유무뿐만 아니라 개수를 표현한다는 것이 다르다. 예를 들어 ‘the dog is on the table’의 경우 아래와 같은 벡터로 표현된다.

유사성 측정
유사성은 거리를 이용해서 측정한다고 했다.
가장 보편적인 거리인 유클리디안 거리를 사용하는 방법이 있다. 두 점 사이의 직선 거리를 측정하는 방법이다. 두 점 a, b 사이의 직선 거리는 다음과 같이 정의된다.
\[\displaystyle d(a, b) = \sqrt{\sum_{i}^{n}{(a_i - b_i)^2}}\]그러나 직선 거리는 좋지 않다. 예를 들어 love, hate 두 단어에 대해 (5, 0), (5, 1), (4, 0)인 세 문서가 있다고 해보자. 분명 1번과 3번 문서가 가깝지만, 유클리디안 거리는 세 문서 사이의 거리가 모두 동일하다고 결론을 내린다.
다른 방법으로는 두 점 사이의 각도를 사용하는 방법이 있다. 이 방법이 더 많이 쓰인다. 정의는 다음과 같다.
\[\displaystyle \cos(\theta) = \frac{A \cdot B}{\vert \vert A \vert \vert \, \vert \vert B \vert \vert}\]전략
이번 프로그램을 구현하는 전략은 다음과 같다.
- 파일 불러오기
- 파일을 읽어서 단어사전(corpus) 만들기
- 단어별로 인덱스 만들기
- 만들어진 인덱스로 문서별 bag of words 생성
- 비교하고자 하는 문서 비교
- 성능 평가
몇 가지 추가 설명을 하자면, 파일명은 ‘숫자_제목’ 형태로 되어 있다. 숫자의 경우 1, 2, 3, 4는 야구, 5, 6, 7, 8은 축구 기사이다.
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기