
이번 시간에는 비행기 승객 데이터를 이용해서 시계열 데이터를 다루는 실습을 진행한다.
시계열 데이터 - 행을 거치면서 업데이트
‘AirPassengers.csv’ 파일은 다음과 같이 생겼다.
df_time_series = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/AirPassengers.csv")
df_time_series.head()
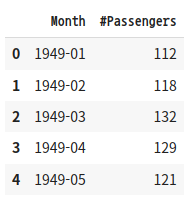
행을 거치면서 최댓값 혹은 최솟값을 업데이트 하고 싶을 수 있다. 그 때는 다음과 같이 한다.
df_time_series["step"] = range(len(df_time_series))
df_time_series["cum_pass"] = df_time_series["#Passengers"].cumsum()
df_time_series["cum_max"] = df_time_series["#Passengers"].cummax()
df_time_series['cum_min'] = df_time_series['#Passengers'].cummin()
df_time_series.head()
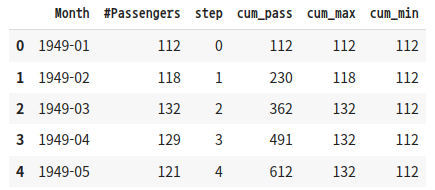
스텝에 따라 승객 수의 합, 최댓값, 최솟값이 업데이트되는 것을 확인할 수 있다.
시계열 데이터 - 문자 데이터를 날짜 데이터로
‘AirPassengers.csv’는 날짜 데이터가 문자로 들어가 있다. 당연히 이를 날짜 형식으로 변환해야 다루기 쉬울 것이다.
여기서는 다음과 같은 순서로 이를 해결할 것이다.
- ”-“를 기준으로 Month열의 문자를 분리해서 리스트로 변환.
- 인덱스 0은 연도, 인덱스 1은 월로 할당.
- 새로운 column을 생성
가장 먼저 1번을 처리한다. 람다 함수를 사용하면 간편하다.
temp_date = df_time_series["Month"].map(lambda x:x.split("-"))
np_date = np.array(temp_date.values.tolist())
다음으로 2번을 진행한다.
year = np_date[:,0]
month = np_date[:,1]
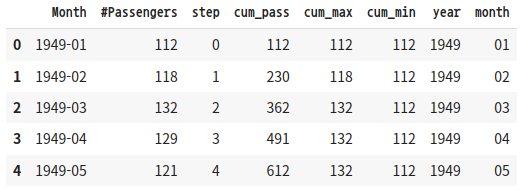
새로운 column을 생성한 결과는 다음과 같다.
df_time_series["year"] = year
df_time_series["month"] = month
df_time_series.head()
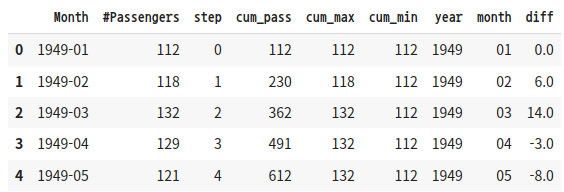
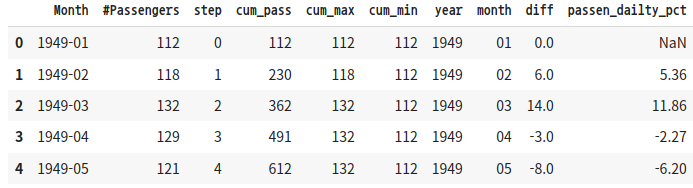
시계열 데이터 - 이전 행과의 차이 구하기
이전 행의 값과 차이를 구할 때는 diff()를 사용한다. 예를 들어, 이전 행과의 승객 수 차이를 구할 때는 다음과 같이 한다.
df_time_series['diff'] = df_time_series['#Passengers'].diff().fillna(0)
df_time_series.head()
백분율로 증감을 알고 싶을 때는 pct_change()를 사용한다.
df_time_series["passen_dailty_pct"] = df_time_series["#Passengers"].pct_change().map(lambda x:x*100).map(lambda x:round(x,2))
df_time_series.head()
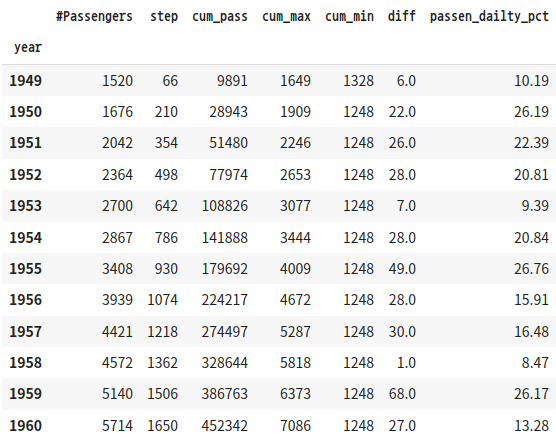
연도 별로 묶어서 합을 구하자.
df_time_series.groupby("year").sum()
별도의 출처 표시가 있는 이미지를 제외한 모든 이미지는 강의자료에서 발췌하였음을 밝힙니다.
댓글남기기